

Siren 10.2 released — free community edition, simplified data ingestion & extraction, Neo4j support & more
We announce today the availability of Siren 10.2. We’re very excited about this release for many reasons. Let’s go in order.
Siren 10.2 addresses the following challenges with several new features:
- Ease of accessing and using Siren — via the new Siren Community Edition
- Ease of using new data sets with Siren — via the new data reflection capabilities
- Ease of sharing and collaborating on investigation insights — via the new exports in (CSV, PDF, PNG)
- Ease of leveraging existing Graph DB investments — now with our first Siren Neo4j driver
Introducing Siren Community Edition, our free entry tier
Since the start, Siren’s industry unique relational investigation capabilities have been widely appealing to the analyst community at large, but always required loading data into Elasticsearch or DBMS in order to analyze it.
With 10.2 we’re now introducing UI assisted ways to load data (e.g. from CSV/Excel see below) effectively making much easier to use Siren also for an individual analyst or a casual project.
This is the perfect occasion for us to introduce our new entry tier level: Siren Community Edition™!
Siren Community Edition™ is fully featured, subject only to quantitative limitations, and can be easily upgraded to our Siren IT and Siren Business editions.
Siren Community Edition represents a fundamental milestone for us, for the first time making world class link analysis and our unique relational investigation capabilities available to individuals and casual projects.
Making data loading easy: no-size-limit CSV and Excel Imports
Siren 10.2 introduces big scale, UI driven CSV and Excel uploads.
The feature is provided as part of the new “Data Reflection” app dedicated to data sources and data loading. It starts with a first step which is as easy as dragging and dropping a local file.
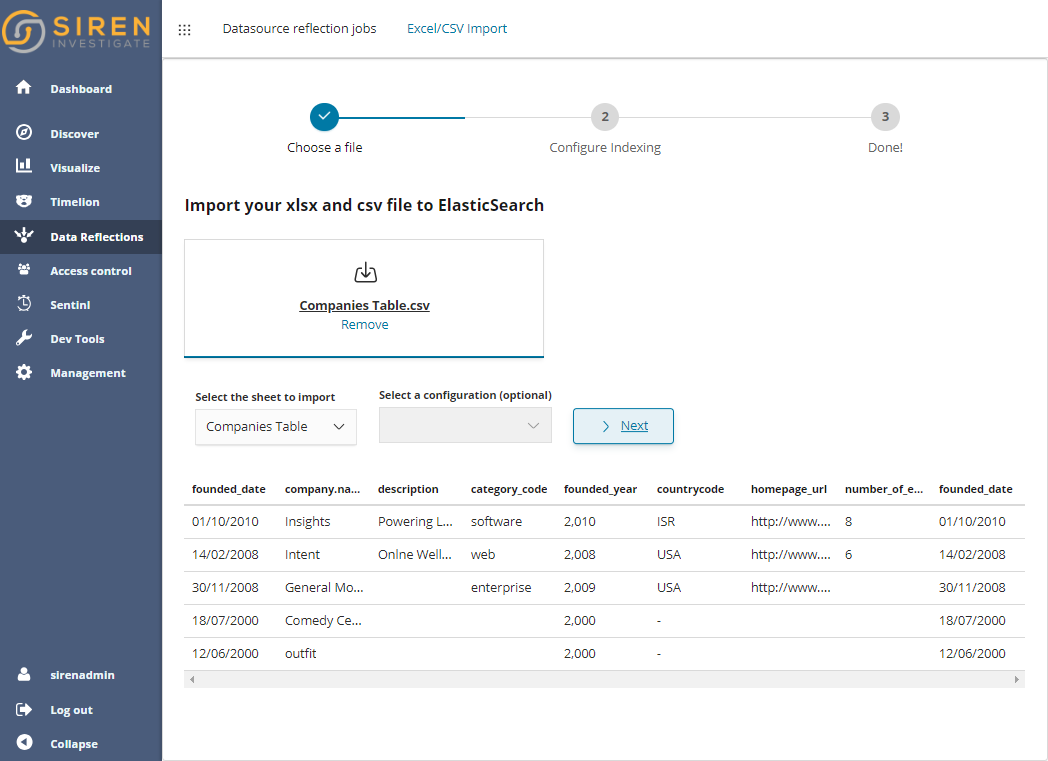
After a quick preview, one can configure Transformations and Mappings (data types), let’s see them in some detail.
Transform your data at load time.
Did you know, Elasticsearch has very nice data transformation capabilities in the form of “ingestion processors” (almost 30 of them) which can be pipelined as required. In its current version transformations are expressed in JSON still, but in Siren the environment is assistive and offers an immediate way to test the results on different inputs. Take a look below (just chose a sample or edit your input to see the result of the pipeline).
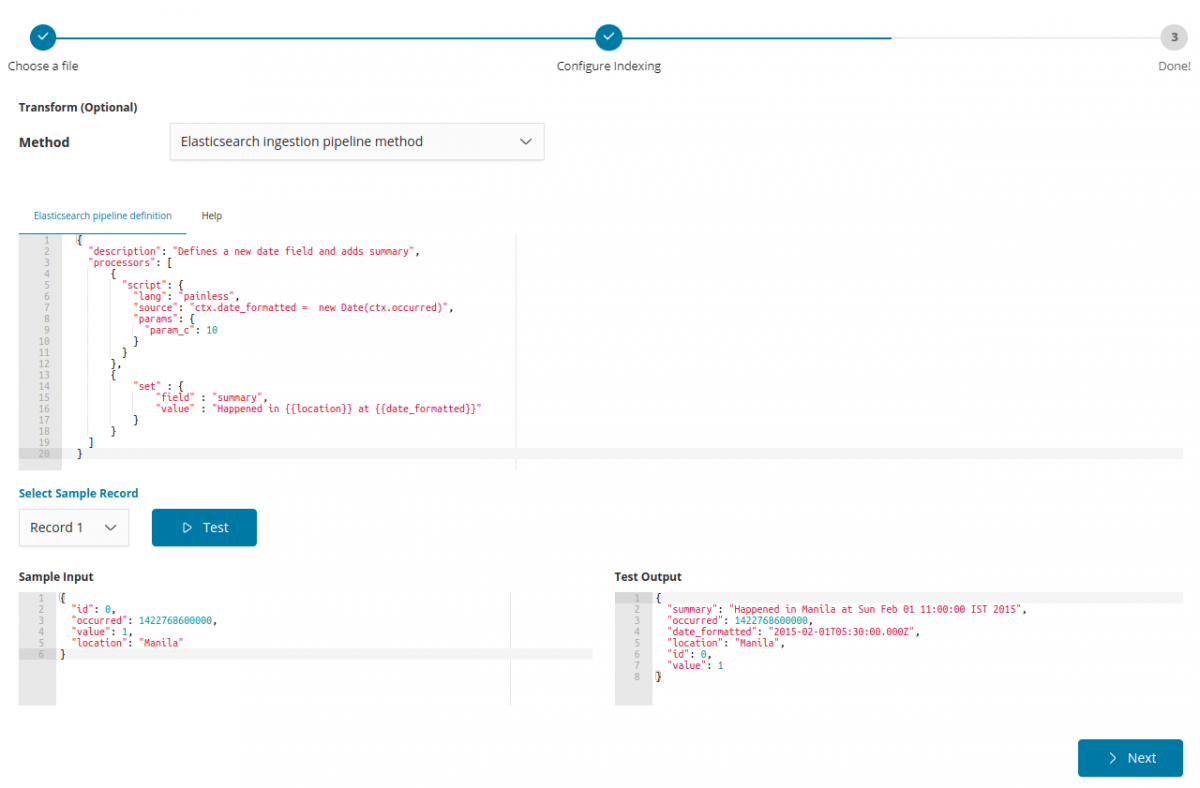
Also, once one is happy with a transformation pipeline, this can be saved and reused later for similarly formatted inputs.
Also, on top of the standard Elasticsearch pipeline processors, we’re adding a quite useful “Web Service Enrichment” processor. In the example below, the “Abstract” field of the currently processed documents is sent as the “text” parameter to the NLP service.

UI driven Elasticsearch mappings
The wizard features also UI driven schema review and editing (mapping to Elasticsearch data types). Why is this important? Sure one can simply index all fields as “text” but if one uses the right types then more meaningful analytics (word-clouds, proper unique counts, numerical analysis, date histograms and easy data filters) will be possible.
Again the process is quite simple, with Siren showing samples of values and also making some educated guess whenever possible.
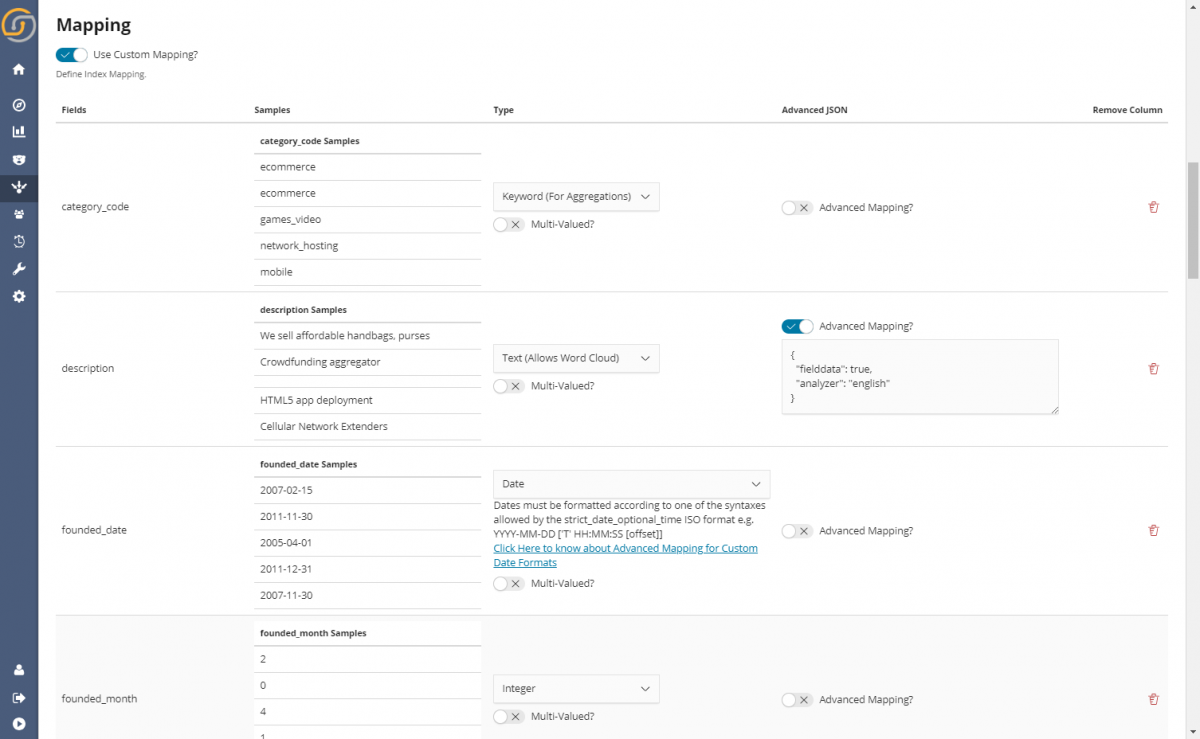
Once finished the CSV will have become an index, ready to be mapped as standard in the “Data Model” section of Siren. CSVs have no specific size restrictions, in our tests we have successfully loaded well into the multi gigabyte.
Repeated, “workflow uploads” a breeze.
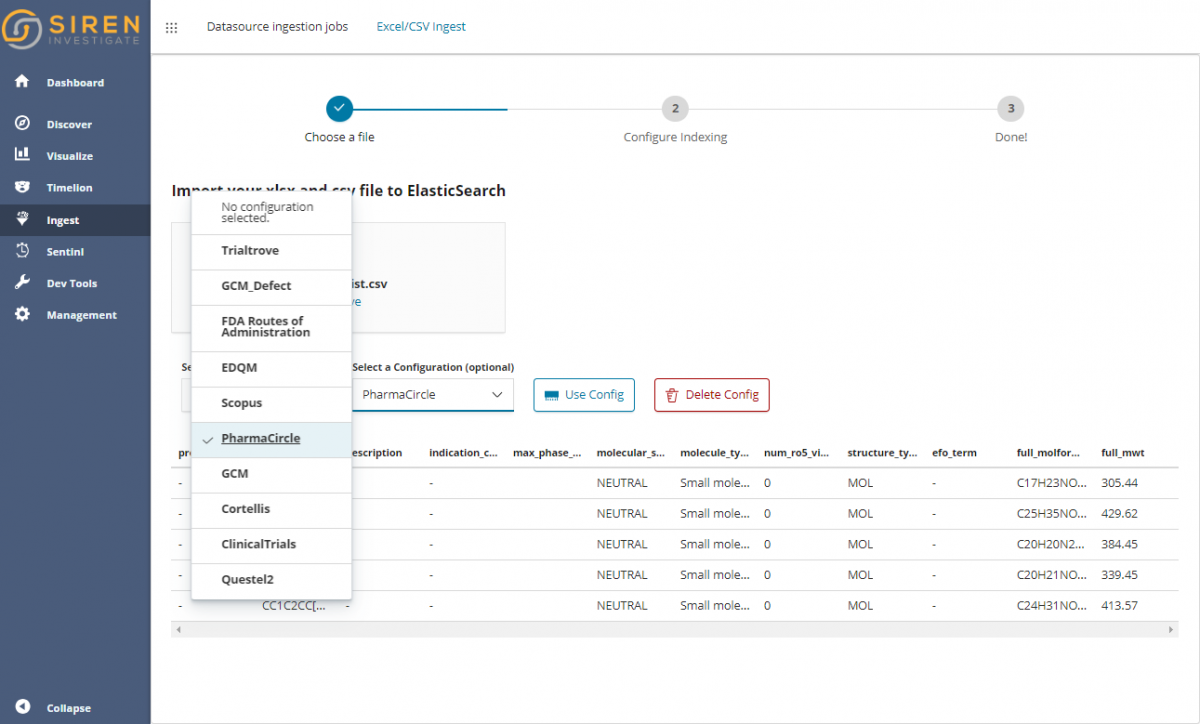
This feature has been developed for a casual data upload as well as serial “workflow” uploads where the formats are known a priori. In this case, thanks to presets which can be saved, the wizard makes ingestion a true drag and drop/single button activity.
Here is how one of our customers ingests fresh data from many well-known life science services, just selecting one of the previously saved configurations.
Data Reflections: kept in sync materialization of remote data
Last May with Siren 10 we launched remote data source virtualization (docs) — that is the ability to see remote JDBC data sources as if they were local Elasticsearch indexes, without having to copy data.
Virtualization gives Siren the ability to see in the same UI data from several physically different systems, without the need of copying it and no delays (live queries and responses are translated on the fly). For example, in the screenshot below, Siren is showing data from nine different virtualized back end sources.
While this is obviously great, there are a few things virtualization cannot do and use cases where it is not a good idea to continuously hit on a remote data source.
Enter data source reflections
Siren 10.2 launches the concept of optional ‘Reflection’ of remote data sources and virtual indexes into the (supercharged) Elasticsearch back end. Siren Reflections are setup within the UI and they can be scheduled to be re-executed regularly.
As opposed to virtualized indexes, reflecting data comes with the following advantages:
- Much better search and advanced analytics: by reflecting the data you’ll avail of the unique abilities of the Elasticsearch back end which are typically not available in other systems e.g. great search (with ranking of results, support for stemming, very sophisticated text analysis, advanced search query language), word cloud visualizations, significant term analysis, “more like this” similarity queries… and more.
- Denormalization into a more advanced data model: Elasticsearch, being an information retrieval system, has “multi value” attributes as a core feature. This is powerful to get better analytics — closer to real world situations where entities are often tagged with multiple values.
- Performance and scalability: Data reflection means that drill downs, search and aggregations will be executed by the Elasticsearch back end, which is typically faster than SQL back ends at these operations. You can expect multi-fold decrease in dashboard loading time in comparison to dashboards which use virtualized indexes in system like Spark (Data stored in Parquet Format — we’ll publish a benchmark and more).
- Decrease in load on remote system: By not hitting the remote data source at each access.
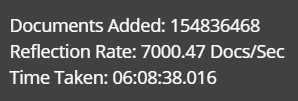
- Ease of setup & monitoring — built-in means simplified: There is nothing else to install to do reflections: Using the UI, it is quite easy to set up ingestion and the UI also acts as real time monitoring on the process – here is the result summary for a 150M spark document ingestion.
- Materializing complex or long-running query results: reflections allow one to write to a local index the results of long-running queries in other back ends to be used inside Siren. An interesting use case is for example detecting fraudulent patterns with back ends like Neo4j (now supported). See details below.
Reflections can be activated from the new Data Reflection side app, with a workflow coherent with that of the CSV import (allowing pipeline imports, setting of mappings, etc.). Want to know more? Check out: The alternatives to ETL into Elasticsearch: Virtualize or Reflect?
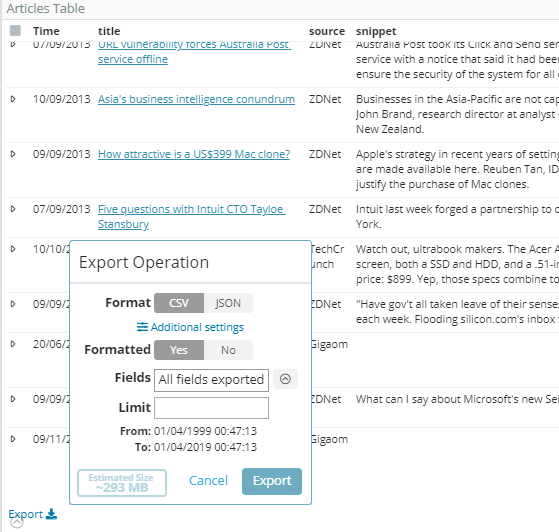
Big Data CSV/PDF and PNG exports
Gigabytes of data can be exported now with a click no matter which complex or relational filter is applied. Just click the button at the top left of the record tables.
Likewise, we’re happy to add one click PDF and PNG exports from the dashboards via the “Export” menu.
PDF look pretty nice, with username, timestamps and full filters on top:
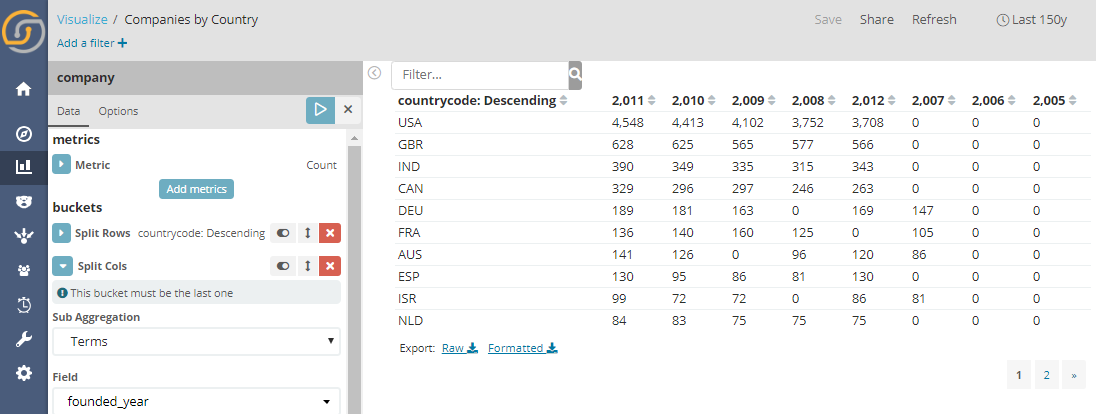
Enhanced data table (With Pivot table capabilities)
The analytics table component can now split by column, achieving a typical “pivot table” appearance. On top of this one can optionally activate a text search bar, scripted columns with math expressions, and several appearance configuration options.
Correlation Explorer
We have improved our parallel line correlation explorer and included it in the core distribution. Easy to explore how aggregate metrics and value buckets correlate, both creating filters on the axis and on the scatter plots.
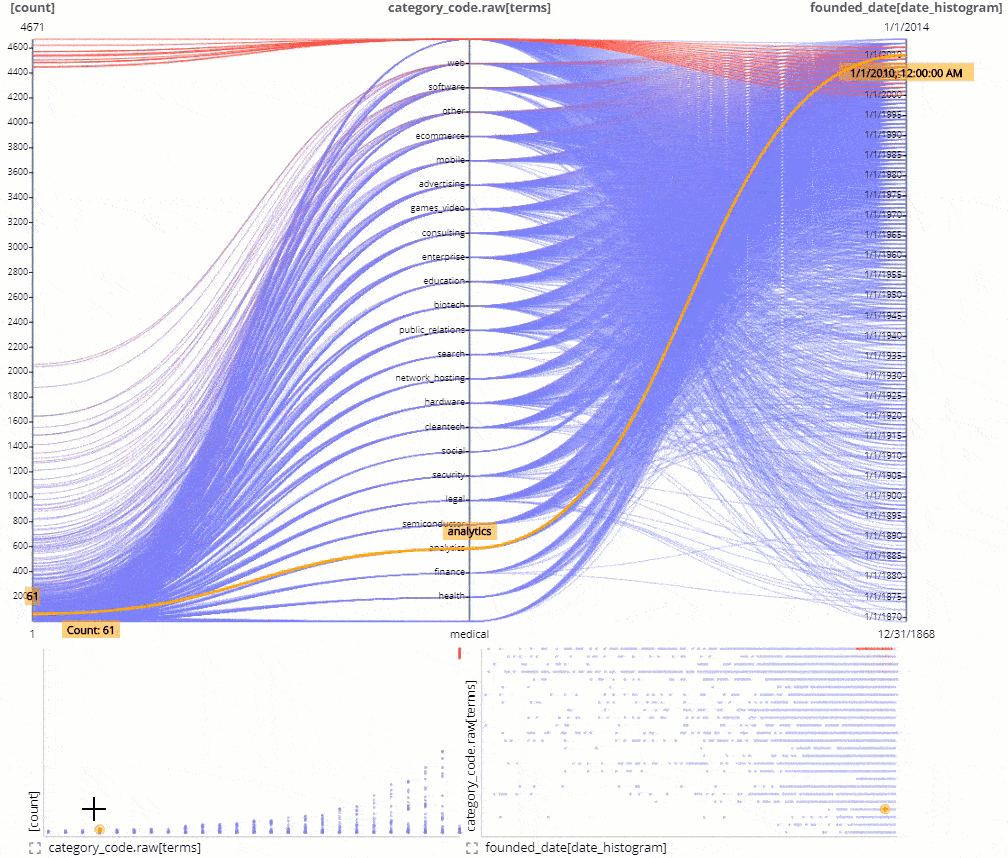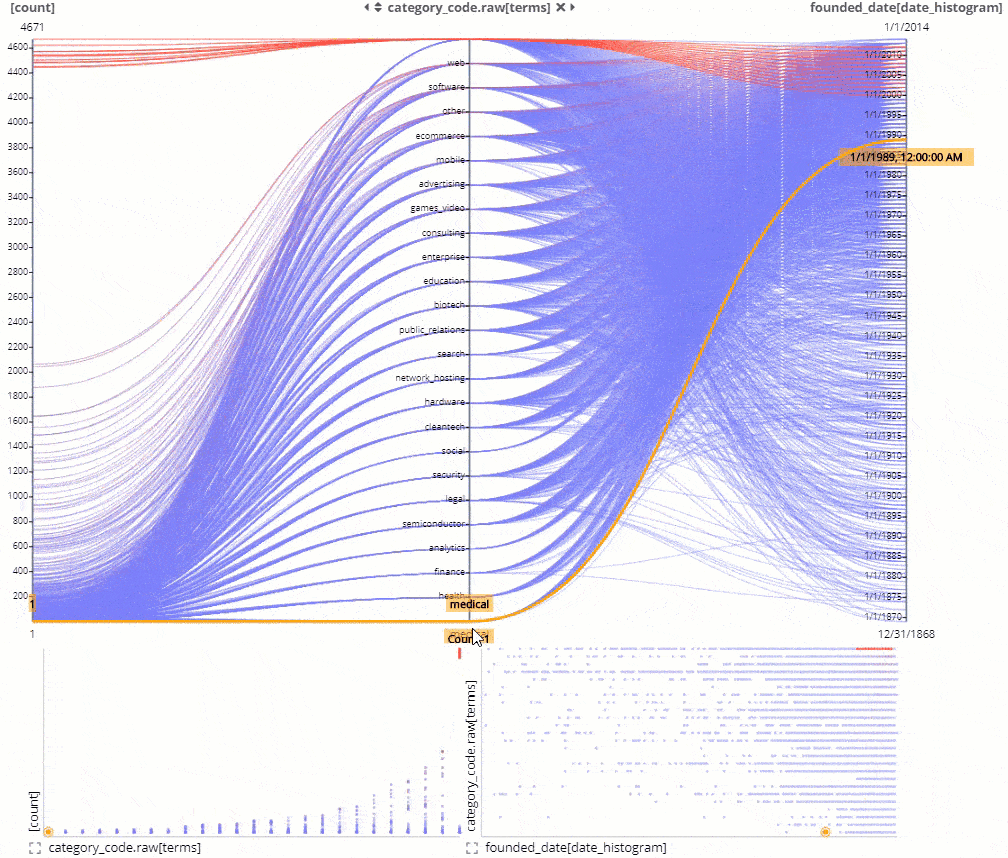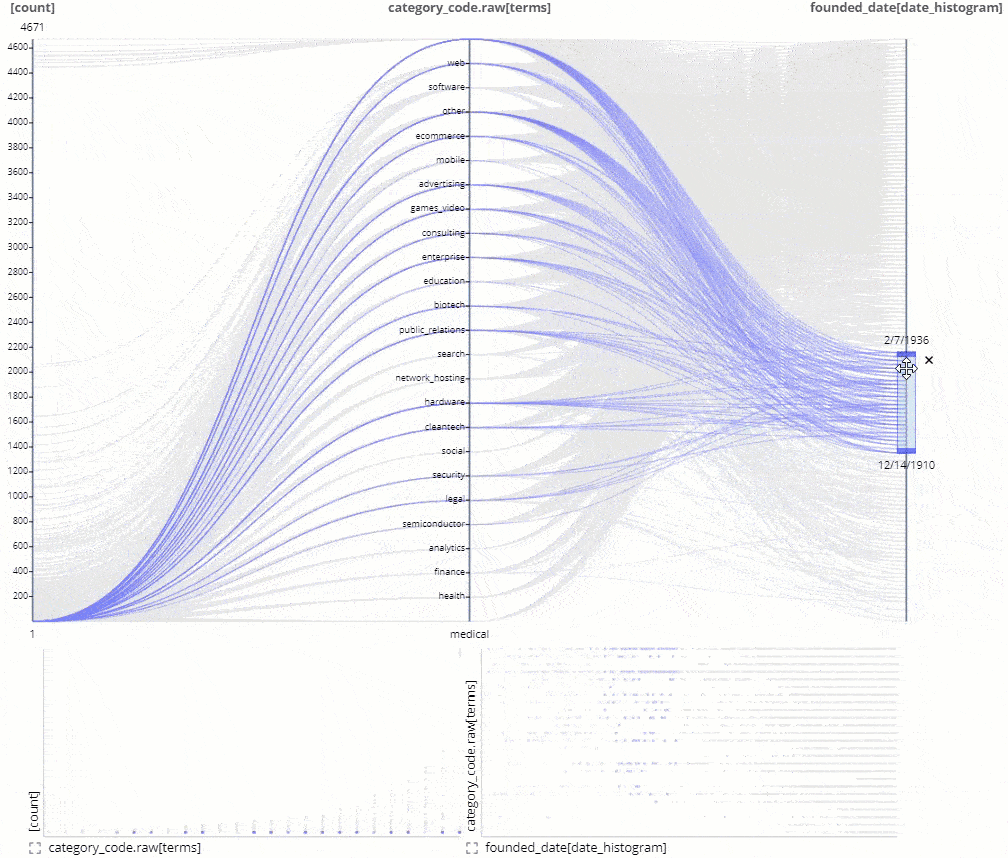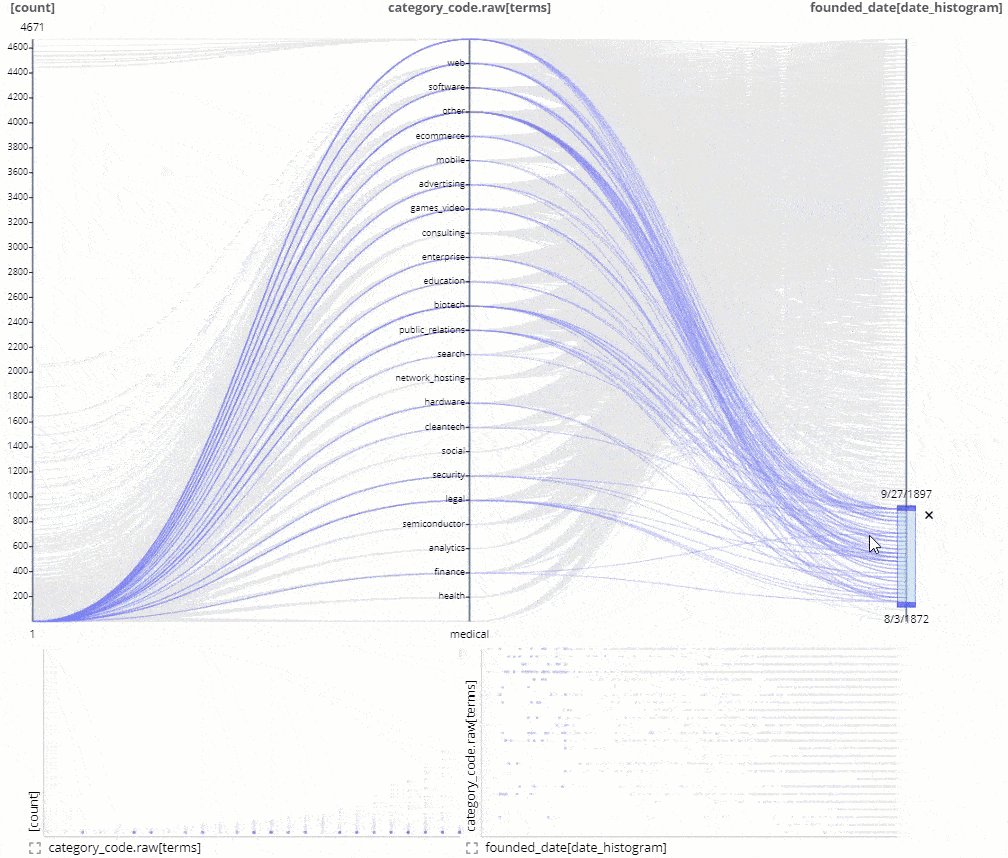
Improved Autorelations and relation preview icon.
Siren ability to automatically find keys to join and suggest a relational data model creation got better in 10.2 with many more options and smarter defaults recognizing email addresses, IPs, and other kinds of data automatically.
This is typically a big help to analysts building their initial model to get much faster time to value by connecting more data sets.
We have added a quick “view” button to visually verify relations within the relation editor in the data model. Just press the button.
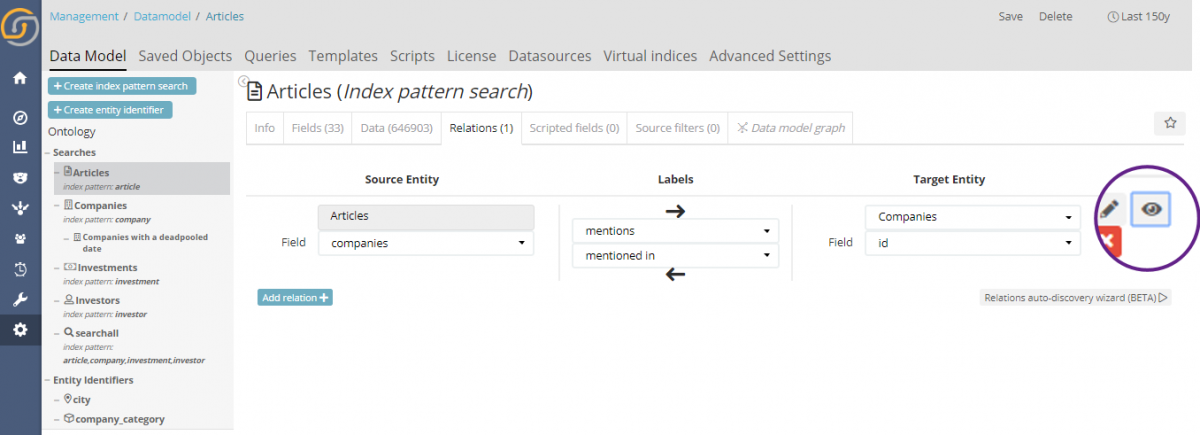
…and see samples of field value matched records from the 2 indexes
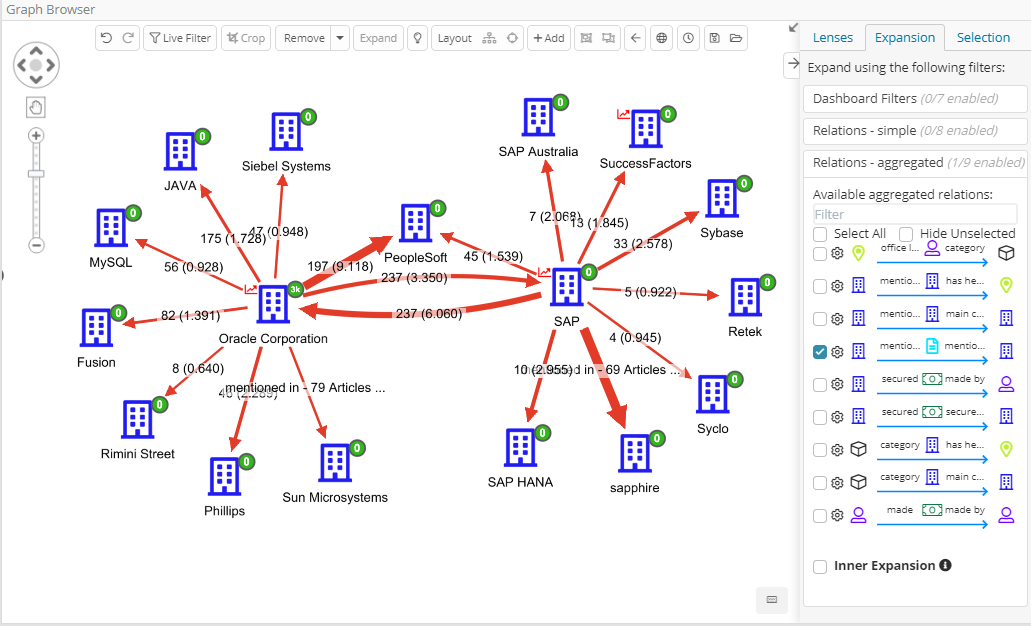
Significant terms aggregation is now available in the graph browser, as an option in the “Advanced Relations” and the results are fascinating.
In our demo data set of companies mentioned by articles (whereas articles can co-mention 2 or more companies) these are the results out of the box by activating the aggregate relation, starting from Oracle and expanding on SAP. We can see that “PeopleSoft” is strongly related to Oracle and mentioned very significantly together SAP.
Numbers on the arrows represent the number of articles that share the terms and the other number the “significance score” (also reflected on the arrow size).
Elasticsearch version bump.
Siren compatibility with Elasticsearch has been bumped to 6.5.4
Welcome Graph DBs: Our phase 1 support for Neo4j
We’re very excited to introduce our first connector to the graph DB World: the Neo4j ingestion connector.
With Siren 10.2, one can create a Neo4j data source and use it in the ingestion UI to bring in “slices” of Neo4j into the Siren back end.
Doing this will give you all the benefits above (textual search, ultra fast analytics dashboards, link analysis and all) and the data will be kept in sync automatically, within the “reflection” framework.
Even more interestingly, one can make use of the unique power of graph pattern detection of Neo4j by saving the results of graph queries within Siren indexes and then using them in Siren workflows.
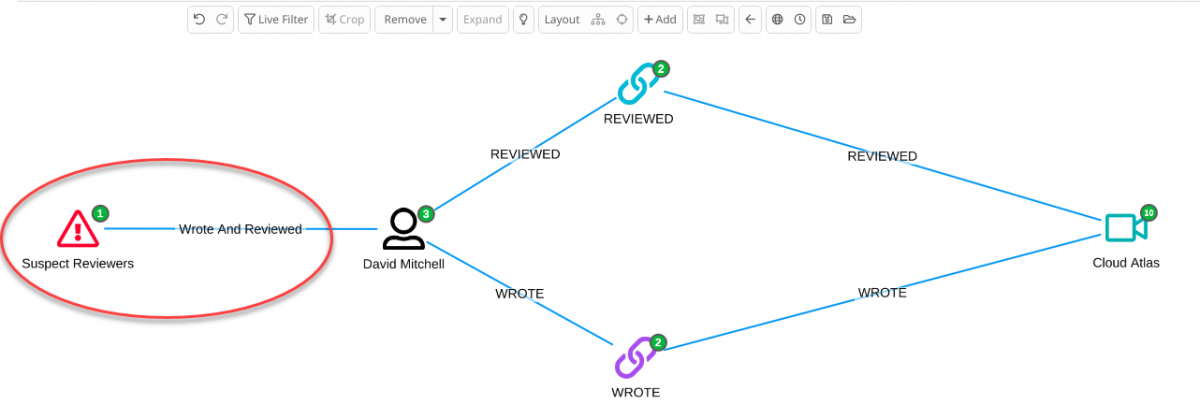
For example, let’s imagine we want to catch “suspect reviewers” on a public product review in the Neo4j movie review test database for example “people who put reviews of movies they have been starring in”.
Via the mechanism above, Siren can immediately visualize “suspect reviewers nodes” which can then be expanded to reveal the network.
Stay tuned for a blog post specifically on our initial Siren / Neo4j integration.
Last but not least: Getting Started tutorial and Siren Community
Siren 10.2 also comes with a very cool new tutorial and an “Easy Start” download package, which will help you to investigate your own data quickly.
Initial reactions to the tutorial have been great, users have been able to use Siren to analyze their own data easily and quickly.
The tutorial, by the way, works great on Siren Community Edition™ too, so why not try it now?
Last but not least we’re also launching the Siren Community portal.
In the community we’ll be providing open support, but also discuss Investigative Intelligence use cases and applications, provide FAQs, links to resources and more.
Feel free to stop by and looking forward to hearing from you!
What’s Cooking? Heads up on the next release
Works in progress for 10.3 and 10.4 Features include:
- Machine learning –We’re taking the route of integrating and leveraging state-of-the-art machine learning infrastructure. The result is GPU and cluster scalability, flexible models to cover a variety of use cases and auto discovery of the best ML models so that excellent results can be obtained “out of the box”. The first use case that will come with full UI integration is anomaly detection, which will be available integrated in the UI from 10.3, with prediction and general outlier detection coming soon thereafter. Stay tuned.
- 360° Dashboard mode –Want to know all about an entity or a group of entities in a single dashboard? With 360 dashboard model you can now define a per dashboard data model which ties together visualizations while retaining coherent drilldowns. This is best illustrated by example: a dashboard on “companies” can embed a widgets showing “their latest articles” which will automatically drill down once filters on “companies” are introduced. Furthermore, one can then filter on the articles (e.g. by date) and see the “companies” coherently filtered. The result is amazing, interactive 360 degrees view around both individual entities and groups of entities at the same time – all as a coherent extension of normal dashboards.
- Scriptable augmentation and workflows – Siren will not be introducing new scripting language, instead we’re introducing a safe layer of Javascript that can automate workflows and create ad hoc visualizations. End users can use this directly to augment data (E.g. adding a scripted column via ad hoc query or service lookup). Administrators can create workflows and automations to minimize the number of clicks to insights for the end users.
- Entity Resolutions – We’ll be extending our regular “key based” join capabilities to fuzzy matching also known as “Entity Resolution”: Siren will be able to automatically locate “islands” of records which are, with high probability, referring to the same real world entity, as well as suggest “links” across entities which are likely different but linked by some strong similarity attribute (E.g. the same or a very similar address).
- Connectors! Several connectors are cooking and will be rolled out.
- (The new) web service integration framework – the ability to use external web services both on the graph and on dashboards. Enrich your investigations on local data with data retrieved on the fly from remote services, with core use cases in Cyber, Law Enforcement, Intelligence, Financial and more.
- Open Distro for Elasticsearch compatibility – we’re working with AWS folks to make sure Siren 10.3 and beyond are also compatible with Open Distro Elasticsearch distributions.
Conclusions
10.2 introduces a number of features and improvements that make it easier than ever to access and use Siren. With this version we’re also rolling out our community tier and our community forum making it easier to both get started on the software and get help. We look forward to hearing from you.















