Siren Federate empowers analysts, investigators and data professionals with advanced relational search, graph search, and information retrieval capabilities. By combining powerful Elasticsearch search capabilities with proprietary advanced join techniques, Siren enables seamless correlation across multiple distributed data sources within Elasticsearch, unlocking deeper insights and more effective investigations.


Apollo.io, a leading B2B sales intelligence platform, faced significant challenges with their search functionality, particularly when dealing with their two core data models: contacts and accounts. The platform maintained a synchronization system where account information was replicated to contact records to enable faster querying. However, this approach began to show its limitations, especially when handling accounts with large numbers of contacts and frequently changing fields.


Enabling real-time linking and querying across distributed data.
Navigate complex relationships across structured and unstructured data.
Quickly find and connect relevant data points for enhanced decision-making.

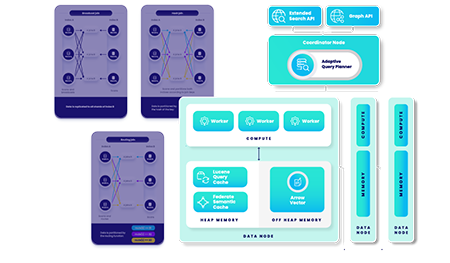
Siren Federate enhances Elasticsearch with complex join operations and powerful data-linking capabilities, allowing seamless data correlation across multiple indices. This is crucial for investigative workflows, cyber threat intelligence, and financial crime analysis.

Unify diverse data sources and perform relational searches to reveal hidden connections. Siren Federate’s technology ensures that disparate data can be queried efficiently without compromising performance.

Graph-based investigations allow users to visualize relationships between entities, uncovering patterns and anomalies that traditional keyword searches might miss.

Siren Federate enables complex Elasticsearch joins and other powerful linking capabilities, allowing seamless data unification across multiple indices. This is crucial for investigative workflows, cyber threat intelligence, and financial crime analysis.
• Identify connections between suspects, events and digital footprints.
• Analyze financial transactions and communications across various sources.
• Detect malicious activities by correlating threat intelligence feeds with internal logs.
• Investigate security breaches by linking network, endpoint, and threat actor data.
• Conduct due diligence and fraud investigations.
• Ensure regulatory compliance to large-scale searches through interlinked documents.

Chief Operating Officer at Apollo.io
This was such a beastly performance improvement. The impact on our customers was immediate. Our products are now faster. Customers can use Apollo products in even more precise ways to filter and target, allowing sales and marketing teams to have unparalleled results.

Senior Engineering Manager at Apollo.io
Success looks like scaling for billion of records across an Elastic Cluster while maintaining speed and reliability.

Co-Founder and Chief Scientific Officer of Siren
Siren Federate was designed to handle mission critical, large-scale searches and the Apollo performance validates our approach.




