

Today we are very excited to announce the availability of the Siren Platform v12.1. Several all round improvements, specifically on “360 degrees” data visibility, downloadable and editable reports and data model scalability are included.
Let’s see them in detail.
More of what you need to know, in a single Screen.
Siren 12.1 provides strong extensions to facilitate getting 360 degrees views around entities (people, companies) – no matter where the original information resides.
Two features specifically enhance these capability:
- Entity Based, 360 degrees scripted report – powered by a new graph traversal API
- Record Consolidation jobs (beta – additional component)
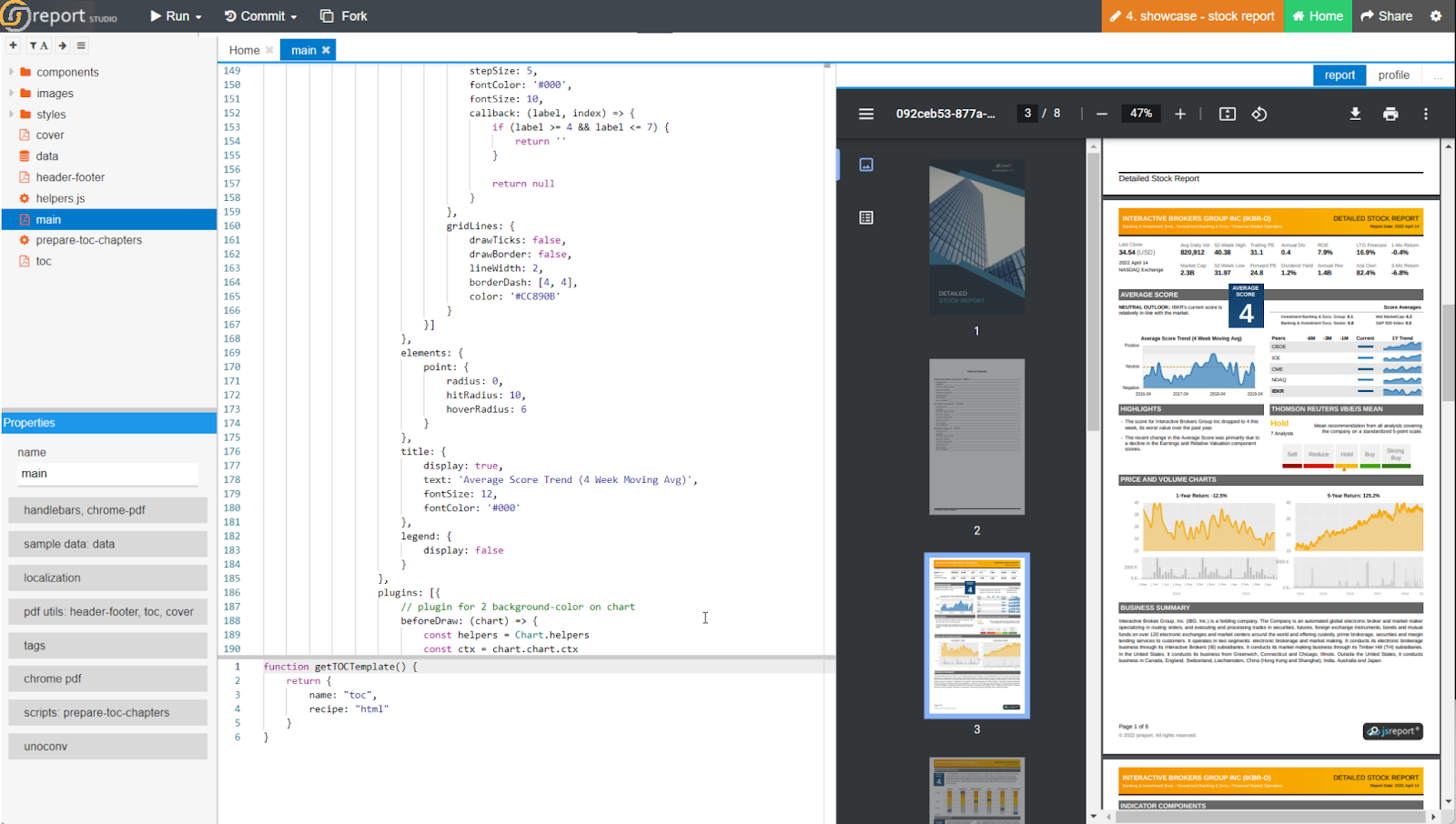
Entity Based – 360 degrees scripted reports (WORD/PDF downloadable).
Siren 12.1 introduces the ability to have a rich “360 degrees entity description”. These are scripted templates which can show information about the record with data coming not only from the record itself but also from connected records and web service calls.
Also these can be interactive with UI elements like buttons, interactive menus and more.
Templates can be visualized simply by clicking on the records, or they can be converted and viewed as WORD or PDF exports – It is also possible to copy and paste content for easy editing and dissemination.
Here it is in action!
Reporting flexibility with the new Scripting graph traversal API.
At the heart of the flexibility of this new report feature are 2 elements.
The Siren API has been powered up with new graph traversal capabilities. When writing templates one can easily start from a record, and navigate to find connected records whose values one wants to visualize.
Then, the resulting data is turned into react/HTML for rich interactive experiences or turned into PDF/WORD using the built in Report Building interface
Performance: welcoming Siren’s new columnar engine and joins on _ID.
Siren 12.1 comes with the new Federate Elasticsearch plugin v27. Among the innovations, it sports a completely new columnar approach which delivers considerable performance improvements and the ability to perform joins involving the Elasticsearch fixed _ID field.
In fact, joins on the _ID field are the most efficient type of join (after joins on numeric values) and are the recommended join method (also conceptually as _ID as the field that should be used for primary keys).
(Expect a full blog post on this soon).
Data Model scalability: 1000+ Relations.
In leading policing environments analysts use rich relation vocabularies across a matrix of up to 100 different entity types. This leads to potentially thousands of valid “source / destination” combinations which, in the Siren data model, can be modeled as thousands of individual relations.
We’re happy to announce that Siren 12.1 extends the data model scalability to comfortably deal with this number of relations thanks to usability and scalability improvements at several levels.
The data model relation page is now considerably optimized, while the data model graph browser, can show relations between the same entities in aggregated forms.
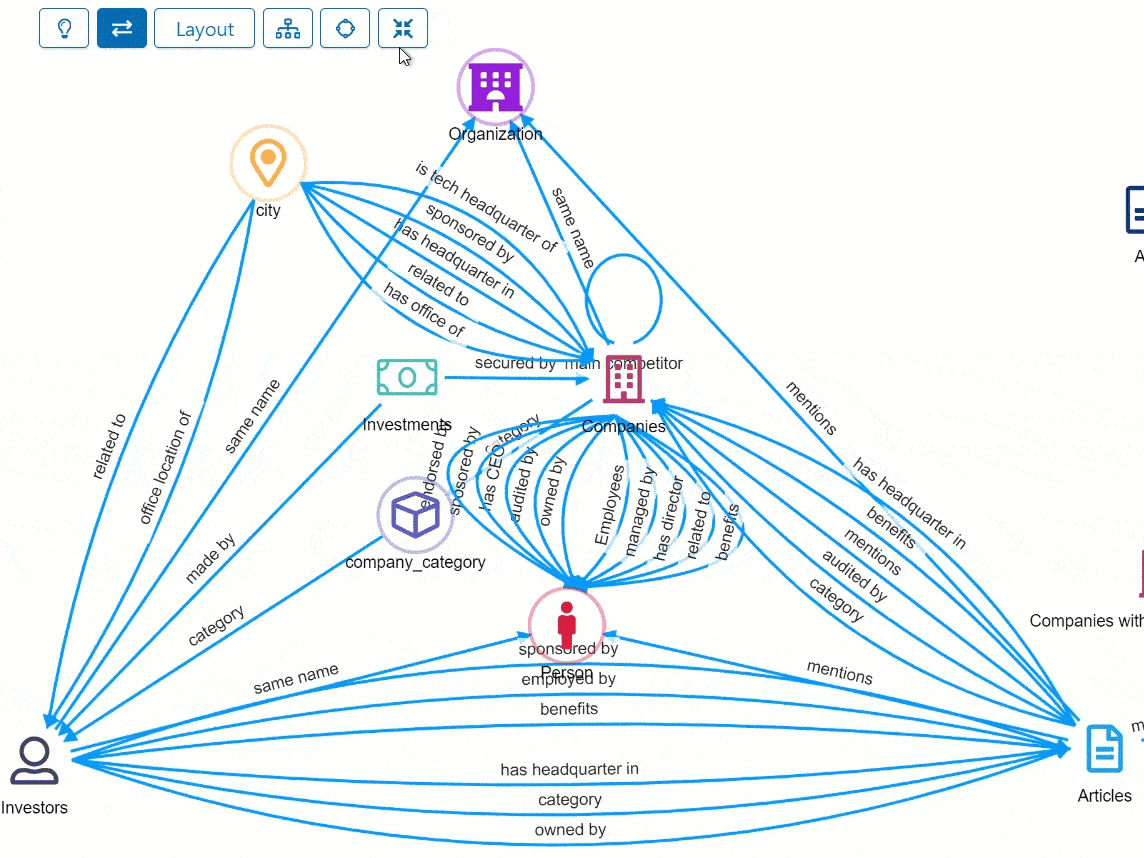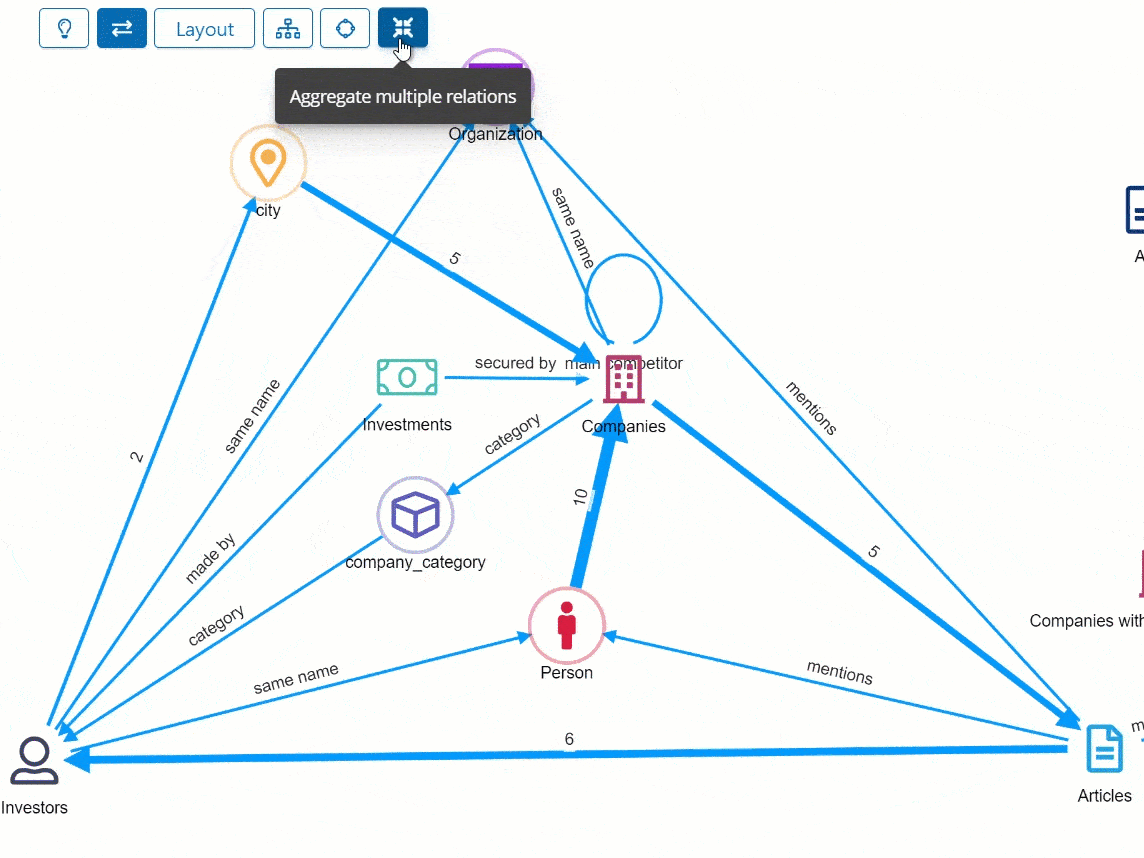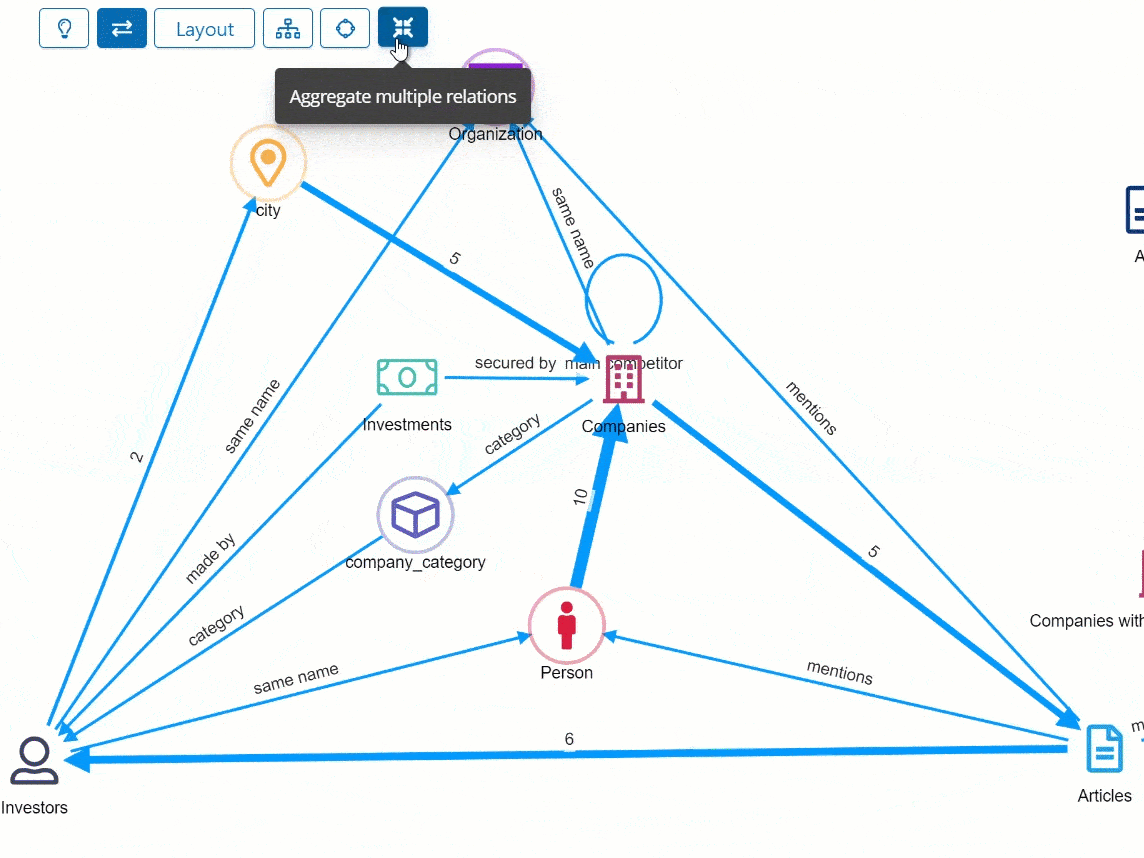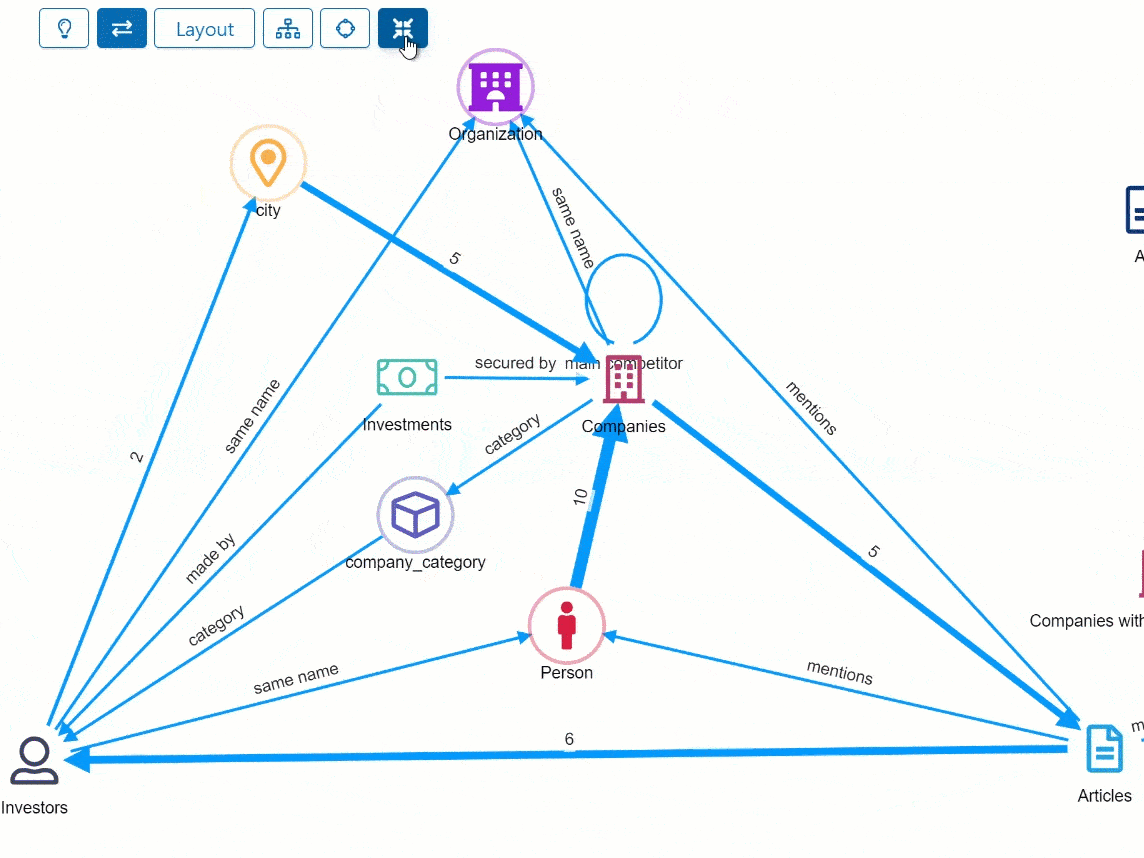
While on the dashboard’s relational navigation buttons the target dashboards can now be nested.
Other sectors benefiting from these scalability improvements include Cybersecurity, Health Care, Fraud and more.
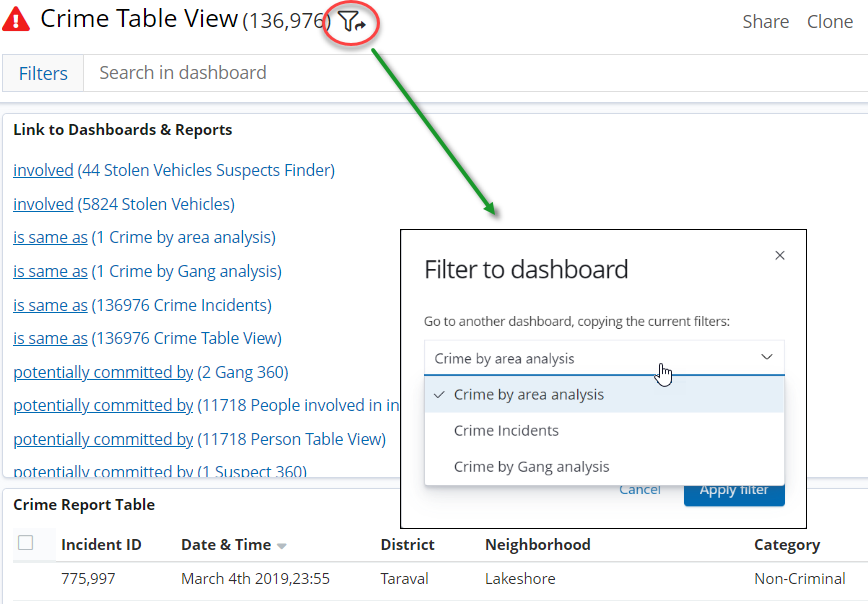
Filter based pivoting: change your analysis point of View.
Sometimes one wants to see the same results under a “different point of view”.
For example, when visualizing a set of companies one might want to take a geographical view, or a financial view or the point of view of information related to them.
In Siren 12.1 analysts can pivot from a dashboard view to another via a “filter based pivoting” function available which activates whenever there exists an alternative dashboard view in the dataspace.
Easily create dashboards visualizing Sub Searches.
In Siren 12.1 one can now create sub searches and coherently use them for dashboards so that all the visualizations will inherit the sub searches filters.
For example, say that one has an index of “communications” containing a mixture of SMSs , Phone calls and Emails.
One can now create 3 subsearches to the main “communication” index and use them to create dashboards in a way that will look like if we had 3 separate Entity Tables – yet all relationally connected as their parent “communication” search.
This, in conjunction with Siren’s ability for components to “inherit the search from the dashboard” makes it easy to have dashboards specific to types and subtypes – in a way that is maintainable, without duplicating components.
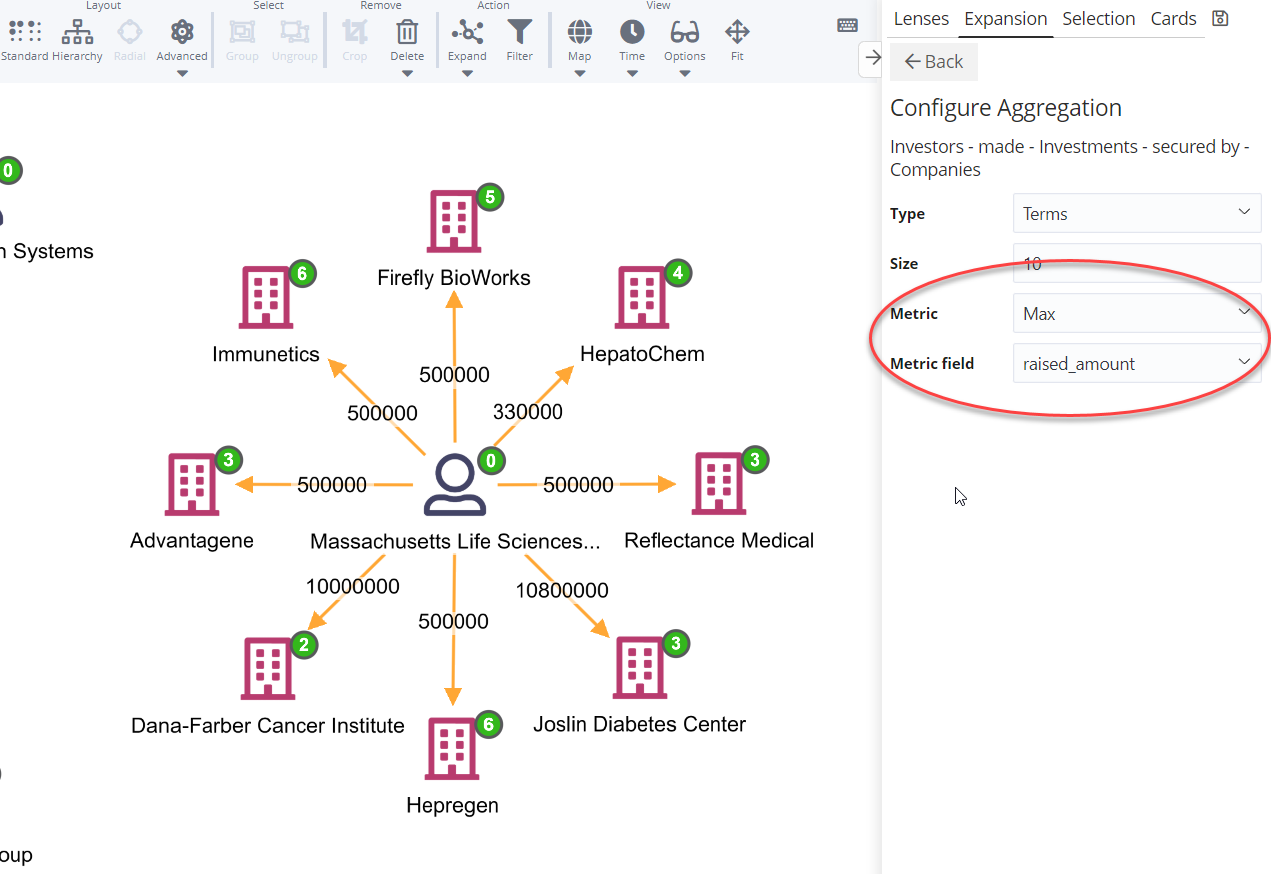
Graph aggregate metrics and Sorting.
Previously, aggregates on the graph would only show the counts of the intermediate records. Now it is possible to select metrics like sum, max, min, average.
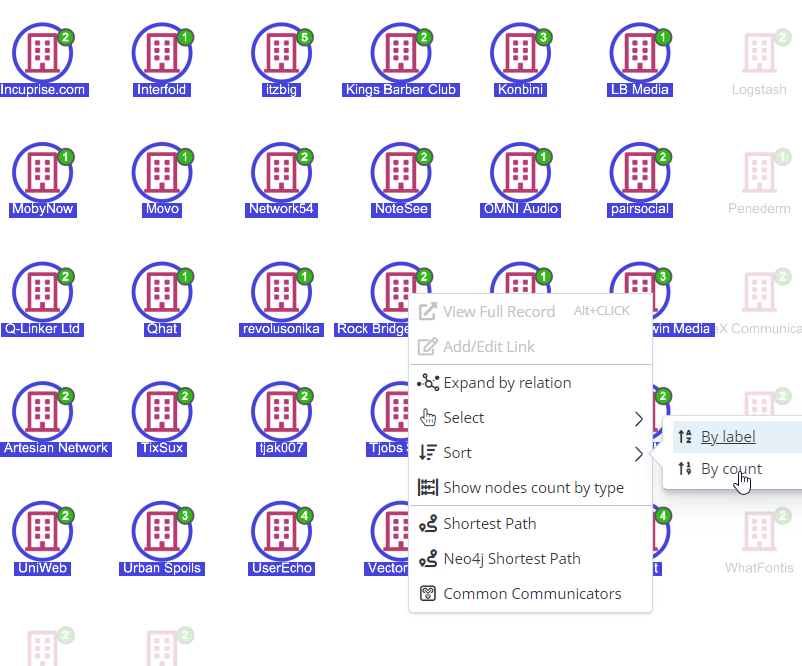
Also we have added a sorting / regrouping function, which can be accessed on the right mouse button and places a set of selected nodes in a group.
Introducing record consolidation jobs (beta – available as Plugin)
In real world scenarios data systems have often grown “organically” or are simply composed by multiple – integrated systems each with their own tables.
Taking a real world law enforcement scenario, one is likely to have not 1 central “person” table, but instead many separate ones, e.g:
- Traffic violations (where a person might be “embedded” in the fields of a “Traffic violation” record)
- A central “known individual” table
- A mirror of a court system people database
- etc.
Obviously, the same individual may be appearing in many tables and often many times in the same table.
Also, often these records are not identical but may have different set of values e.g. they may present different phone numbers, all of which are interesting for an investigator.
Siren already provides entity resolution capabilities to “detect” that two or more records are referring to the same real world entities.
But with Siren 12.1 it becomes easy to launch recond consolidation jobs which create “centralized records” which give you at a glance the full view on the entity e.g. having all the phone numbers / known addressed together in the same records
It becomes then possible to create high quality search experiences and leverage the information at best on dashboards visualizations, for associative (relational) navigation and on the graph.
Multiple primary keys for smart, iterative record Consolidation.
A core feature of the record consolidation is the capability of using multiple primary keys. This means that one can specify a set of identifiers (e.g. phone numbers, social security number, email) and if any of these will match across all the combination of records then an interactive consolidation operation will happen.
The result is smart, comprehensive consolidation unearthing insights from all the organization data sources. The following annotated screenshot comes from a real world scenario where 5 different “satellite” tables totalling over 9 million documents are marked in just a few hours into a clean central table, ready to be used as the central “person” entity data model in Siren.
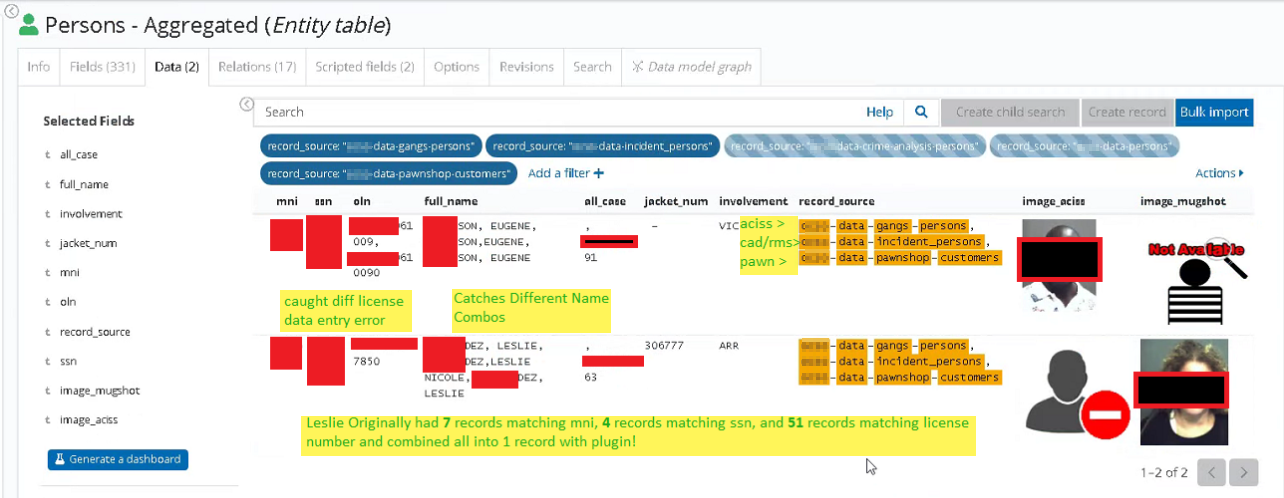
The ability to launch record consolidation jobs is available as an add on plugin, similar to NLP and Entity Resolution. The plugin can be downloaded from the support portal where documentation is also available.
This plan is to make it part of the core Federate / Investigate platform following an initial feedback phase.
Wrapping up
The ability to see 360 degrees of information in a single screen is fundamental for investigators.
Siren 12.1 delivers on this promise and to this it added the ability to export reports in PDF or in editable form (word or rich clipboard structure).
To this, we also add the ability to consolidate records at large scale, therefore colleting ‘all the known phone numbers’ in a single searchable record – no matter where the original records come from.
We are proud to not only drive but, moreover, to push forward investigative capabilities and deliver them to selected organizations worldwide. We look forward to your feedback on Siren 12.1.
Here are some resources to get you started:















