


(Note: this is part 1. See also part 2 of this blog as well as the Siren 10.1 announcement)
We’re very excited to announce that today we’re making available Siren 10. Yes, we skipped a few numbers, let’s see why.
What’s new in Siren 10? Part 1
Multiple back-end support, no ETL needed
Chances are not all your useful data is in Elasticsearch. The good news is that Siren 10 introduces the ability to work with data where it is already inside your organization. No ETL needed!
The Siren Federate layer can now map JDBC datasources as “Virtual Indexes”, which can be visualized and relationally analyzed exactly as it was previously possible with Elasticsearch only data.
You can, for example:
- Start from a Dashboard containing “Reviews” and do a full text search query (data on Elasticsearch)
- …relationally pivot to the list of items that were purchased (data on Oracle DB)
- … to then see which stores (locations) were involved (this time data is on Cloudera Impala – complex architecture indeed!)
- … and so on. Also in link analysis mode
All seamlessly, without the analyst having to worry about where the data is, with “relational filtering” buttons automatically generated by the underlying ontology (data model) connecting your records across indexes and across systems. In a picture:

Analytics and Join pushdown: your Big Data infrastructure at work
Siren federation technology makes full use of your existing DBs and Big Data infrastructure with the ability to translate analytic and join queries to the language supported by your existing DB or Big Data infrastructure and (transparently) resorting to in-Siren-cluster-nodes memory joins just as a very last resource.
This means that for most analysis the performance and scalability will be as good as your Native SQL system.
Backends supported out of the box in include:
- PostgreSQL
- MySQL
- Microsoft SQL Server 2017
- Sybase ASE 15.7+
- Oracle 12c+
- Presto
- Spark SQL 2.2+
- Impala
- Dremio
Need more? Let us know.
Fully distributed in-cluster Elasticsearch joins: double the nodes, double the performance
With the new Siren Federate fully cluster distributed Elasticsearch join technology performance now scales with the size of the cluster. Implementing some of the most advanced and recent distributed computation algorithms, Siren Federate reaches a whopping 90% average efficiency in hardware usage as your cluster scales either in nodes but even in number of CPUs per node.
The following picture, from a forthcoming blog post specifically on this, summarizes the results of our join benchmark as the Elasticsearch cluster scales in nodes and cores (600M id join).
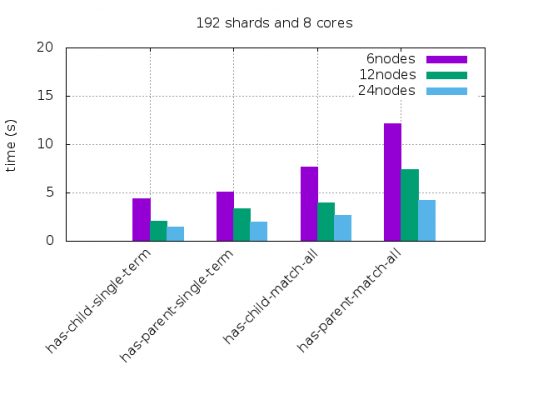
Note that the Siren Federate distributed technology will also be made available as a standalone Elasticsearch plugin for use in your applications.
Improved relational model: OWL and Entity Identifiers
Siren now let users edit what is an OWL ontology to describe data links (a bit of theory 🙂 )
Making Siren we’ve always been quite aware of data graph formats like RDF, and the OWL dictionary to represent Data Models (called Ontologies when they also include more advanced restrictions in the class relationships).
This said, the Siren Platform stays very clear from asking anyone to convert their data into RDF and, instead, simply provides a layer where the relationships between your existing indexes (anything that you connect to Federate, so from DBs to indexes in Elasticsearch) are stored and coordinates the joins and analytic queries on your data in the format that it already has.
On the other hand, if instead of using RDF/OWL as a “record/field” format we simply use it to describe the relationships between your existing data then it makes a lot of sense and Siren 10 does this (under the hood) as it allows the users to define their data model using (internally) the OWL language (side bonuses: you can also then edit it with tools outside Siren, it’s easy to convert other data models into a well-known format, etc).
What’s new in practice
The first thing is that the new data model introduces the concept of “Entity Identifier” (EID).
Previously, in Siren, to be able to join between two indexes you had to specify that there existed a direct connection between them. E.g. if you had 2 logs which could be connected by the IP value, you would have specified a direct connection, thus creating a relational button between the two.
But what if you have many indexes having IPs (or anything else: MAC Addresses, UserIDs, URLs, Port Numbers, Transaction IDs, etc) that are in multiple roles (Source IP, Destination IP) and it might be useful to join from any of these roles and indexes to any other role and index?
Our new relational model allows this. Automatically.
For example, in this configuration, we have defined the IP concept as an EID and tied it in with other indexes where “IPs” show up. For each connection we specify the name of the relation that is what is the role of the IP in that index (is it the “source” IP in that log or the “blocked” IP?)
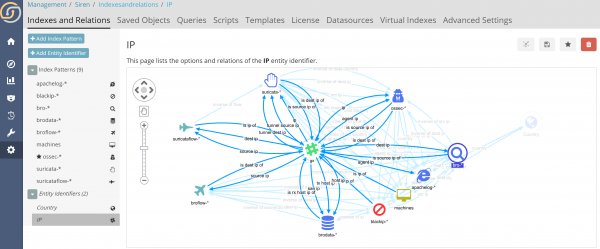
Just with this configuration, you can now have buttons that explore the ontology and show you all possible matches across your data. At this point, one click and you’ll be pivoting to the target dashboard, with the right relational filter applied.
For example, to go see the records of the Apache logs where the Agent IP matches the Destination IP in the current log, just navigate from “Destination IP” as per picture:
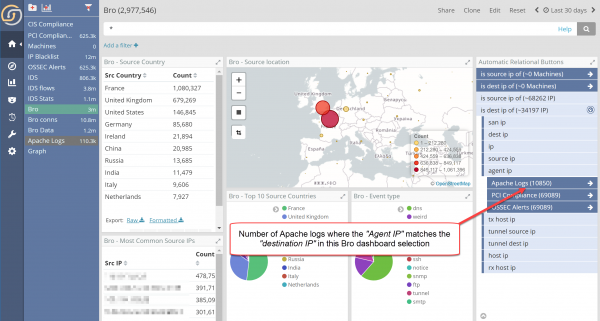
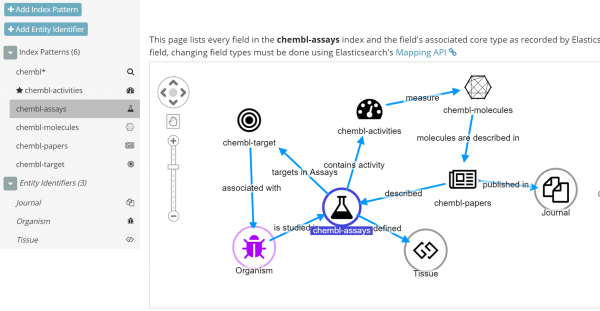
EIDs are obviously great for anything that identifies “things” across indexes but does not have an index per se (otherwise you’d pivot to it). Things like Phone Numbers, but also Tags, Labels from standalone indexes, etc. In practice a single excel spreadsheet can be seen as a “knowledge graph” if you consider labels as identifiers that interconnect records. Here is an example with EIDs (Tissue and Organism) in a Life Science deployment.
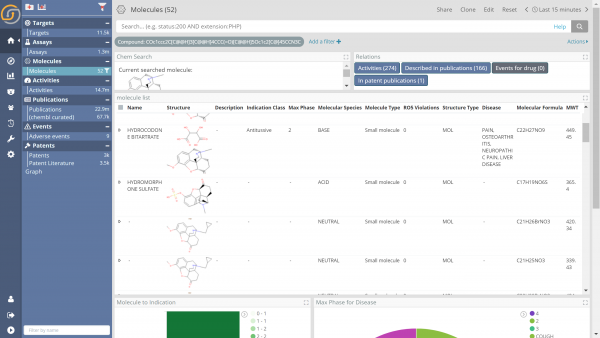
Molecular Search (Siren Life Sciences edition)
High performance molecular search with UI tunable tolerance
Siren is terribly exciting when it comes to browsing complex interconnected data sets. The very nature of the Elasticsearch search engine makes it ideal to flexibly search across data also using fuzzy criteria, assuming that the proper transformation procedures are in place.
Siren life science edition now includes backend/frontend component to allow fast and accurate searches of molecules starting from their structure or part of structure.
What else is in Siren 10?
.. see part 2 of this blog. (and also our blog on Siren 10.1)
Where to find it?
Get Siren 10 on our support portal.















