

(Updated May 24th, 2018)
We are excited to announce today the availability of Siren 10.
We have already previously discussed some of the new features that are part of Siren 10, amongst which are:
- Direct operations on SQL backends with join and analytic push down to the back systems and cross-system joins.
- Distributed joins in Elasticsearch.
- Smarter data model with automatic joins buttons appearing on each dashboard.
- Chemical structure search – life science edition.
For more details, see our Siren 10 part 1 (Beta) blog post.
What’s new in Siren 10?
Today’s version incorporates the feedback received in the beta period, has the expected bug fixes and general improvements but more importantly also activates some new features which enhance the overall user experience such as:
Main enhancements: graph selection, lens panel and graph lenses
The graph browser component now comes with a side panel which can be opened and resized. The panel currently has 2 tabs: “Selection” and “Lenses”.
The “Selection tab” in action
Starting from selection, you can now see a compact representation of the data currently selected. You can then browse through the underlying data and gain immediate insights about your current selection.
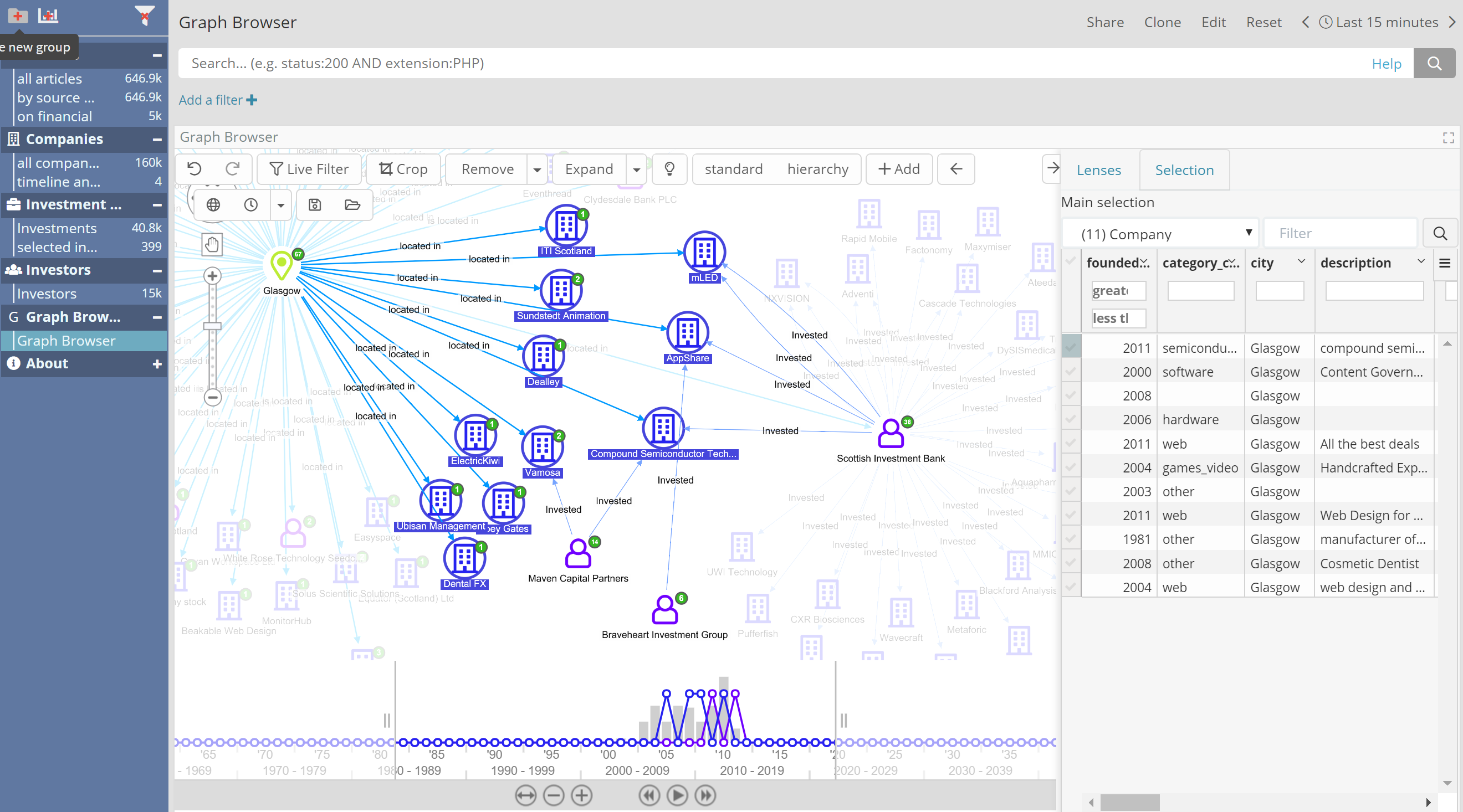
Beyond providing data visibility, this added panel also allows for the following:
- Quick restriction of selection via full-text and search max/min restrictions
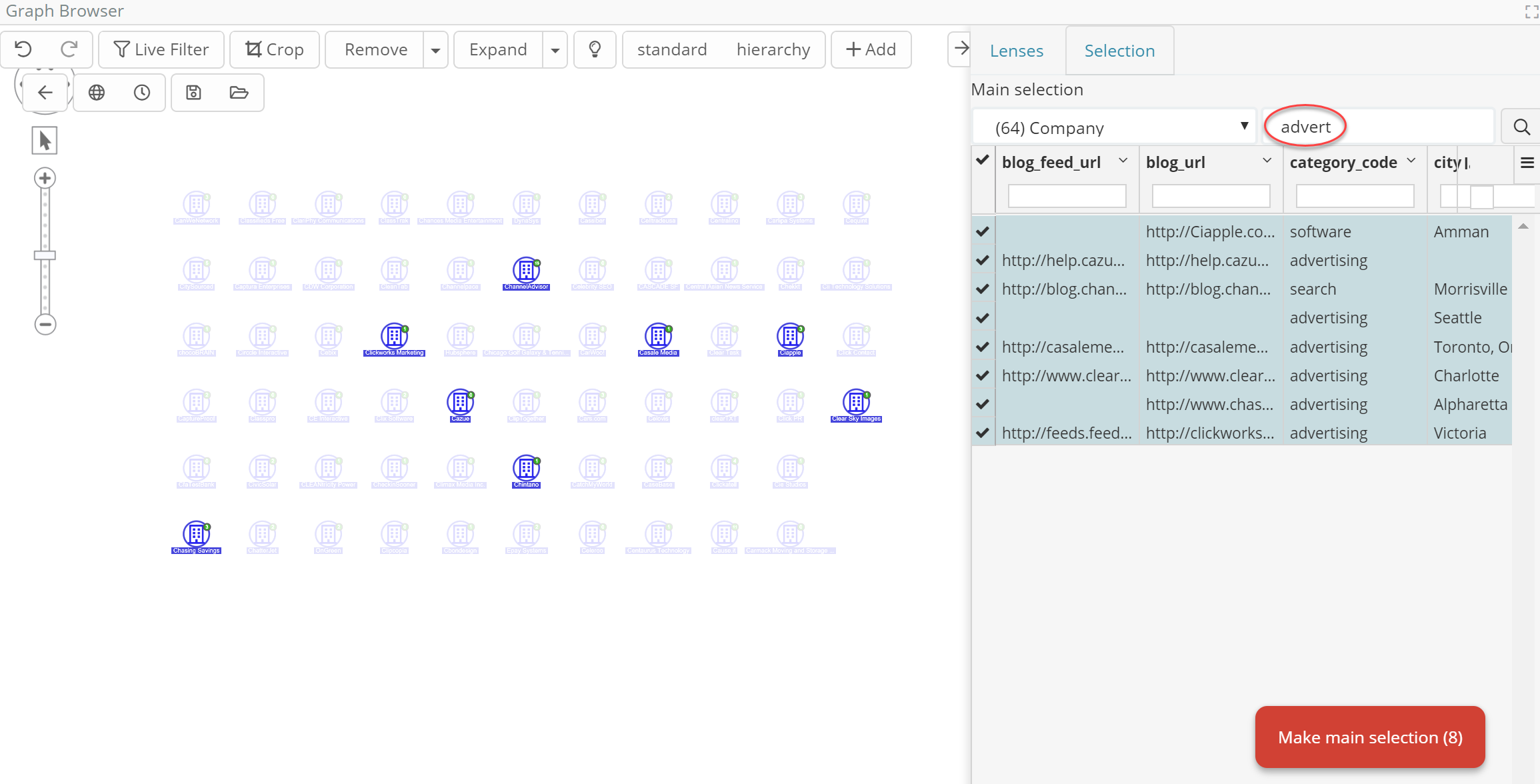
- Ordering of entities by any field, and subsequent sub-selection via manual picking (check boxes) (for example, top 5)
- Previews of larger fields content
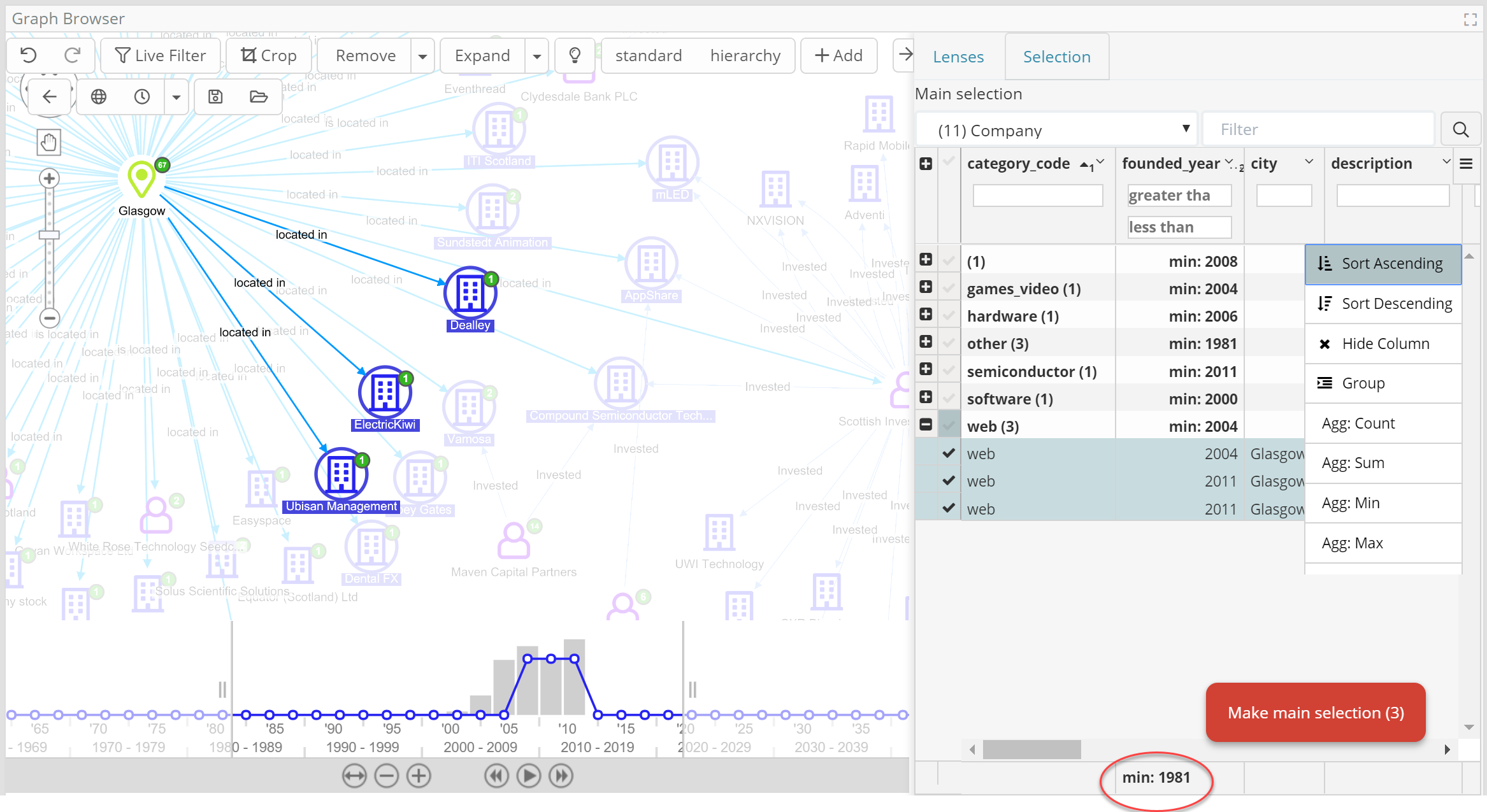
- Grouping entities via common metadata properties (e.g., Year or Round of Founding), roll-ups (max, min, average, counts), sub-selection by group.
Welcome graph lenses: insights at a glance
Lenses are a new paradigm for operators which visually transform the graph and can be cascaded providing instant visual insights based on the underlying data.
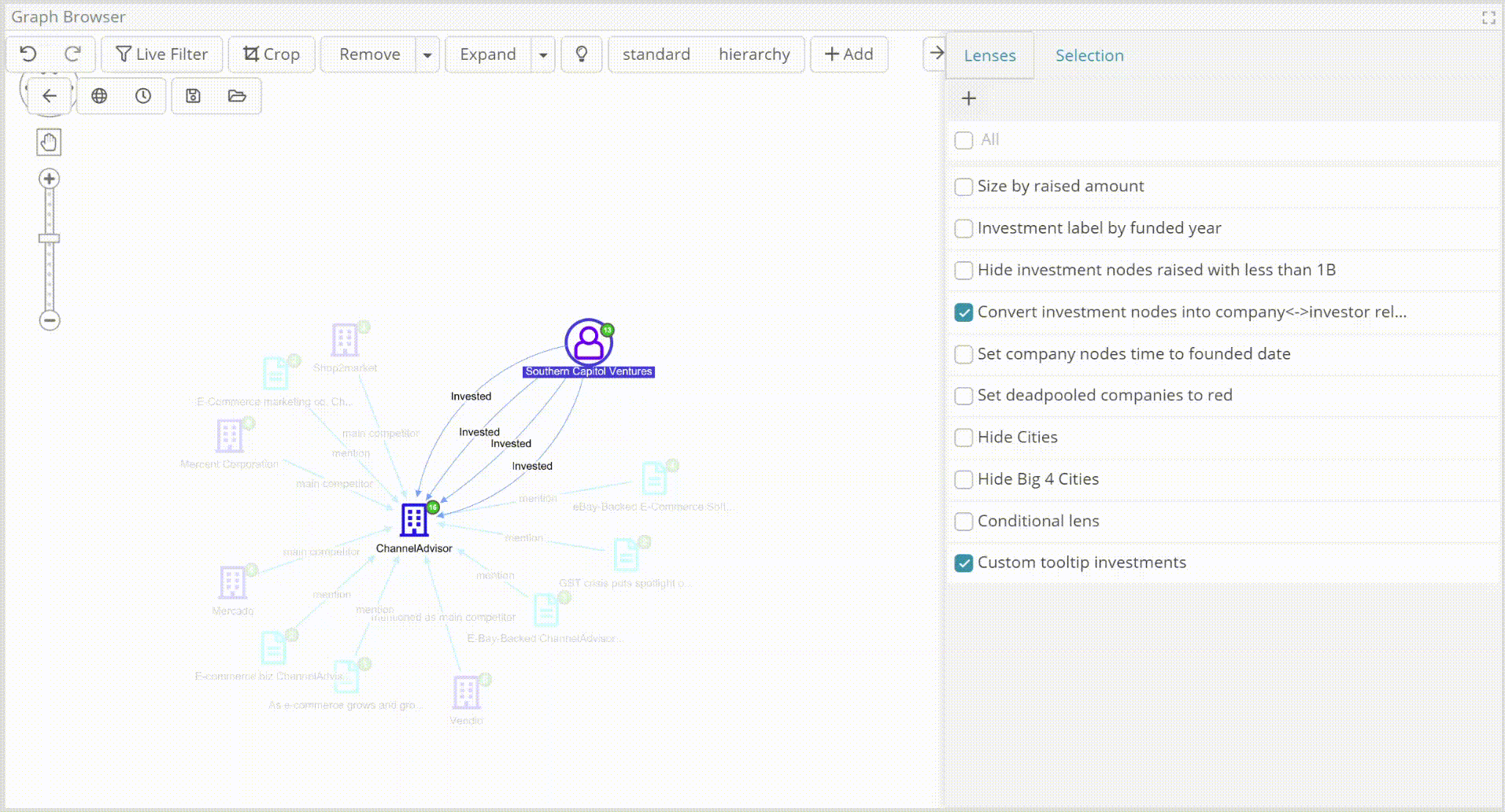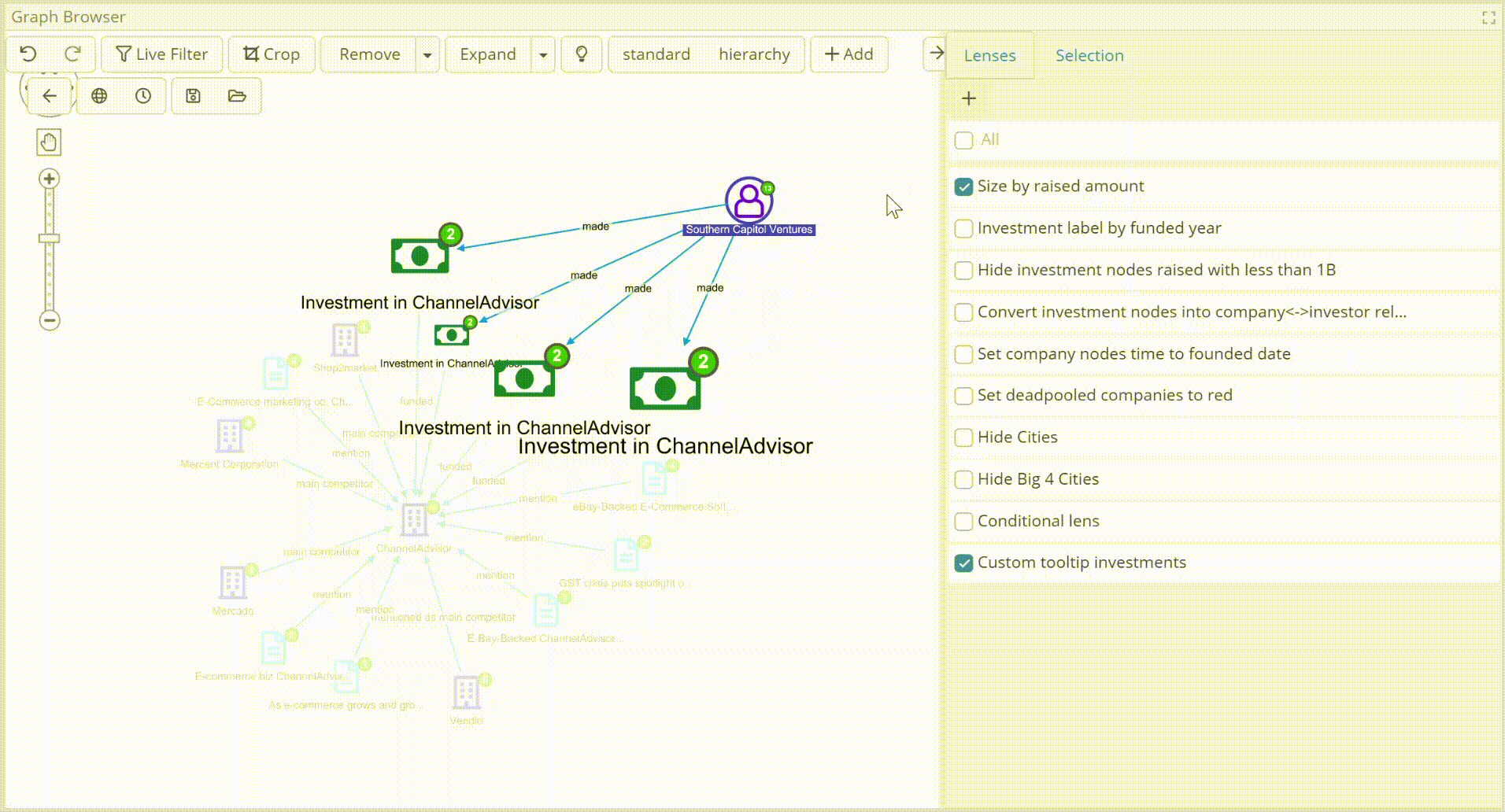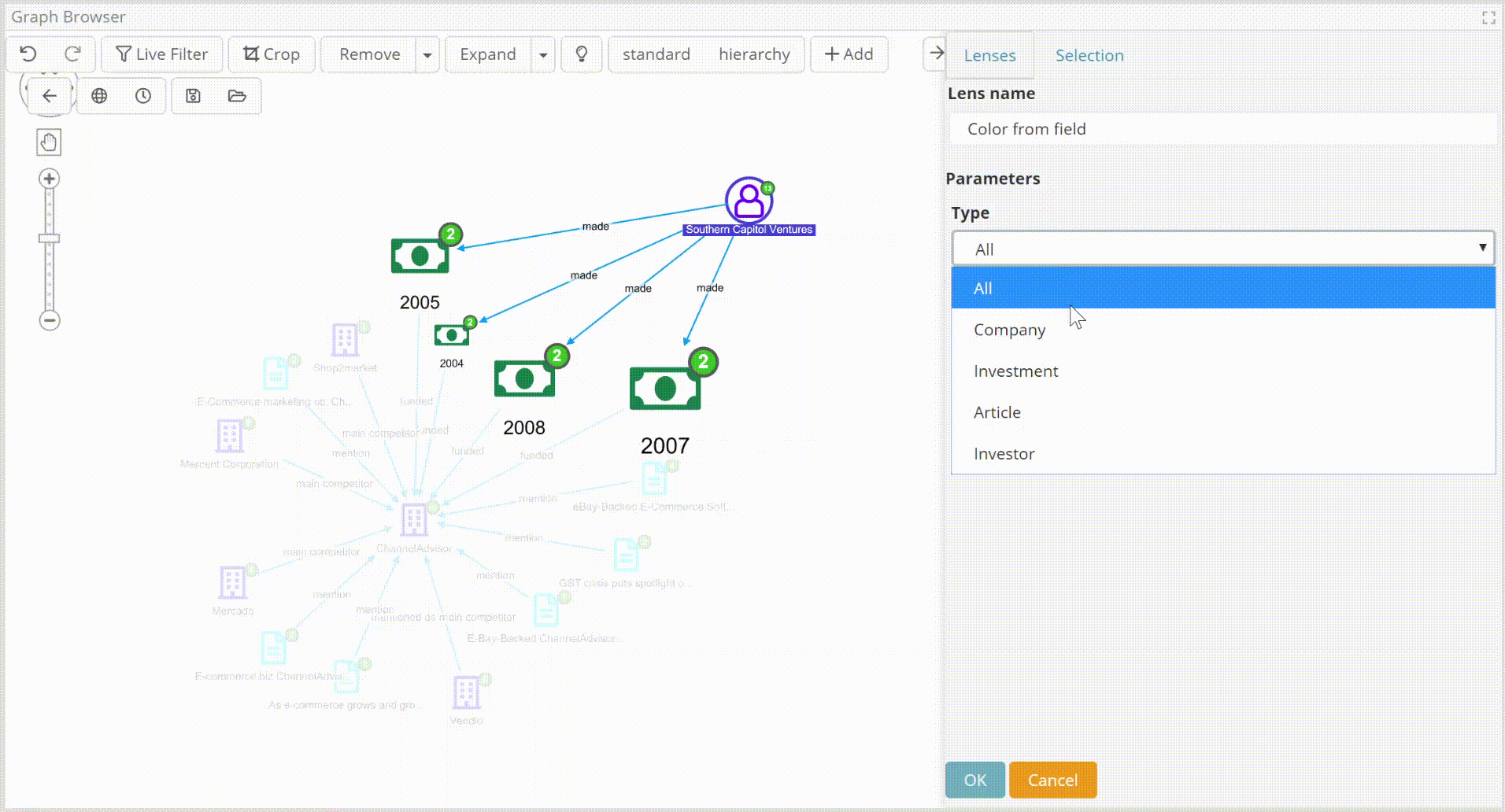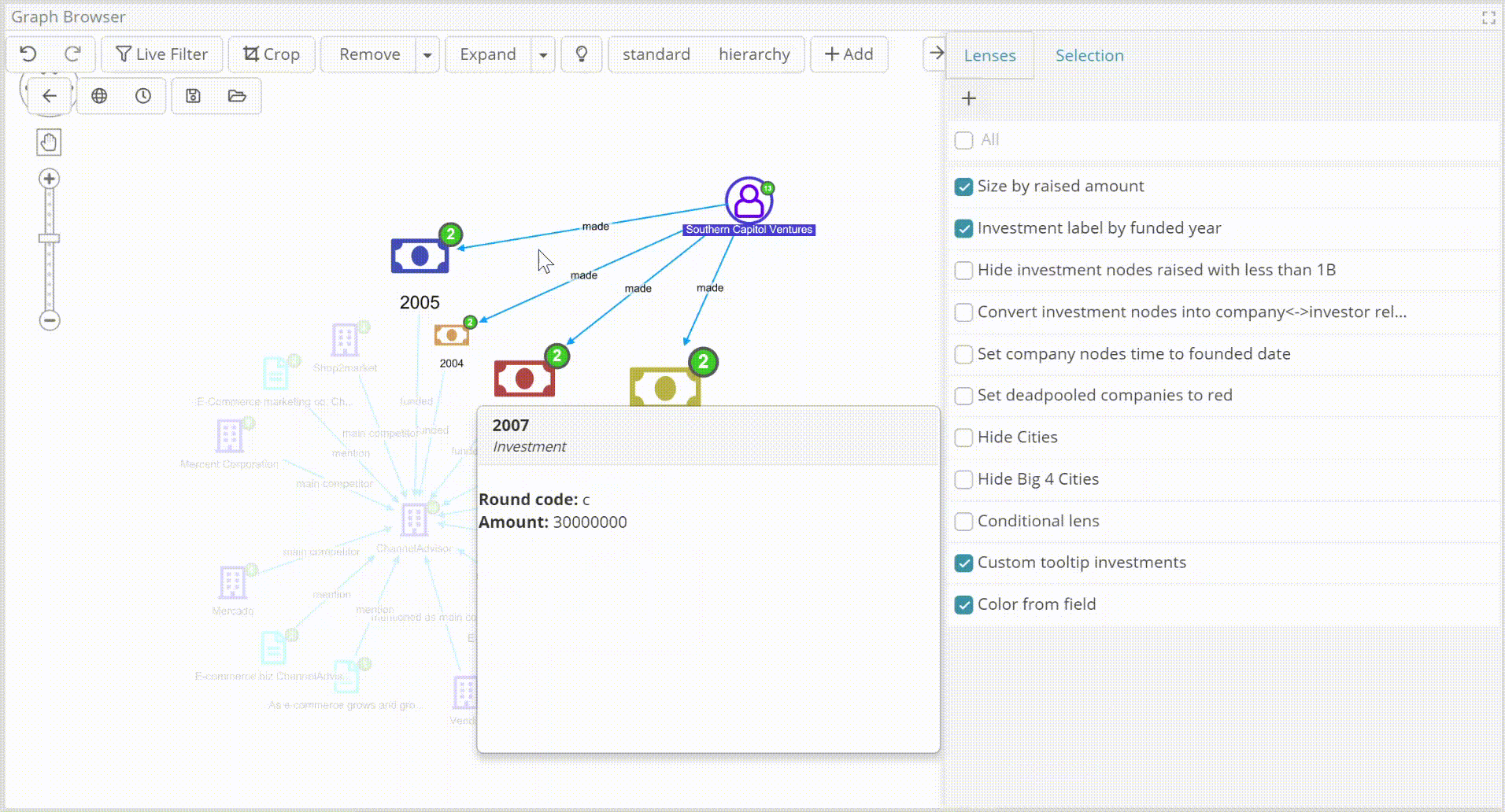
For example, in the following image, a round A investment (that didn’t succeed as planned, see connected news article) stands out in the portfolio of an investor. Size is proportional to the square root of the money (edited with a formula) while colors indicate the funding round label (E.g. Seed, Round A etc)
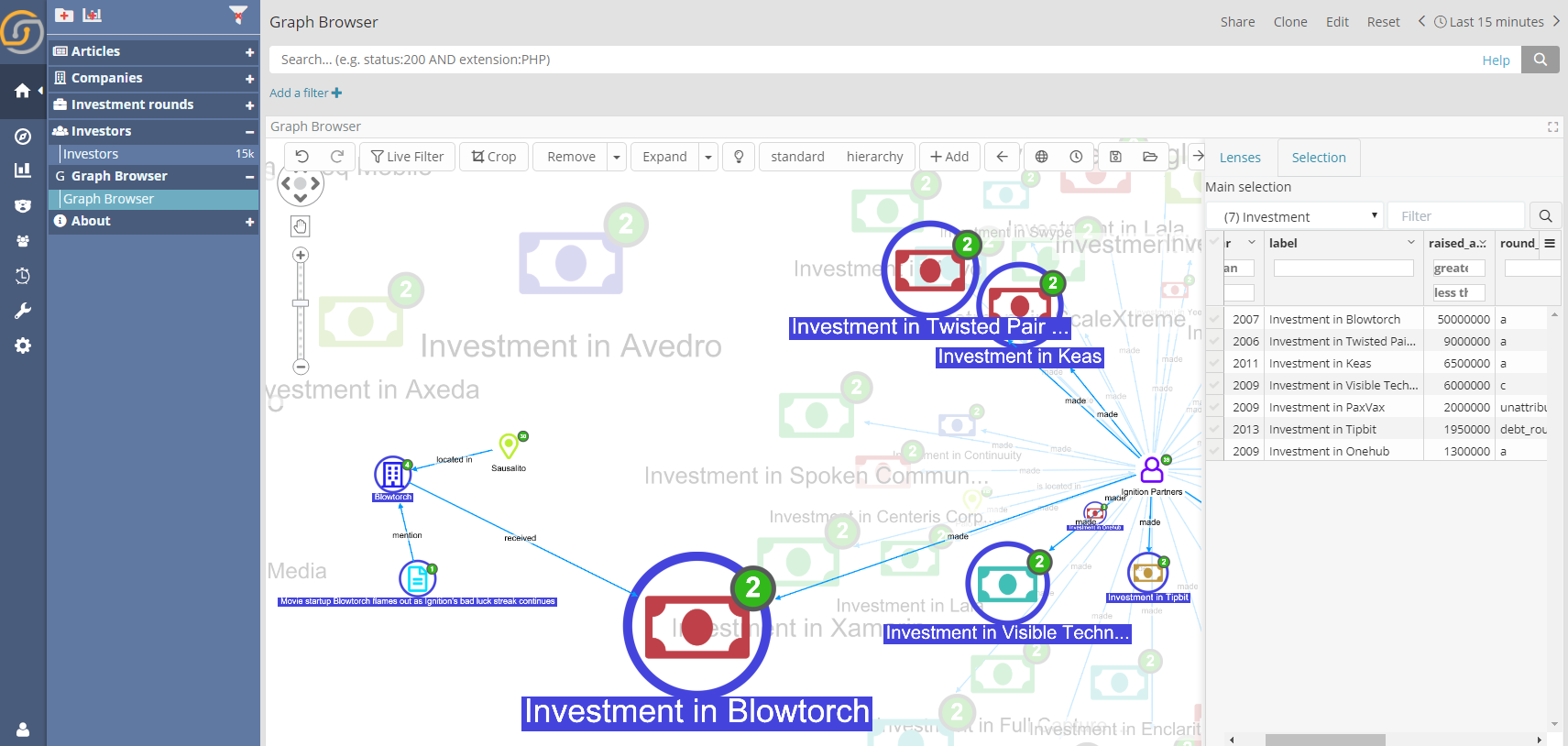
Importantly, lenses can be created and configured via UI by the end user, as well as turned on and off on the fly for comparative analysis.
Among the capabilities of the ‘lenses’ feature are:
- Availability to change node colors and other attributes – size, label, decoration glyphs, node image (mugshot!) – based on expression (including conditionals) which use nodes values.
- Availability to change node visibility based on conditions which is great for blacklists (such as annoying nodes, e.g., “Palo Alto/San Francisco” – way too many startups connect there) or to dynamically show hide based on properties (e.g., hide investments less than X).
- Availability to set time and geographical properties, to be used in the graph timeline and map capabilities.
- Availability to set customized on hoover hints (e.g., for great visualization of the most important properties).
- Availability to transform nodes into edges based on the ontology.
A few of these features demonstrated together:
More interestingly though, is that lenses are examples of Scripts that Siren supports. Scripts can be developed in JavaScript to provide domain-specific functionalities – also enabling real-time queries to backend data and services.
It would be possible, in an IT Infrastructure Management or Cyber Security use case for example, for a script to change the color or make a “red dot” blink on the node of a server which has been at over 90% CPU for the last 30 minutes or which appears to be currently under attack according to logs in the system. (Watch this space for more examples)
High availability alerting: fail safe and scalable alerting
Siren Alert (previously Sentinl) can now be executed in high availability mode. If one of the alerting nodes fails, others will take over so alerts are not lost. Coherently with Siren Federate capabilities, Siren Alert can generate alarms based on queries which cross Elasticsearch as well as DBs or any other JDBC source, even cross-system joins.
Free text queries on SQL federated dashboards
Free text queries from the query input text box can now be answered also on directly SQL mapped (federated) dashboards, thanks to the UI allowing one to decide which fields are going to be used in SQL LIKE queries used for this operations. Coming shortly: native support for inverted index capabilities in supported SQL RDBMS.
Hitting the ground running: automatic “notable field” selection and automatic initial dashboard creation
How do you quickly get started on a new table or data set?
As simple as this:
- press the “autoselect fields” after adding the new table
- enjoy the “auto dashboard” which is a good way to get started.
see in action:
Others notable new features
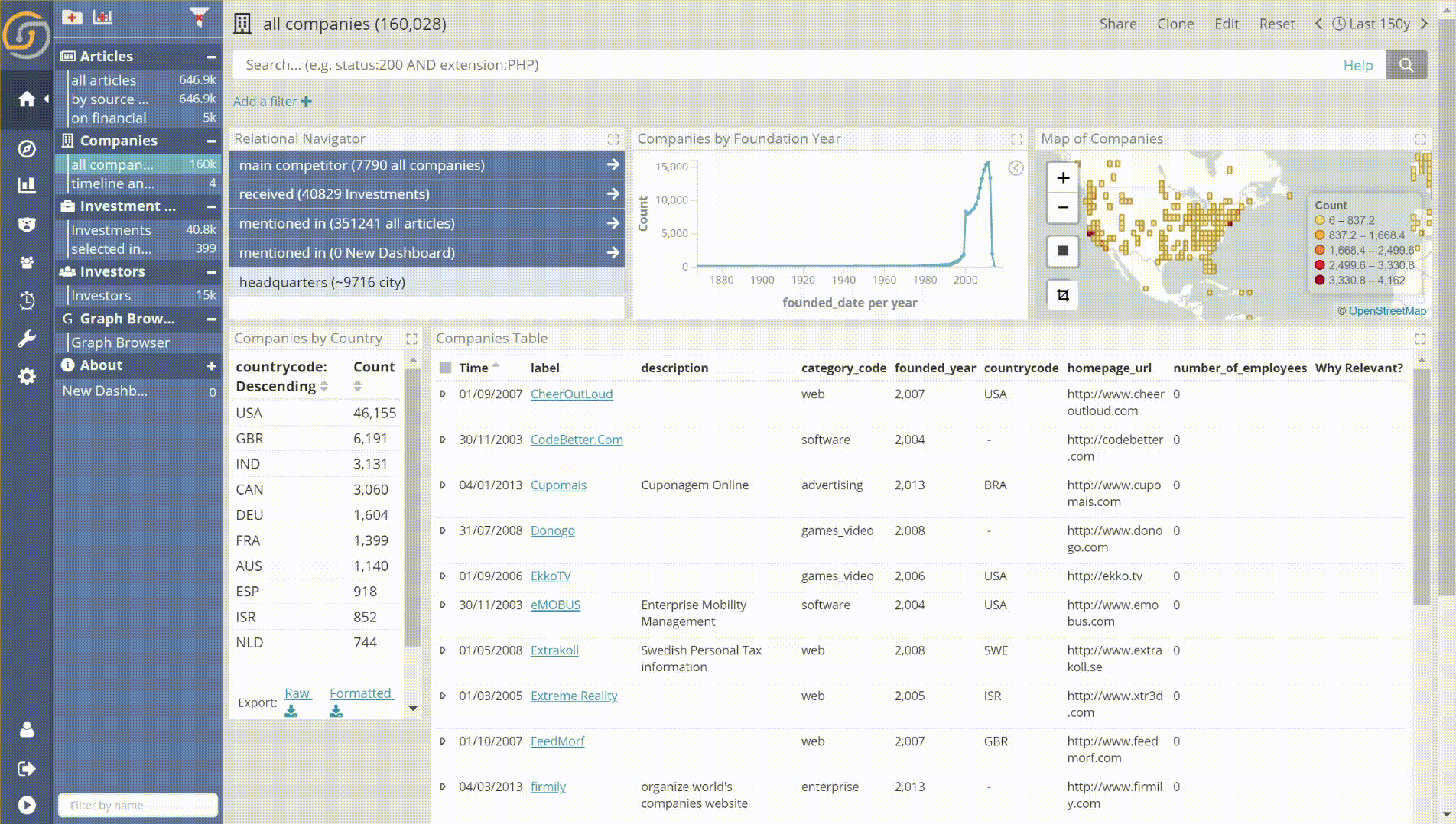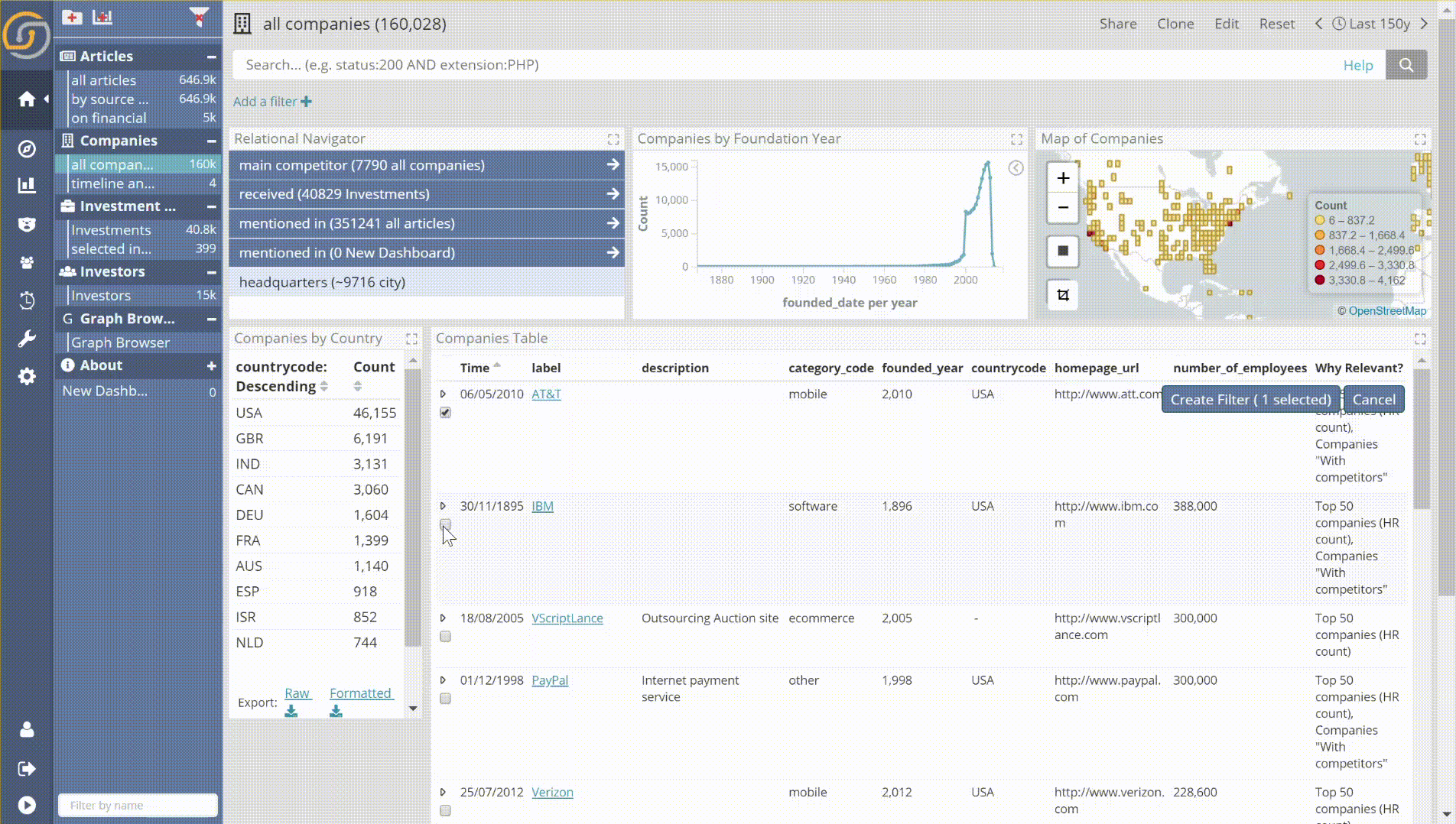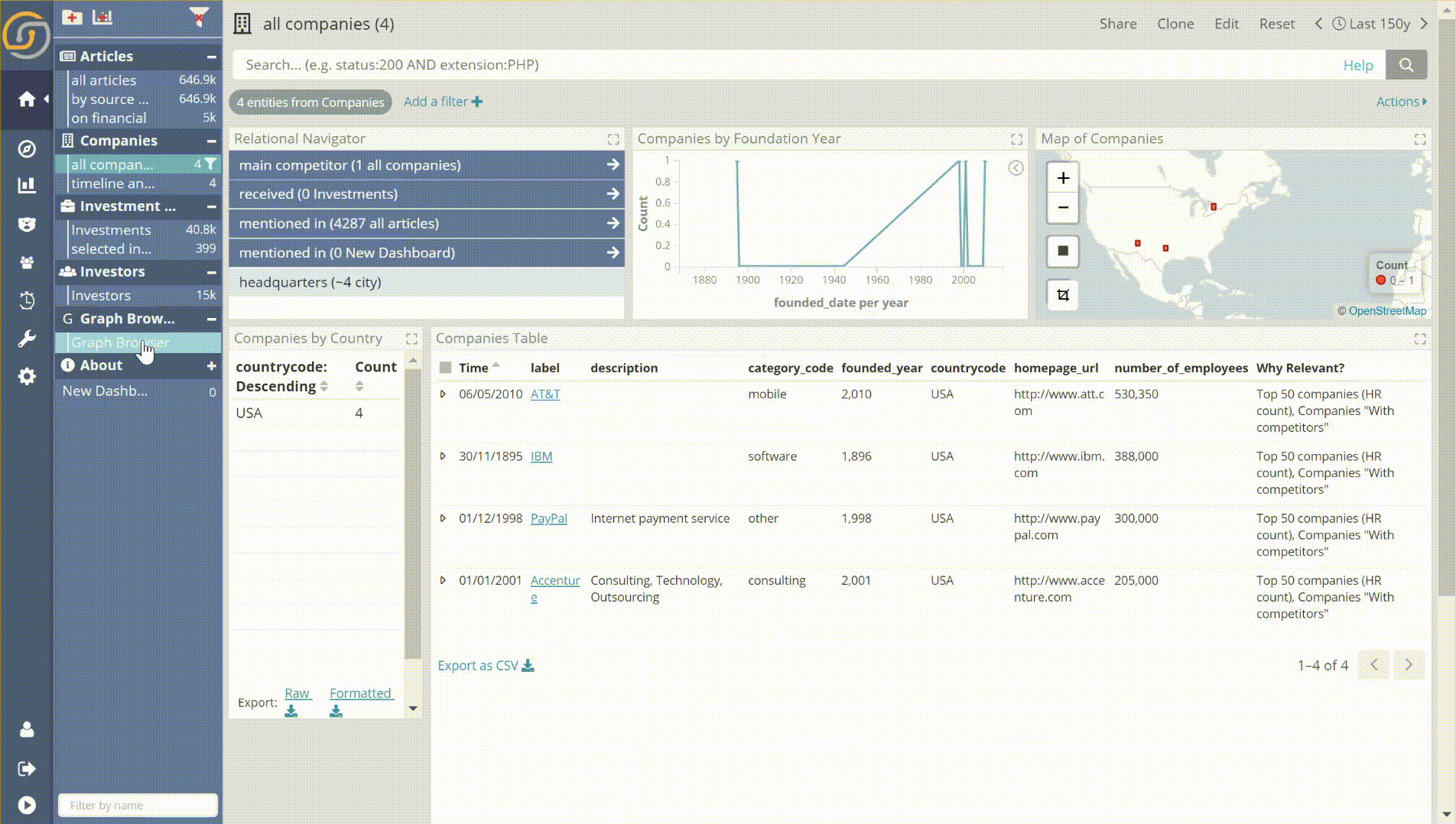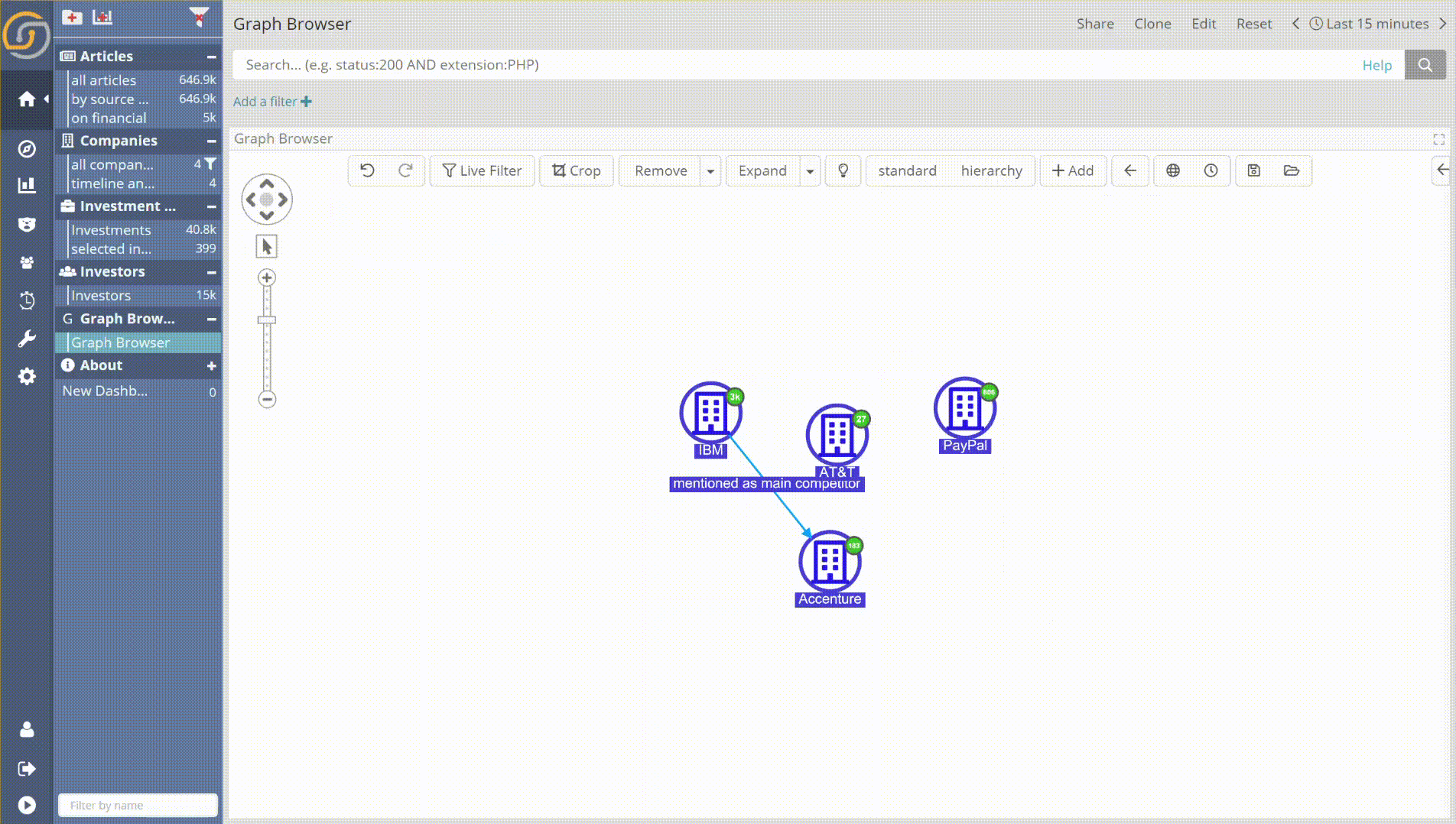
- Individual record/entity selection. For example, in the following animation, a user selects by enumeration some of the largest companies in the DB. He firstly orders the records by Number of Employees and then applies the individual record/entity selection feature. As a result, one now has easier control over the records that are selected.
- Improved handling of very large nodes. You will get informed when you are about to do major expansions, enabling the user to decide what to do next.
- Ability to add Entity Identifiers nodes to the graph (e.g. just paste IPs and see if they’re connected to anything).
- ..and more, see full list.
What’s coming next in Siren Investigate
Siren 10.0 incorporates further fixes and minor enhancements and is expected within 2-3 weeks.
Following that, features that will be following shortly thereafter (10.1 & 10.2) include:
Big Data aggregations on graph edges. Millions of logs summarized instantaneously on the graph browser, with automatic detection of all possible fast aggregations across indexes.
Elasticsearch 6 compatibility. Compatibility upgrade for version 6 of the Elasticsearch stack.
Optional ingestion into Siren/Elasticsearch nodes Highly sought after ability to “reflect” (on demand) the content of a remote JDBC store in Siren nodes, boosting search capabilities and performance all around.
Many more connectors from MongoDB to Cassandra, the above Data Ingestion API makes it easy to analyze other NoSQL stores.
Solr compatibility. Siren will be able to natively connect to Solr (including older version 4). This coupled with the already existing Impala JDBC drivers makes Siren a unique instrument to search and investigate Cloudera Data Lakes.
The bottom line
Enterprise Federated Search, Business Intelligence dashboards, Link Analysis are all highly appreciated functionalities for investigators. Individual functionalities, however, mean very little if they are not coherently integrated.
Thanks to its ontological backbone, Siren 10 embodies the essence of “Investigative Intelligence”: the individual functionalities are self-configured based on the data and provide value continuously and seamlessly to investigators as they operate.
Siren 10 Federation capabilities, furthermore, fundamentally lowers the barrier to entry for organizations to see their complete “knowledge graph”. With no need to copy data out of the systems where it currently resides, Siren 10 provides insights by enabling search, analysis and connecting the dots between records unobtrusively to the way organizations currently operate.
Where to get Siren 10?
Get Siren 10 on our support portal.















