
What is in this release?
We are announcing the availability of the Siren Platform v10.3. This is a major release with many new features and improvements, among which are 5 distinct core AI capabilities:
- Deep learning-based predictive analytics and alerting (Siren ML) – real-time forecasting of operational data streams and alerting on expected future crossing of set thresholds.
- Deep learning-based time series anomaly detection (also in Siren ML) – the capability of learning from data to recognize and alert for anomalous behavior. Unlike other offerings on the market, Siren offers this based on automatic model selection ML, powered by Dockerized TensorFlow-backed APIs with seamless front-end integration.
- Unstructured data discovery with real-time topic clustering – Discover meaningful clusters within textual documents (reports, emails, news articles, and so on), based on auto-discovery of key terms and topics, with the new Topic Explorer, a built-in real-time interactive clustering visualization.
- Associative in-dashboard Relational Technology (“Dashboard 360”) – Siren dashboards now allow the definition of an “internal data model” by which visualizations on different tables (searches) can coherently display only data from “connected records” at each step. This provides a 360-degree view of a record (or groups of records), showing in a single view what is connected (both directly and indirectly, via many relations). What makes this feature unique on the market is that you can filter each of the interconnected visualizations, and all the others will update coherently to only show records that are not filtered out (as they are not associated).
This “associative” drill-down capability has, up to now, only been (partially) available on high-end Business Intelligence (BI) systems; these systems, however, require all data to be in memory, thus sacrificing scalability and real-time capabilities. With Siren Dashboard 360, this associative drill-down capability is now available at big data scale, in real time, on Elasticsearch or other backends. - State-of-the-art, self-correcting entity resolution (Siren ER) – this is the AI/ML ability to recognize that records across different tables and datasources, using different schemas and different languages, are in fact talking about the same entity (person, company). Siren ER is real-time and capable of “self-correcting” previous statements as new information arrives.
Before discussing this in more detail, we feel it’s important to share the philosophy that’s driving Siren Architecture, as we grow.
Siren 10.3 launches a set of modules, distributed as Dockers, which one can add to get additional capabilities, the first ones being Siren ER and Siren ML.
Siren ❤️ Dockers: So you get best-in-class AI
AI technology is critical today to deliver value in analytics and discovery.
At Siren, we believe you want the best possible contemporary AI from the best frameworks out there and we don’t believe you’ll have problems running a Docker.
So, we’re saying no to monolithic approaches (e.g. trying to force everything to happen inside Elasticsearch nodes) and instead encapsulating best-in-class add-on components in Dockers, which then communicate with the main Siren Platform via a documented API.
In Siren 10.3 we are releasing our first Dockers, “Siren ML” and “Siren ER”, the Siren Dockers for Deep Learning and Entity Resolution respectively; Siren Natural Language Processing (NLP) is due for the 10.4 release.
Siren ML, for example, contains Python, TensorFlow, and many modern libraries, which you cannot fit monolithically in Java (as a plugin to Elasticsearch, for example). Likewise, Siren ER elegantly encapsulates one of the most celebrated and advanced commercial Entity Resolution engines on the market, again written using optimized C++ code, Python, and others.
Thanks to Docker, using this mix of technologies is not an issue; we’re always free to choose the best technology that provides greater value for the end user.
Let’s take a closer look at some of these modules.
Siren ML: Deep Learning for Elasticsearch (and everything else you can connect Siren to)
Siren ML is a Docker container which provides an API for Deep Learning-powered AI which can operate on data in Elasticsearch or in any other backend supported by Siren Federate.
Powered by state-of-the-art machine learning infrastructure (TensorFlow), Siren ML can leverage GPUs, can scale on clusters, and makes use of the latest Auto-ML techniques to get excellent results “out of the box” (with no or minimal parameter changes).
What can it do today and what will it likely be able to do tomorrow
The first use case with full UI integration is anomaly detection and forecasting (with related alerts). All the functionalities are driven by a UI which integrates inside the Siren dashboards. In the following screenshot, the anomalies were detected on a “cost per click” stream:
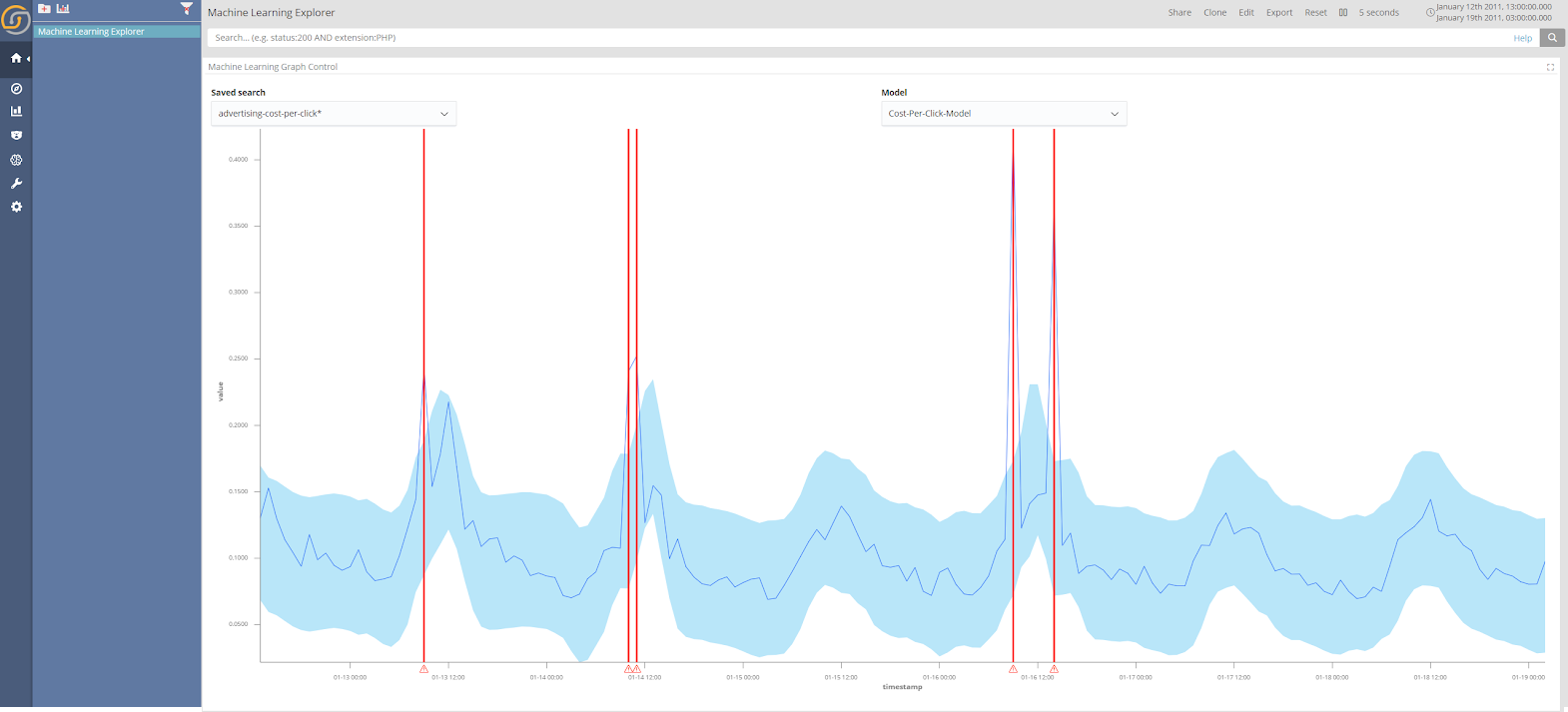
And the following example shows daily temperature prediction used in conjunction with automatic alerts:
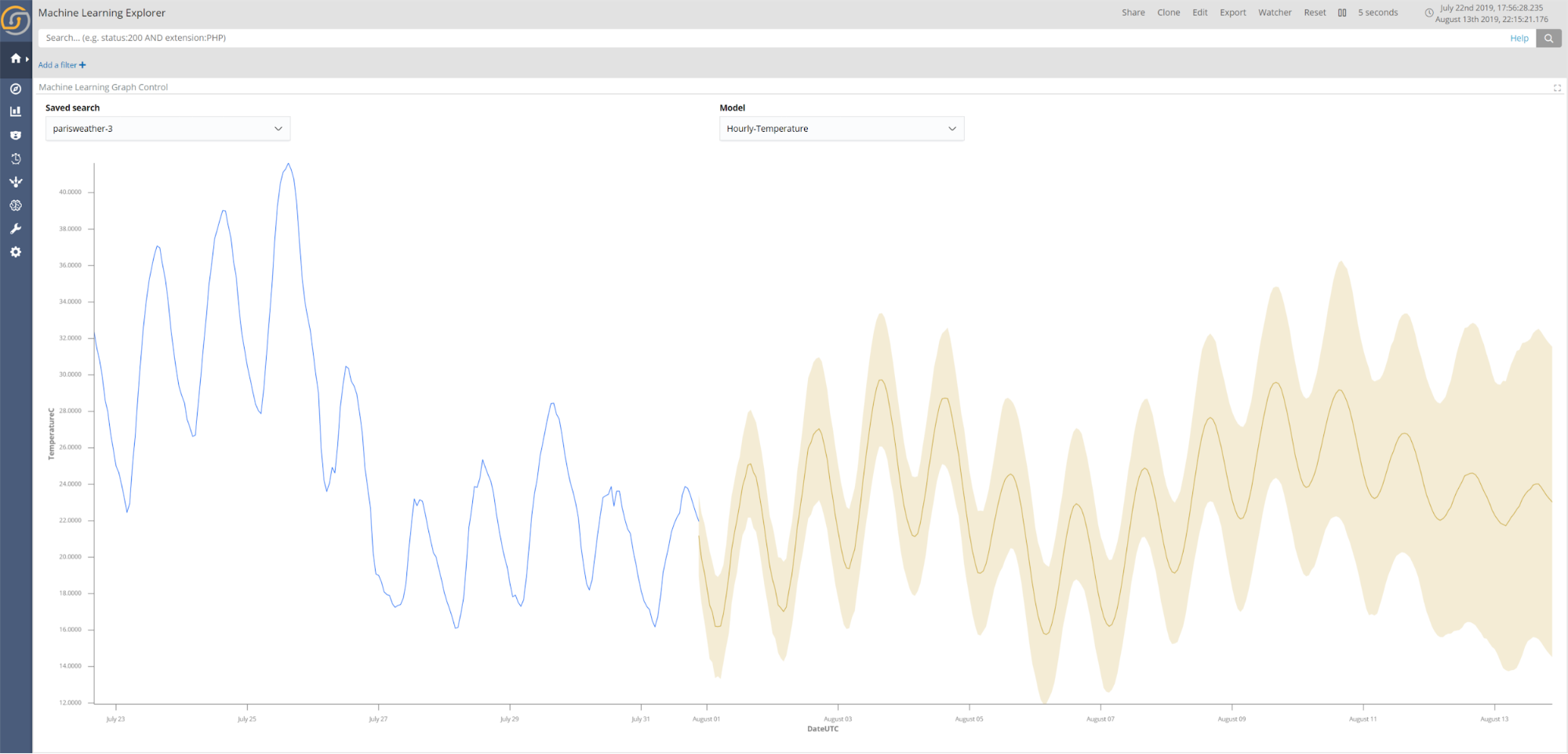
Thanks to a contemporary architecture powered by TensorFlow (with cluster and GPU capability), Python, and best-in-class Auto ML techniques (to automatically select the best performing neural network topologies), Siren ML is a future-proof component.
In the next few months Siren ML will gain more capabilities, among which will be population anomaly detection, outlier detection, link predictions (and even more to come). In general, being as flexible as it is, we are also considering giving the ability for the end user to upload models and extensions to Siren ML. For example, it will be easy to reuse the existing infrastructure for machine vision annotations or many other tasks for which deep learning is celebrated today.
Siren ML is available in limited form (three models) in our Community Edition, while it’s unlimited in the Siren Business Edition.
Read much more about Siren ML in it own blog post.
Siren ER: Automatically generate connections between records and discover “relations”
Siren Entity Resolution (ER) is a Machine Learning component capable of:
- recognizing that two or more records (which could be about people, companies, cars, or any other thing) are very likely to be referring to the same real-world entity (for example, the same person)
- recognizing that two or more entities are interestingly connected (for example, they share an unusual combination of attributes)
When done properly, Entity Resolution is nothing short of a superpower for enterprise applications and investigative analytics. For Siren ER, we’re partnering with Senzing to provide state-of-the-art law enforcement-grade capabilities.
If you have not seen the video below, you’re in for a data treat!
Siren ER is available in limited form (10k entities) in our Community Edition, while it can scale to a billion+ entities (so several billion records possibly) as part of Siren Business Edition.
For a thorough discussion on this feature read the dedicated Siren ER article
Relationally linked visualizations in dashboards (Dashboard 360)
Siren is industry unique for its relational navigation capabilities: the Siren data model allows one to move from a set of records (e.g. a dashboard with a filter) to the set of records which are relationally connected (e.g. in another dashboard). All this at big data scale.
Up to now, Siren has provided these relational capabilities:
- In Siren Investigate’s relational navigation buttons (the blue buttons that connect one dashboard to another)
- In the Graph Browser, Siren’s link analysis component
With Siren 10.3, we’re launching “Dashboard 360”. This feature has the ability to link visualizations within a dashboard to create a “360-degree” interactive view around an entity or group of entities.
Thanks to a new dashboard data model, you can visually configure the relationships between different search-based visualizations on a dashboard which then allows coherent filtering across all of them.
To make life easier, let’s look at an example.
Let’s assume we have a data model where we have a table “investor” connected to another “investments”, which then is connected to another “companies” and yet another “articles”.
In other words:
Investors – make → Investments – secured by → Companies – mentioned in → Articles
In the screenshot below, we have created a Dashboard 360 around the “Investors” table.
The icon on the dashboard (top left with the count) indicates that it’s “Investors” we’re talking about (the “main search”); currently there are 31 investors selected by the filters which are shown below (Investor countrycode: DEU, Investment Roundecode: SEED)
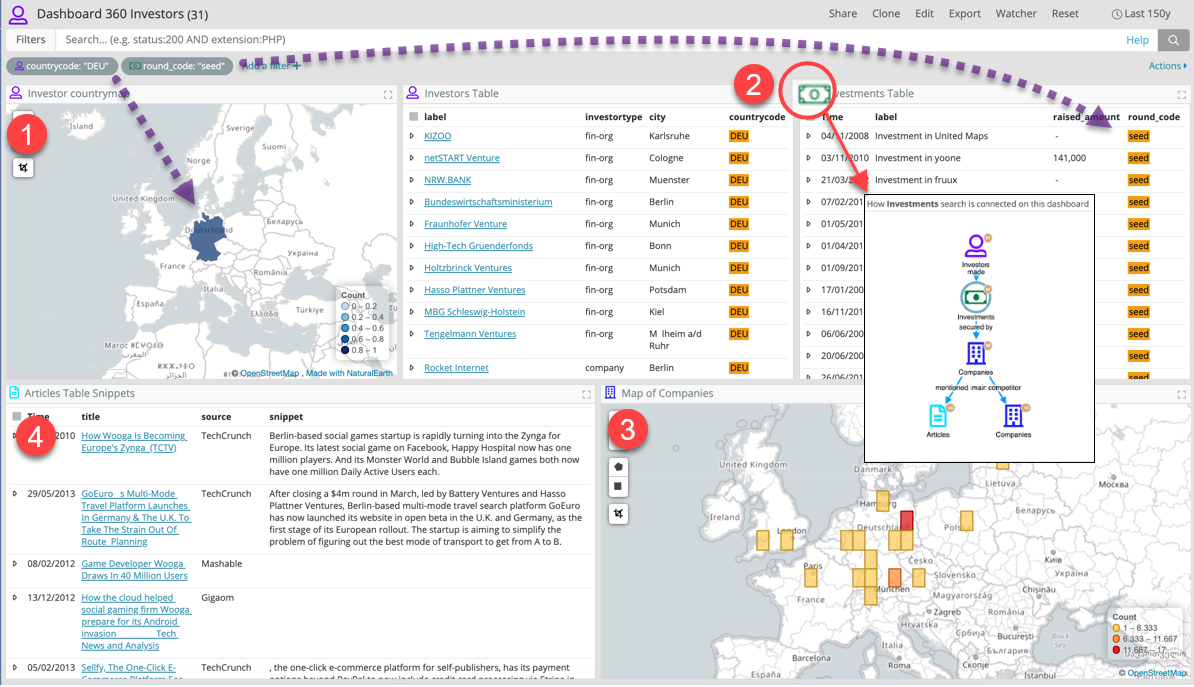
Thanks to the Dashboard 360 feature, this dashboard has several visualizations which live together and react in a coordinated way, despite showing data from different indices:
- Two visualizations on Investors index
- The list of their investment investments
- A map of the companies that have received those investments
- A table of articles that mention those companies
The icon at the top of each visualization represents the search which is used in the visualization (e.g. a dollar icon for “investments”).
Dashboard 360 works by defining a “per-dashboard data model” (relational path) and assigning visualizations to nodes of this path.
Now, when a filter is applied to a visualization, the filter is coherently propagated across all the visualizations based on the data model (so it will be “relationally transformed” to fit “those records that match in the other index”).
In the screenshot, we have applied the ‘countrycode: “DEU”’ filter on the Investor countrymap visualization, and the ‘round_code: “seed”’ filter on the Investments Table visualization.
These filters have been coherently applied to all the other visualizations on the dashboard. So we now see all the Investors from Germany (DEU), with a “seed” round investment, the companies (on the map) that have received these investments, and finally, the list of articles that have mentioned these companies.
To see how each visualization is connected to the dashboard, we simply hover over the icon on top and the data model appears.
In the screenshot, we see the pop-up with the internal data model. This shows how the Investments search is connected to Investors, Companies, Articles and Competitor Companies on the dashboard. We also see the count of each search on the node after the filter is applied.
Siren Dashboards 360 are in beta so let us know how they go for you. We are aware they can be slower than regular dashboards, so we’re working on optimizations that will make them considerably faster in our next release.
Real-time topic clustering for unstructured data (Topic Explorer)
For documents that have text (reports, emails, news articles, and so on), Siren now provides a built-in real-time visual interactive topic and keyword clustering exploration UI which is a critical capability for news monitoring, investigative textual data discovery, and e-discovery.
A picture may be worth a thousand words, and this one moves! (from our classic demo crawled article corpus):
The Topic Clustering is a new visualization in Siren which can be embedded as part of dashboards and interacts with other visualizations creating filters, so you can for example associate it with date histograms or any other control to create great explorative dashboards for your corpuses.
For more information on Topic Clustering, take a look at its own blog post.
Important enhancements
In addition to the introduction of the five AI capabilities, 10.3 also includes the following notable enhancements:
- Siren’s built-in visual knowledge graph exploration now works with intuitive drag-and-drop operations from/to dashboards. This component also has several important improvements including saving of filter states in the dashboard, and faster operation.
- Siren Investigate (our frontend) is no longer tied to a specific version of Elasticsearch and the Siren Federate plugin. This means that you can use the latest frontend with an older backend (no need to upgrade stuff that works perfectly well).
- New connector to multiple remote Elasticsearch clusters which supports pushing down of Siren Federate join queries (do join queries in remote clusters).
- New, greatly enhanced support for Neo4j, including a visual wizard that makes Neo4j data exploration more straightforward.
- High performance, patent-pending caching strategy is now enabled on the Siren Elasticsearch plugin (the Siren Federate technology).
- Scripts can now call datasource queries. For example, Graph Scripts can fire queries to backend directly e.g. to find “shortest paths”, leveraging native graph DB capabilities.
- The Siren platform is now easier to configure and maintain with improved configuration objects granularity and configuration setup.
What’s next?
The team is at work on both Siren 10.4 and Siren 11 at the moment with features such as Elasticsearch 7.x compatibility, much enhanced join and caching capabilities, live Webservice invocation support, dashboard workflows, dataspaces and more.
We will have several articles within the next few weeks talking specifically about each individual stand-out feature within Siren 10.3 and beyond so don’t forget to subscribe to be notified when this takes place.















