
With the release of Siren 10.2 community edition, Elasticsearch users now have some new (free) options to import data into their clusters.
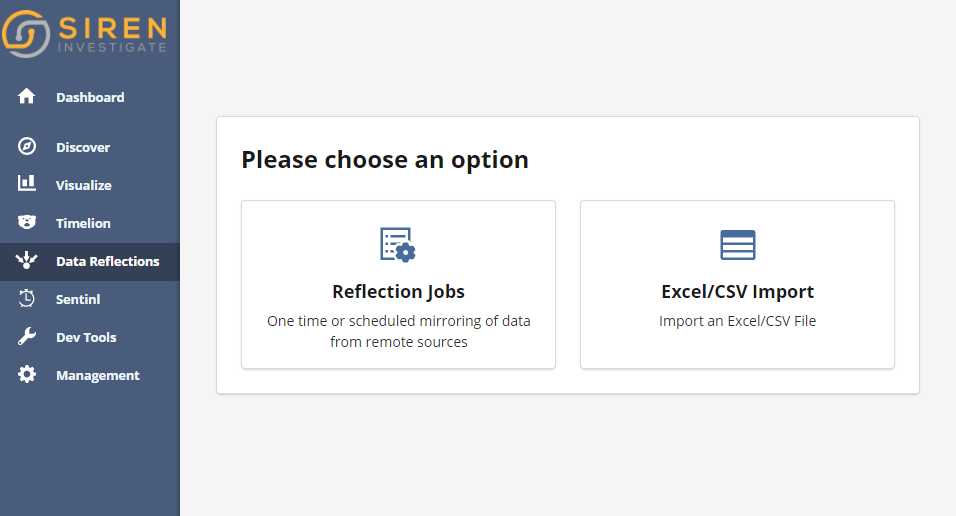
The new Siren data import interface is available right within the Siren UI (Siren Investigate—which can be used with or without Kibana also being installed). You can access it here:

Now, you can choose between Excel/CSV imports (which is what we’ll discuss today) and the “reflection” capabilities (read my previous post, The alternative to ETL – Virtualize or Reflect).
Siren Excel/CSV import provides several significant advantages over other CSV importers:
- Built to support unlimited size uploads; routinely imports gigabytes of data
- Very fast, with bulk, parallel uploads
- “2-click file upload” with saved configuration makes repeated file uploads simple and bulletproof.
- Intuitive UI-based mapping of data, allowing fine-grained control.
- Ability to enrich data while it’s being uploaded, by invoking external services and other transformation scripts.
Import steps
Step 1: Choose a file
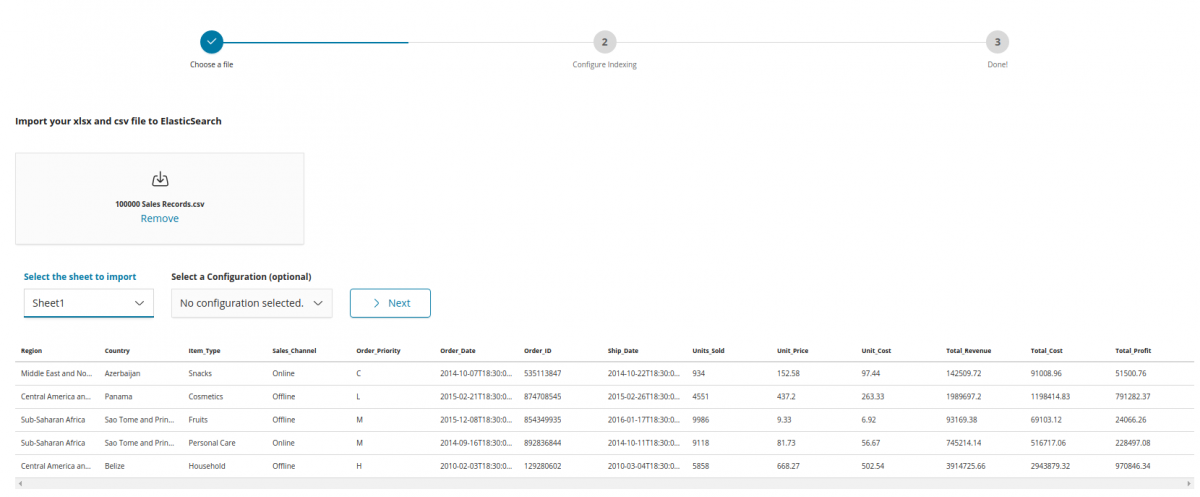
- Select a file.
- Select a worksheet (in case of Excel).
- (Optional) Select a saved configuration to effectively skip Step 2.
Step 2: Configure indexing
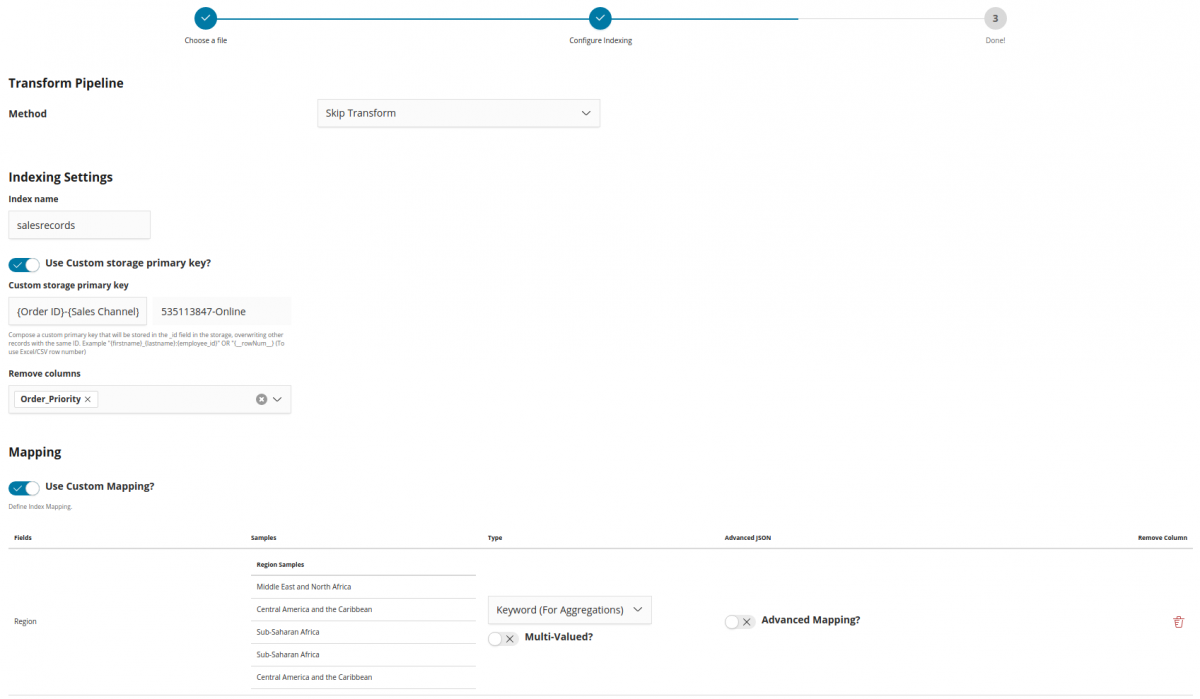
Here you can now define a Transform Pipeline (see examples ). In Siren, these pipelines can also invoke external services for enriching content (such as NLP processors, geo-coding, and so on).
You have also fine-grained (yet simple!) control over the way data is indexed (Elasticsearch mapping). The mapping is auto-detected from the sample data; however, it is possible to import mapping from an existing index or tweak it by, for example, specifying the language analysis parameters (like language) and similar.
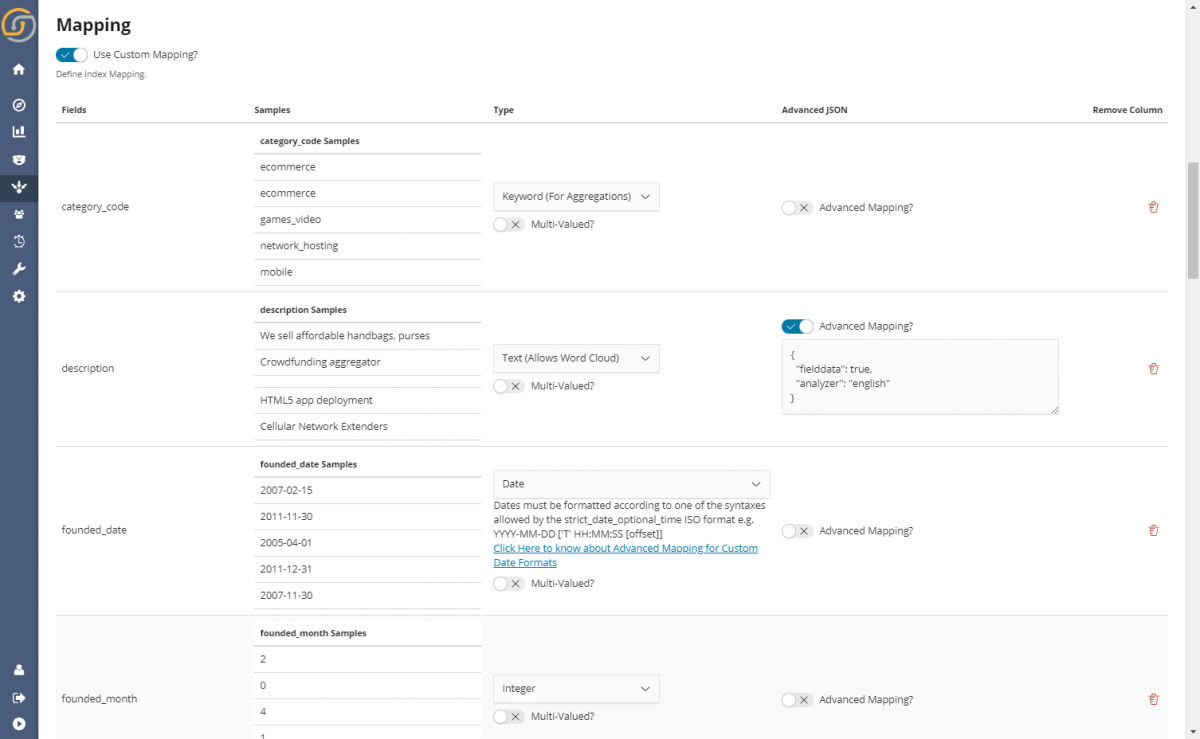
After everything is done, save the configuration for later use and click Import.
Step 3: Done!

This is the job result page; if there are any malformed documents or other errors, they are shown here. This might be a good time to go back to Step 2 and save the configuration (if not already done) or create an index pattern search for the newly imported data.
This is really cool: repeated, “workflow uploads”
It really pays off to do your “mappings” correctly—your data will be showing beautifully and you will get the most value out of it.
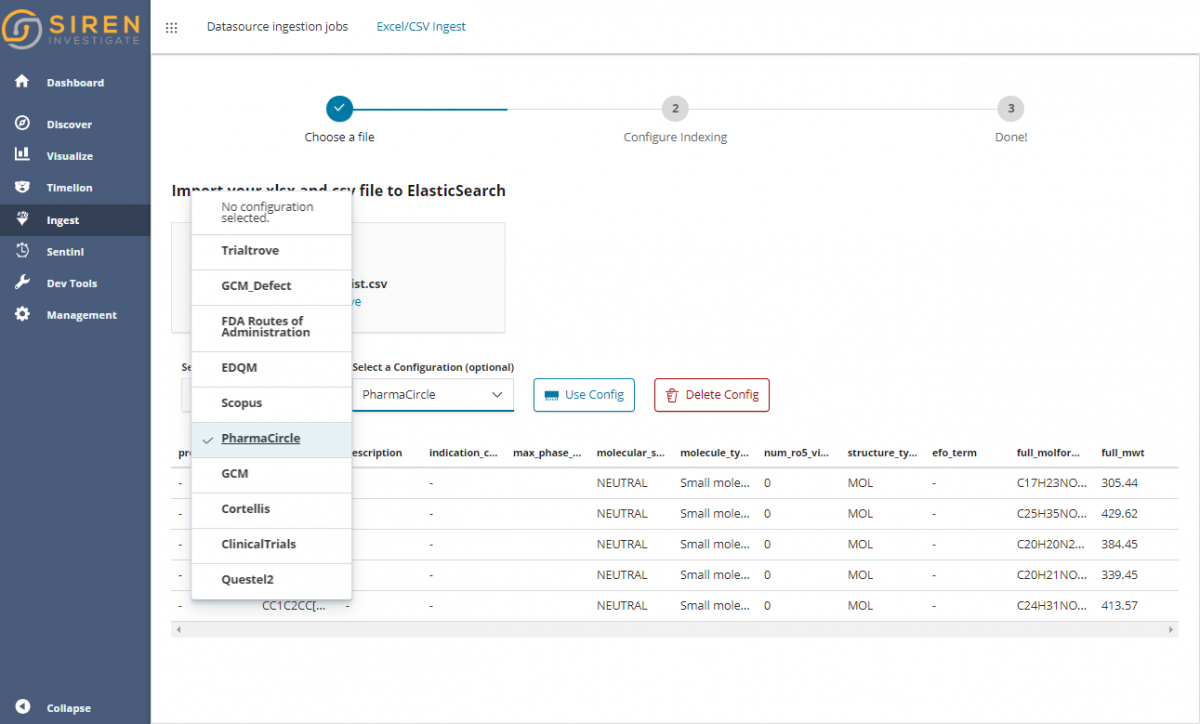
What’s cool is that, for repeated uploads of similar spreadsheets (for example, those that you get from websites that have an “Export to Excel” function), you can save your favorite upload settings into “presets” which are ready to use for your next upload!
Here is how one of our customers ingests fresh data from many well-known life science services, just selecting one of the previously saved configurations.
Why Excel/CSV upload is… much more than this (when you can do joins…)
But really, how useful is it to upload an Excel spreadsheet or a CSV in plain Elasticsearch/Kibana?
Sure, you can make a pretty dashboard and do drill-downs—but honestly, could you not answer one-off questions directly in Excel or a Google spreadsheet simply by using filters or pivot table features?
What changes the game is the ability to do joins.
Say that you upload a list of bad guys (with social security numbers) in Siren. Thanks to Siren relational join capabilities you can do a join and immediately see if any of your customers are in the list.
In practice, once you have relational and semantic capabilities, what was previously simply “uploading a CVS in Elasticsearch” now becomes enabling users contribute to building a cluster-wide knowledge graph. That’s a bit more inspiring, yes? 🙂
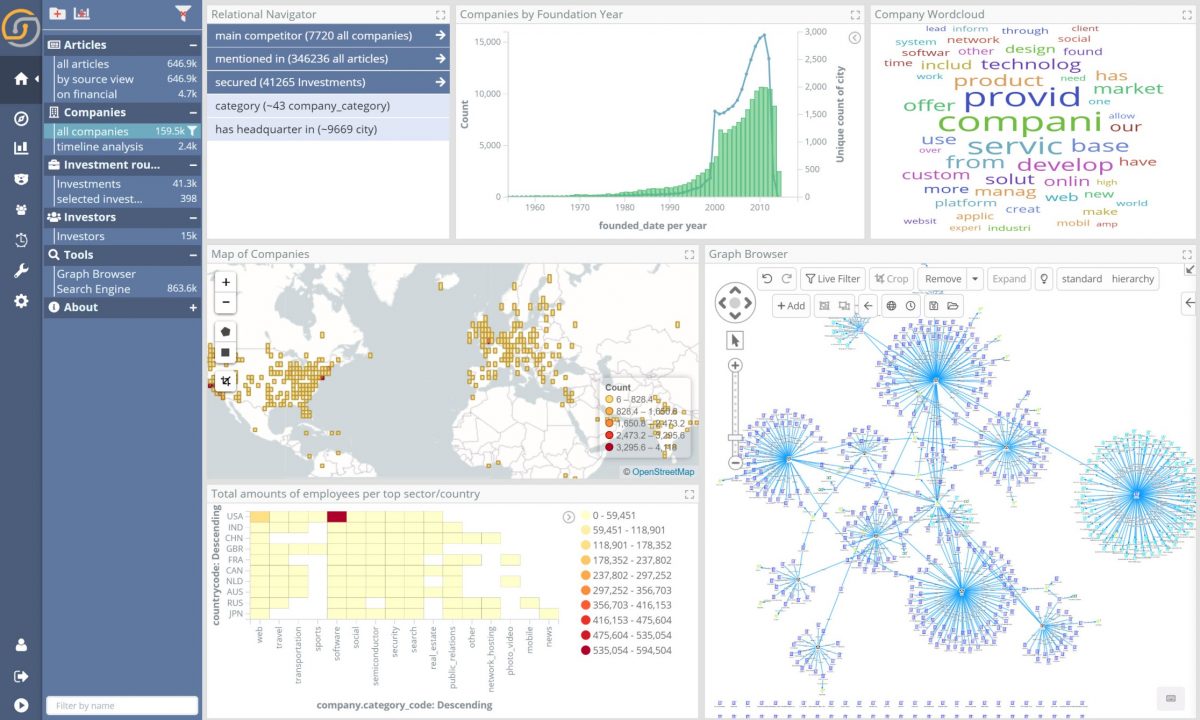
The following screenshot shows a graph of companies and investments, generated simply by uploading the CSV files in our tutorial.
Also read: The alternative to Elasticsearch ETL: Virtualize or Reflect















