
Over the past 18 months we have been at work developing an incredible set of functionalities, some of the most innovative being the work done around building and integrating a large set of artificial intelligence (AI) capabilities – which we will unveil shortly.
In Siren Platform v10.3 (due for release within the next few weeks) and Siren Platform v10.4 five major state-of-the-art AI capabilities will be integrated into our product offering:
- Entity resolution (read below)
- Time series anomaly detection
- Predictive analytics and alerting
- Investigative grade live textual clustering for data discovery
- Investigative grade, full featured natural language processing (NLP)
In this first article I’ll address entity resolution (ER), a possibly lesser-known machine learning (ML) ability but one with extremely useful applications
Siren ER: Match the “same entities” across databases, schemas, languages and cultural conventions
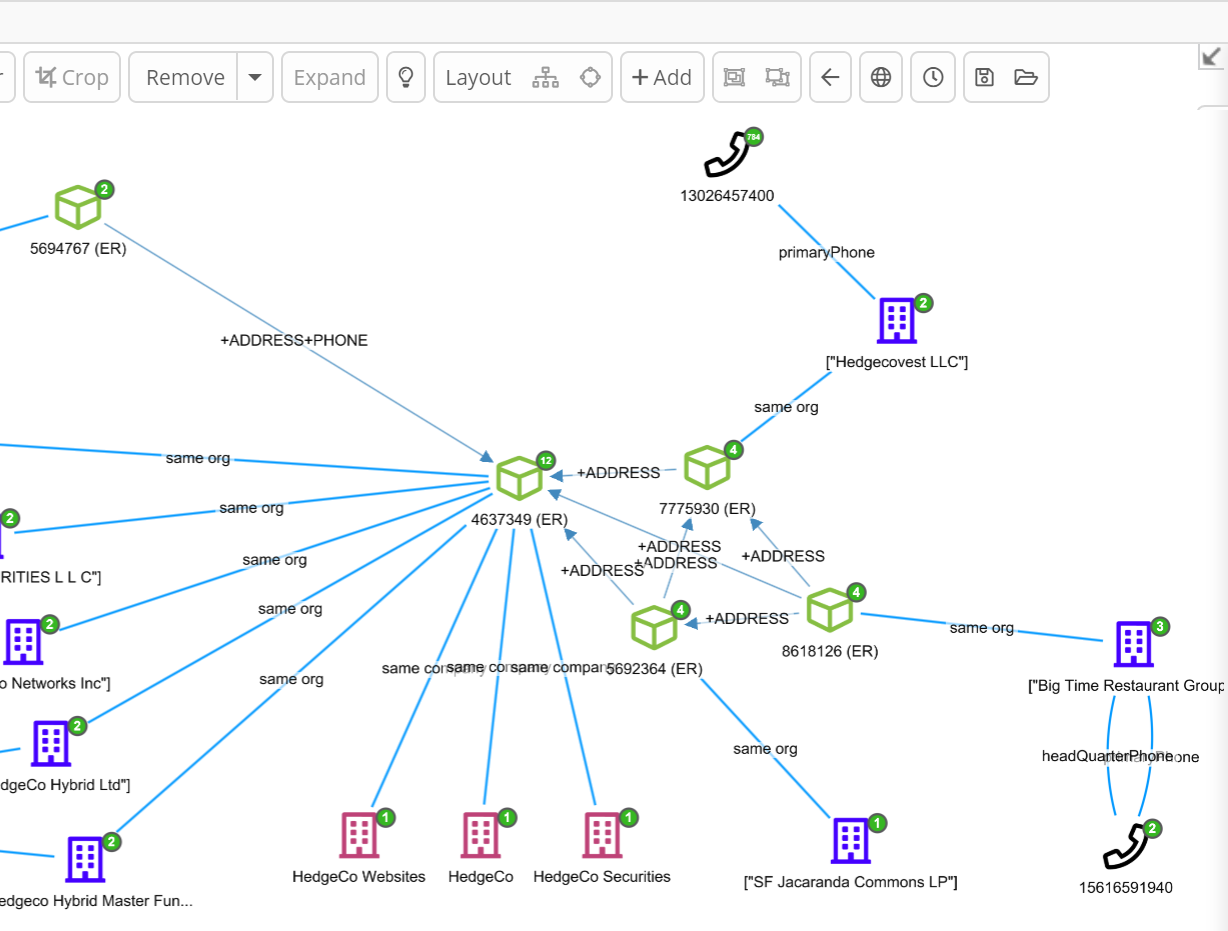
What is entity resolution then? Entity resolution is the AI driven ability to recognize that:
- Two or more records are very likely to be referring to the same real-world entity (person, company, vehicle, vessel, and so on).
- Two or more entities, while not being the same entity in the real world, are “strongly related”. For example, they share one or more highly defining attributes such as addresses, phone numbers or email addresses.
When done right, this is nothing less than an investigative AI superpower with applications ranging from financial crime, know-your-customer (KYC), anti money-laundering and terrorist financing (AML) and Law Enforcement to automated enterprise scale record linkage for many other purposes.
Out of the box, best in class entity resolution across all back ends
Siren ER is capable of advanced and mostly automated real-time operations, with no batch reprocessing required, for the most part out of the box.
Among its abilities are:
- Scanning across schemata and data sources: anything that can be connected to Siren will benefit from this (RDBMS, Hadoop/Spark, Elasticsearch and more)
- Going across languages, cultural conventions and plain human sloppiness: Siren ER integrates decades of R&D to match across dozens of address formats and conventions so that it understands that “Robert” can also be referred to as “Rob” or “Bob” or “Роберц”.
- Correcting previous assertions based on new facts: Siren ER uses both new records to revise previous assertions (see the video below) and automatically assesses the weight of the attributes given their distribution over the data.
In the following short video, I go through a full example of “knowledge revision” and demonstrate it in action on the knowledge graph browser.
Knowledge graph and entity resolution, when 1+1=3
“Entity Resolution” has existed as a standalone capability in various shapes and forms over the years; so has link analysis over curated knowledge graphs (entities which share identifiers). Both are great and highly appreciated capabilities.
However, having them both working together coherently under the same umbrella is a revelation. From our initial tests, data sets which we thought knew well, immediately started to reveal many unexpected and previously unidentified connections.
Our excitement was then superseded by that of customers who for the first time could visually explore across real world fuzzy, incomplete and all the way to possibly maliciously inputted data.
To conclude, “augmented analytics” is a term coined by Gartner to define the next wave of analytics – where AI provides much-needed additional value to traditional approaches. While these definitions are sometimes hard to visualize, with Siren 10.3 we feel we’re making a major step forward delivering this value.
Available in Siren Community and Business editions
Siren ER will be available in the free Siren Community Edition for scenarios which use up to 10k entities while scenarios up to 100M+ of entities are possible in the Siren Business Edition.















