
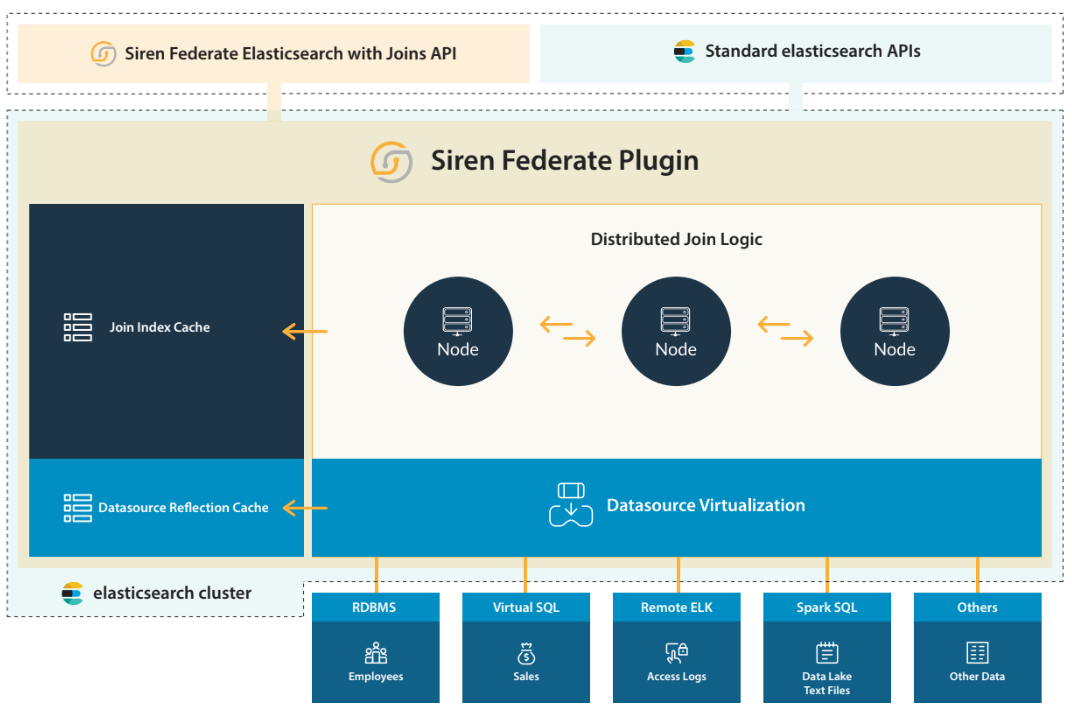
The Siren Federate 21.0 release delivers important developments: index-based join, new documentation, and Elasticsearch 7.9.3 compatibility.
The index join
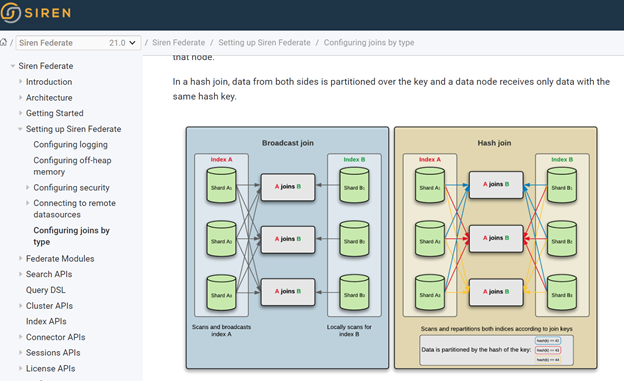
Siren Federate 21.0 introduces a new distributed join strategy, the index join. This index join strategy complements the existing hash join and broadcast join strategies. The index join strategy is similar to the broadcast join strategy: The input data is sent to every data node. Compared to the broadcast join, which scans the doc_values to find matches, the index join uses the Lucene dictionary to look up and find matches.
One limitation of the broadcast join strategy is that it may have to scan a large list of doc_values. For queries where there are a large number of terms being transferred, the network cost might be dominating the total query execution cost and, therefore, the scan cost might not be very significant. When a small number of values is joined or the list of doc_values is very large, the scan cost becomes more significant and the index join shines. If an index data structure exists, values can be looked up individually. Because Elasticsearch automatically indexes all values in a Lucene dictionary, this strategy is available on supported data types. Numerical values are indexed in a KD-tree data structure, while keyword values are indexed in a prefix trie data structure.
When a query with a join is received, the Siren Federate query planner selects the most cost-effective join strategy based on the scenario. You can also manually select the strategy you prefer. With Siren Federate 21.0, the planner can now use the index join strategy, which in turn will select the appropriate dictionary to look up a set of values.
Index joins provide dramatic speedups when the input data is comparably small to the size of the target data. This is a very common situation in investigative scenarios: For example, you might be analyzing the behaviour of a relatively small group of users, compared to the size of the logs.
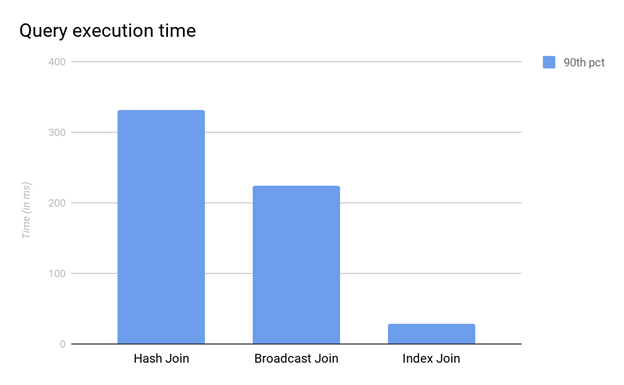
Another example of an index join making a difference is when you execute Siren’s own “Shortest Path” algorithm on Elasticsearch. The algorithm works by performing graph traversal in parallel via join queries. Each join step expands in parallel the set of “all the nodes that have been reached” until you potentially find the target node that you are looking for. The first several steps are those in which the index join makes all the difference since, previously, the system had to scan all of the doc_values at each step. Let’s see the numerical differences in this case.
The bar chart below presents a comparison of the performance of each join strategy on the initial step of a graph expansion query. The benchmark is performed on a 3-node cluster in Google Cloud (n2-highmem-8, Cascade Lake, SSD, 32GB). We execute each query 25 times and we report the 90th percentile. The query consists of looking up a single entity from an index that is composed of 2 million documents and expanding its relationship to neighbourhood entities (with an average of 5 neighbourhood entities) from an index composed of 10 million documents. The hash and broadcast joins are particularly ineffective for this type of query and the scan cost dominates the execution time. Both the hash and broadcast joins execute a full scan of the index with 10 million documents in order to match a single entity. Additionally, the hash join is shuffling 10 million documents across the cluster. In contrast, the new index join in Siren Federate 21.0 executes a single dictionary lookup. The result is a join performance that is improved by 760% in this case.
At the heart of Siren 11.0
We are happy to announce that Siren Federate 21.0 is at the core of the forthcoming Siren 11.0 release. Users who are upgrading from previous versions of Siren Platform should notice a considerable speed-up in performance.
Documentation
The Siren Federate documentation has been improved significantly and now includes a section on how to set up Siren Federate. It describes how to configure off-heap memory, security, and joins by type, and includes a troubleshooting guide.

Siren Federate 21.3 is available today, compatible with Elasticsearch 7.9.3. Get it now!















