Browsing Neo4j data with Siren: For fun and fraud fighting (updated!)
AuthorGiovanni Tummarello
When are graph DBs indispensable?
Many fraud detection systems rely on checking for relationships between domain entities.
To fight review fraud, for example, we might want to discard reviews of an item made by the creator of that item, such as a movie. More subtly, we might also want to discard reviews that were made by his or her friends.
While the above are fixed-length relational queries, which are perfectly suitable in a relational DB, sometimes anti-fraud checks need to use variable-length relational queries. For example, we might want to discard any review from reviewers that are connected by two or more degrees of separation, regardless of the relationship – a friend, a co-writer, a spouse, and so on.
For this last class of queries, graph databases with their traversal-optimized data structures are often the only realistic solution – let alone the ease and flexibility that their graph-centric query languages allow when asking these sort of questions.
Furthermore, graph databases are great at calculating other important queries that return the importance of nodes with respect to centrality and other useful node and network metrics.
Support for graph databases in Siren Platform 10.3: The new Import Wizard (beta) for the Neo4j connector
Siren Platform version 10.2 introduced Siren’s first level of support for graph databases. Siren 10.3 introduces a simple and intuitive import wizard that makes it easy to import data from a Neo4j datasource, without the need for external command line operations.
This might be surprising: Have we not already demonstrated that to get the benefit of knowledge graphs, you don’t need to move all of the data to a graph database?
Yes we have.
In the Siren Platform, you can simply connect the tables of any RDBMS (or Elasticsearch or other back-end table) and, by using the definition of a simple data model, you can enjoy scaled navigation, examination, search, and visual link analysis. (See our videos for more information).
However, as discussed, there are use cases where graph databases are very useful. And for these we now have a connector.
Now, with Siren Platform you can:
Connect to a Neo4j database and browse its data in Siren dashboards, with full-speed, set-to-set relational navigation, explorative link analysis, high quality textual discovery, and alerting.
See Neo4j data interconnected with data of other systems. Do you have your users or assets mapped in Neo4j, your big web or infrastructure logs mapped in Elasticsearch, and your inventory in Oracle Database? Ask questions across data sets without moving the big data from where it is!
Use Neo4j’s unique power to find the shortest path, cycles, and calculate graph metrics, all while using the power of the Siren back-end system (our supercharged Elasticsearch ) for ultra-fast analytics and search.
Since our graph database support is in its early stages, there are some limitations that we’ll discuss toward the end.
How it works
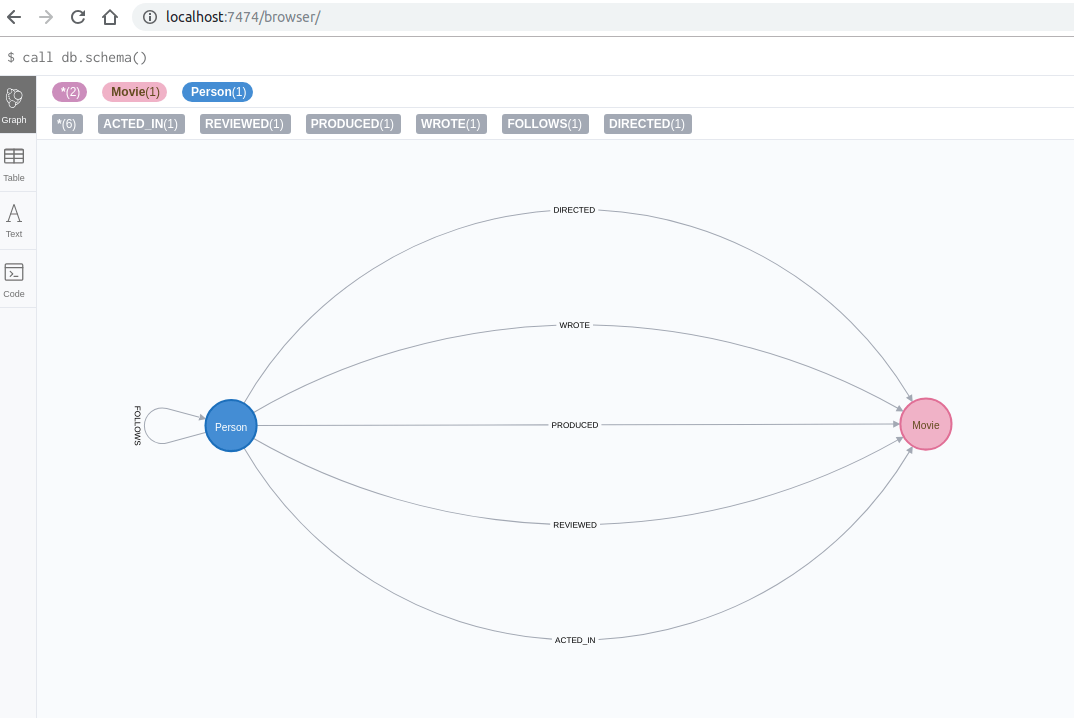
A graph database like Neo4j uses a model known as a property graph. This is data stored in either edges or nodes, which can be considered much like database tables that are relationally connected to each other. In Neo4j, nodes or edges can contain JSON syntax, so the database allows complex fields.
Siren Platform version 10.2 includes a Neo4j datasource, which can be used for reflection jobs. This can be used to stay in sync with selected slices of Neo4j, where one slice represents a node or an edge type.
While Siren 10.2 required you to run a script to create reflection jobs for Neo4j, Siren 10.3 offers an easy to use Import Wizard that automatically creates them for you.
The Import Wizard does the following:
Analyzes the Neo4j schema to assess which types, relations, and which attributes for types and relations exist.
Creates a series of reflection jobs. These are scheduled jobs that create for each relation or type a corresponding populated index in Siren Platform. These reflection jobs can be executed on a one-off basis or can be scheduled to automatically rerun.
Creates the data model in Siren Platform:
It creates an index pattern searches for each node or entity type. From here, it is easy to create analytic dashboards and visualizations.
It populates the relations in the Siren data model with the same relations those entities and node records have in Neo4j. This enables relational navigation across dashboards and in the Link Analysis tool.
Once this procedure is executed, dashboards can be generated in Siren Platform from the data now contained in index pattern searches and graph analytics can be executed.
Prerequisites
A Neo4j database with data in it.
A Siren Platform installation, such as the “c10”>Siren Community Edition. If you’re trying out Siren Platform for the first time, we recommend that you download the “no data no security” package.
Download Neo4j Driver and install the driver on the Elasticsearch node, by placing it in the ‘elasticsearch/config/jdbc-drivers‘ directory. Note: Make sure you have ‘node.attr.connector.jdbc: true‘ in the config/elasticsearch.yml file of that node.
Step-by-step example
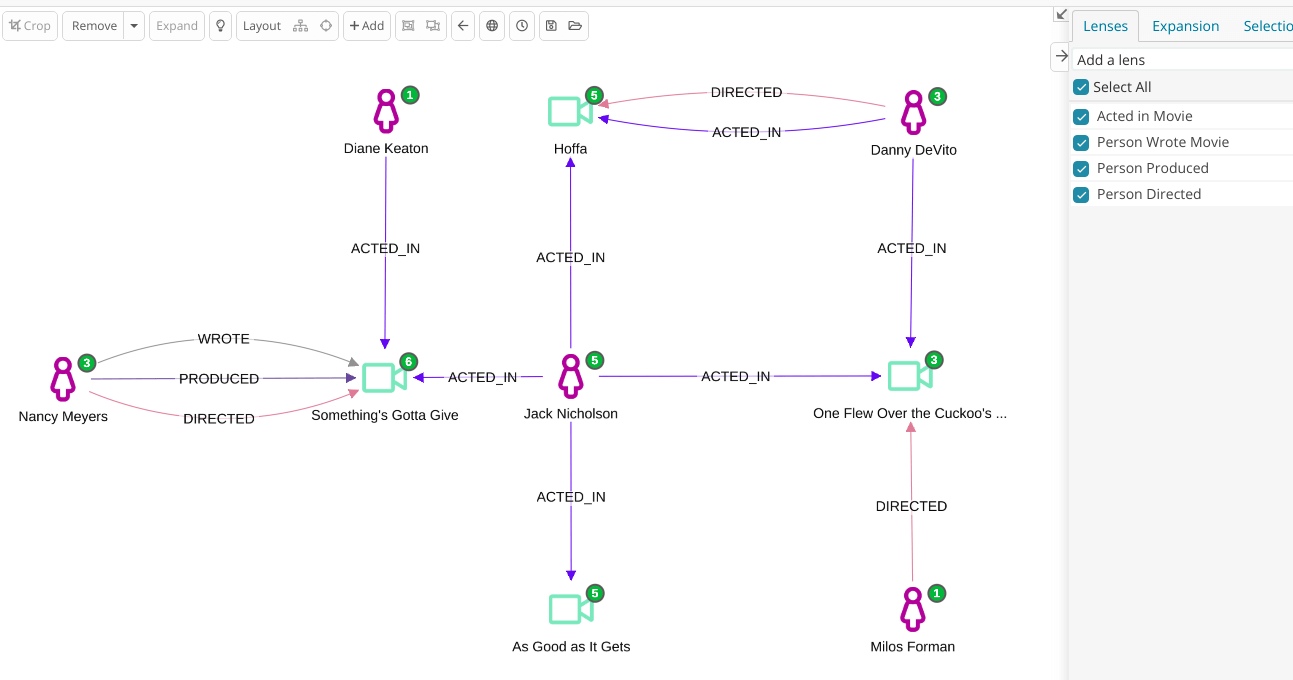
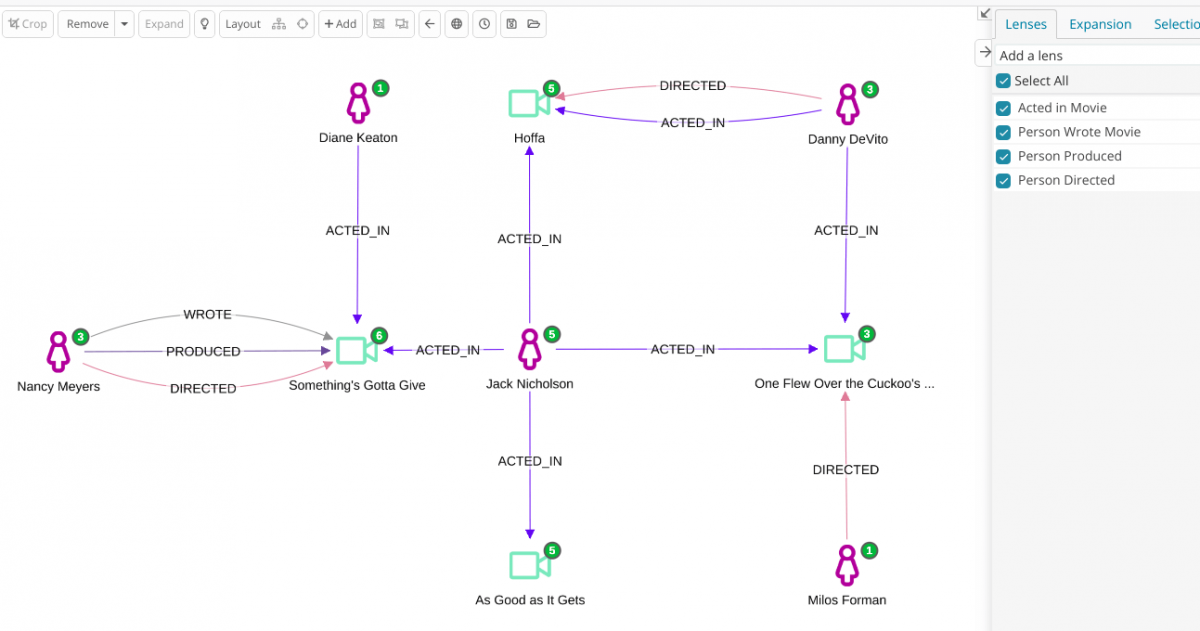
In this example, we will detect review fraud by using the following schema:
Specify the details for the Neo4j as the datasource, then click Save.
Now go to the Data Reflections tab and click Reflection Jobs and add a new job.
Select Neo4j as the datasource; you will now see an option to use the Neo4j Importer.
Click UseNeo4j Importer. The Neo4j Import Wizard screen opens.
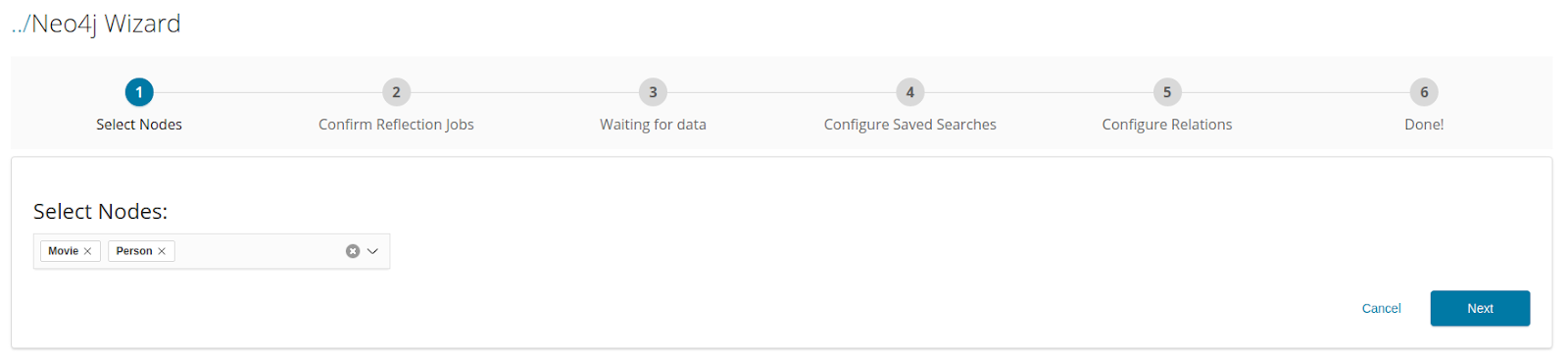
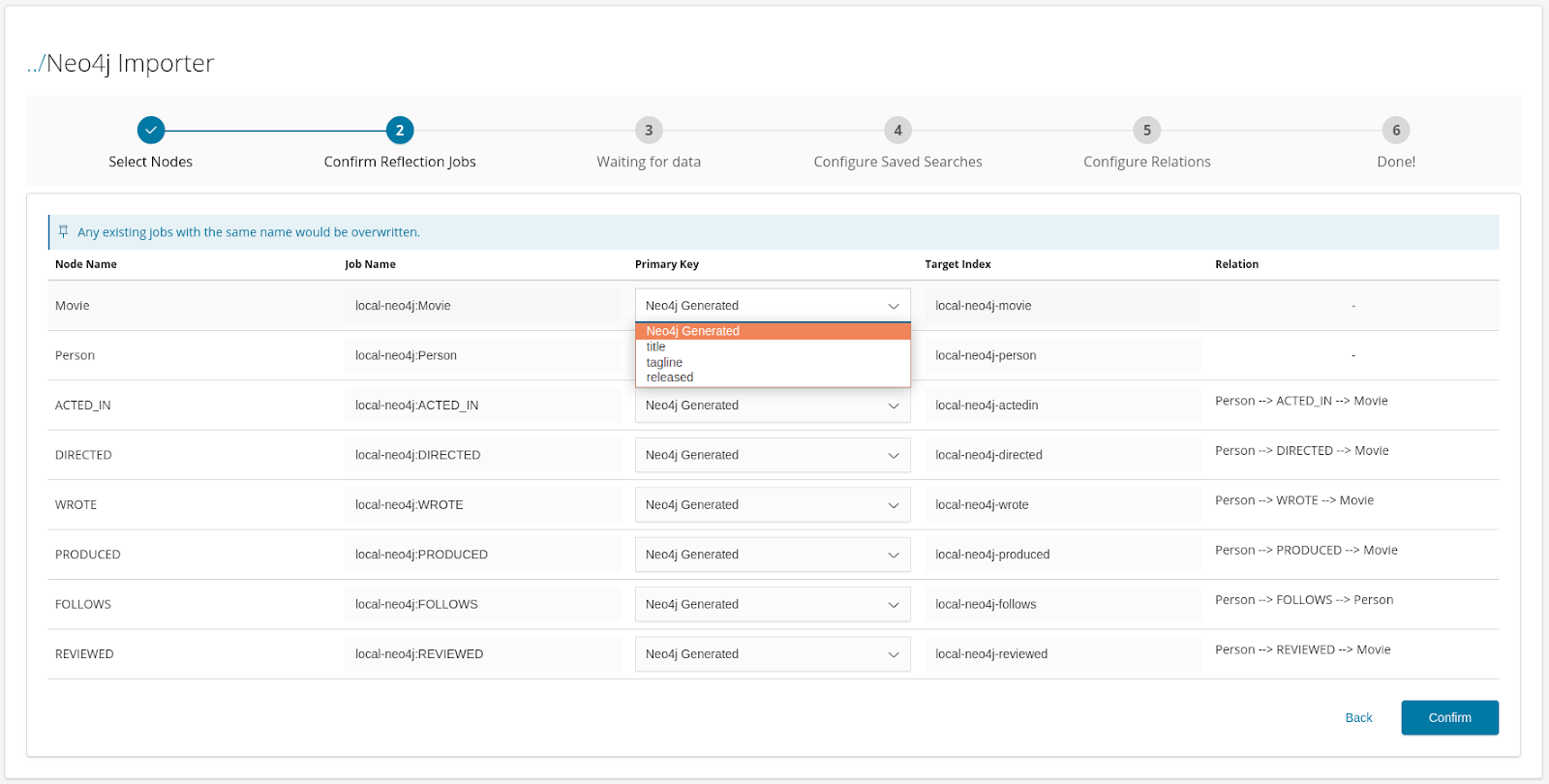
Select the required nodes from the Select Nodes dropdown, and click Next. All data reflection jobs for nodes and relations are displayed. Note that relations are also listed under Node Name; this is because Neo4j relations contain data, and Siren Investigate runs a reflection job for each relation, just like a node. Note: Ensure that an appropriate primary key is selected. The use of stable unique identifiers as primary keys in your Neo4j data model is recommended.
Click Confirm.
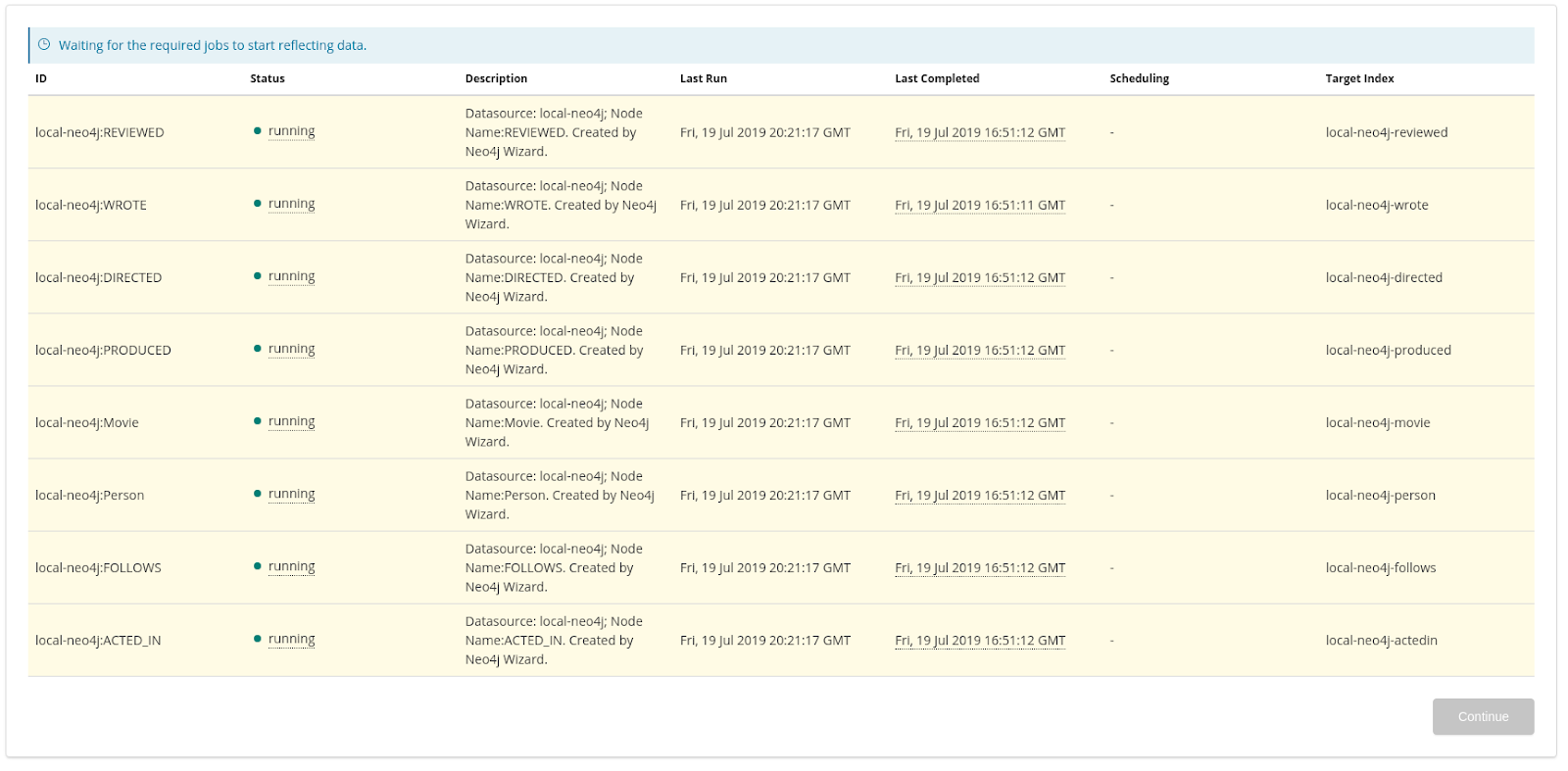
Wait for the data to start reflecting, which means that all jobs have indexed at least one document, indicating that the fields are mapping successfully. The Continue button becomes enabled at this point.
While a job is indexing, its status is shown as running; when a job completes, the status changes to successful. You can leave the wizard at this point (by clicking on top left of the wizard, or anywhere else in the application). This may be necessary if reflection jobs are failing
You can continue where you left off by following the notification in the Datasource Reflection Jobs page. Click Pending Jobs.
Click Continue Neo4j Job. Note: Pending jobs are stored in server cache, which will be wiped out if the Investigate server is restarted or shut down. Its behaviour is unpredictable when multiple Investigate instances are running behind a Load Balancer.
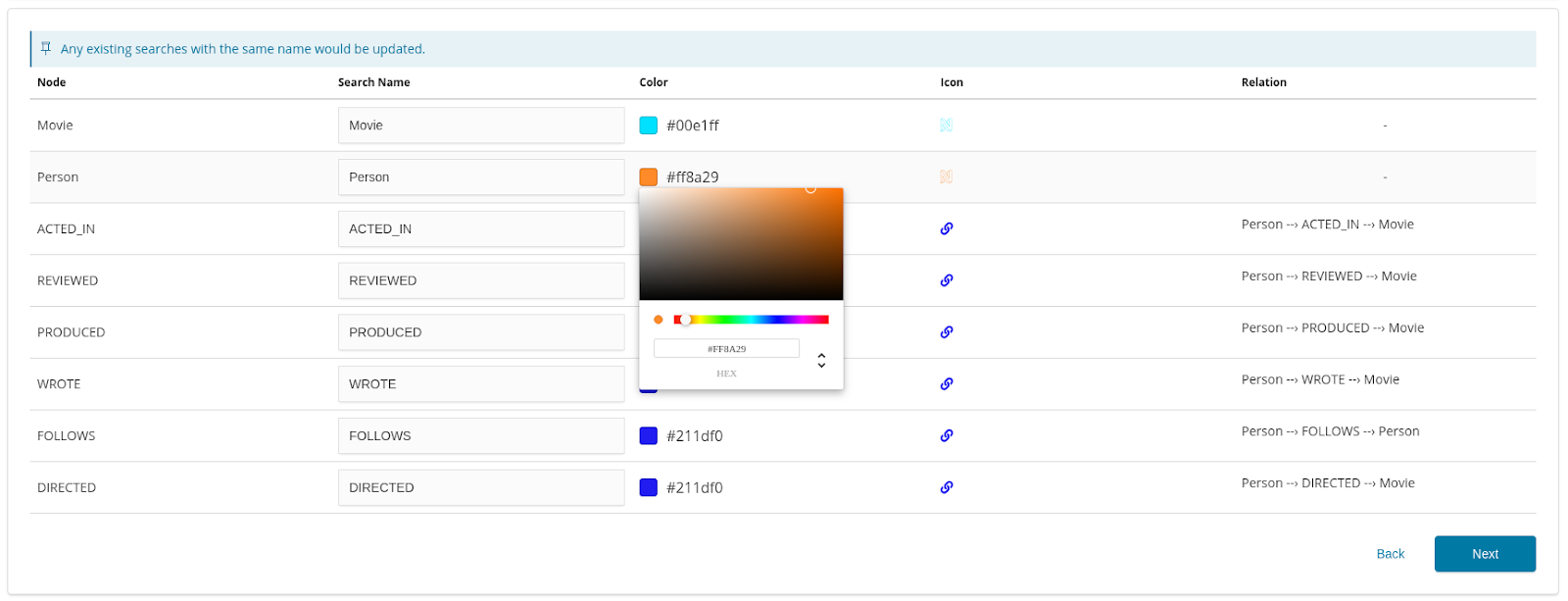
On the Configure Saved Searches screen, you can modify the search name, and specify a color for the nodes and relations: Click Next.
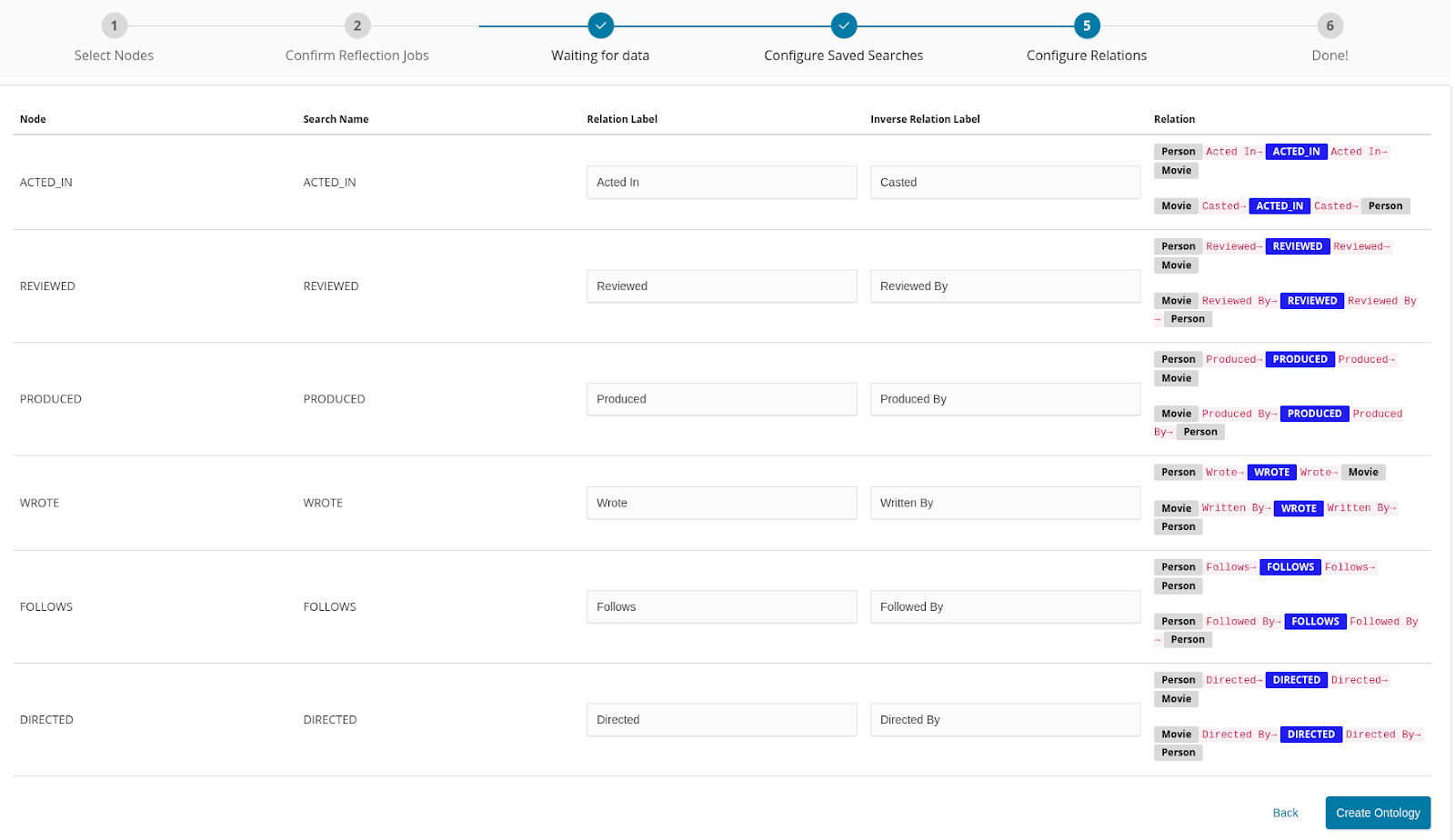
On the Configure Relations screen, you can modify the Relation Label and the Inverse Relation Label for each relation:
Click Create Ontology.
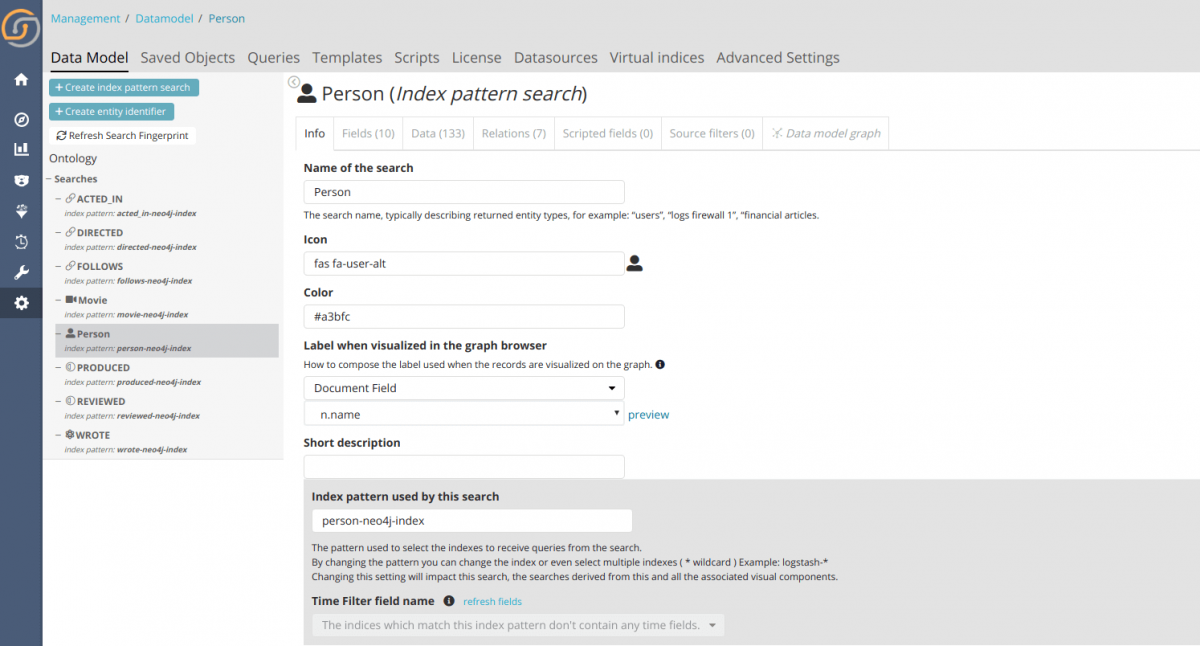
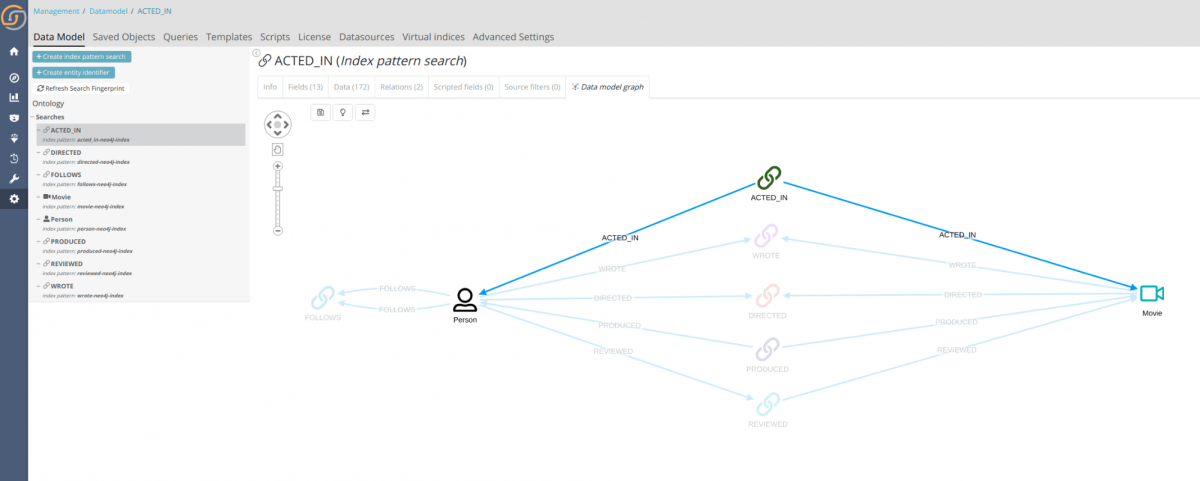
Return to Siren Platform and go to the Management tab → Click the Data Model tab, where you can see all indices that were created and all of the relationships that were found. From this screen, select icons for each search and enter a label in the Label when visualized in the graph browser field. Click on the data model graph tab to see the data model. It is recreated in Siren Platform automatically from the Neo4j structure.
Creating dashboards and navigating the graph with Siren Platform link analysis
Now that Index Pattern Searches and a relational data model is in place, all you have to do is to create dashboards and use the Link Analysis navigator.
However, the quickest way is by using our automatic dashboard creation wizard:
In the Management app, click the Data Model tab and select the search that you want to create a dashboard for.
Click the Data tab and either select the fields that you’d like to create widgets for or simply click Autoselect Most Relevant.
Click Create dashboard.
Repeat steps 1-3 for other index patterns of interest. You might want to do this for what previously were edges, such as “acted_in”. This will give you the dashboard-to-dashboard navigation capabilities.
Now, you can explore Siren Platform’s unique link analysis capabilities:
And now… Let’s hunt down the fraudsters
As we mentioned earlier, the main reasons to use graph databases are to run arbitrary-length path queries efficiently or to execute graph metrics.
In fraud detection, an investigator might want to detect a suspect circle of users. For example, users that are connected to each other by at least two fraudulent hub nodes.
Neo4j is efficient at calculating large-scale graph metrics, such as centrality, page rank and others. These can be useful metrics to assess the relative importance of a node.
How can you avail of these capabilities in Siren Platform?
For pattern detection
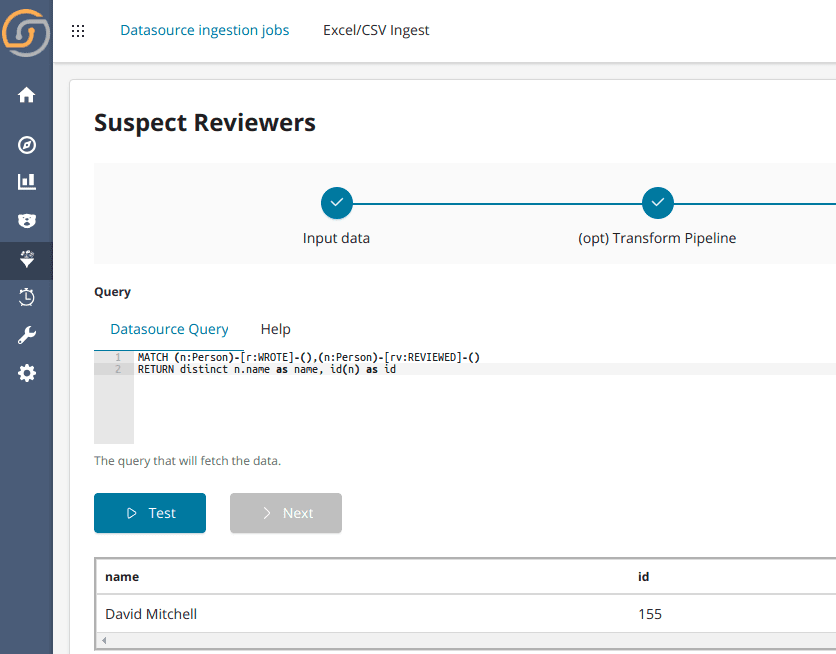
You create a new data ingestion where the pattern-detecting query (in cypher) is used as the input.
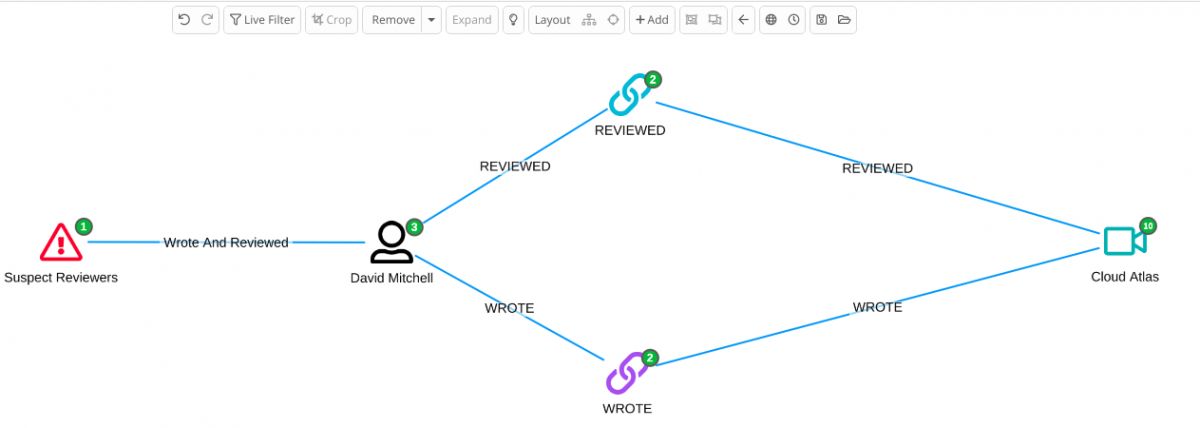
This creates an index in Elasticsearch with a list of suspects. The query can then be re-executed manually or automatically by implementing scheduling.
In the example below, we specified a datasource query to identify “reviewers who are also Authors”:
After this special data ingestion is performed, you create an index pattern search for this newly created index. In the data model, you link the keys to the records that have already been ingested, for example, link the table “suspect_circles” and the field “IDs” with the “persons” field ID.
These results are easy to use in Siren Platform, both in dashboard-to-dashboard relational navigation and on the graph. For example, simply import the query result index in the graph and expand it to reveal the records that are involved in the circles.
You can repeat the procedure for as many fraudulent patterns as required. And the data reflection jobs can be scheduled to run at set intervals.
For graph metrics to be shown in Siren Platform
You can modify the reflection jobs that you have created to produce a graph metric result, such as centrality, which is written as an extra field at the reflection phase. This can then be leveraged in dashboards or on the graph, for example, you can use it in a lens to make a node look bigger.
Firing a Neo4j query from the Siren Platform
Siren 10.3 provides the ability to trigger Neo4j queries directly from its graph browser. You can write as many scripts as you like and invoke them from the Graph Browser’s “Contextual Menu” (available on right click).
Here are the steps to add the shortest path query script to the graph browser and find the shortest path between 2 or more (Neo4j Reflected) data nodes.
Use the Neo4j Wizard to import your Neo4j data.
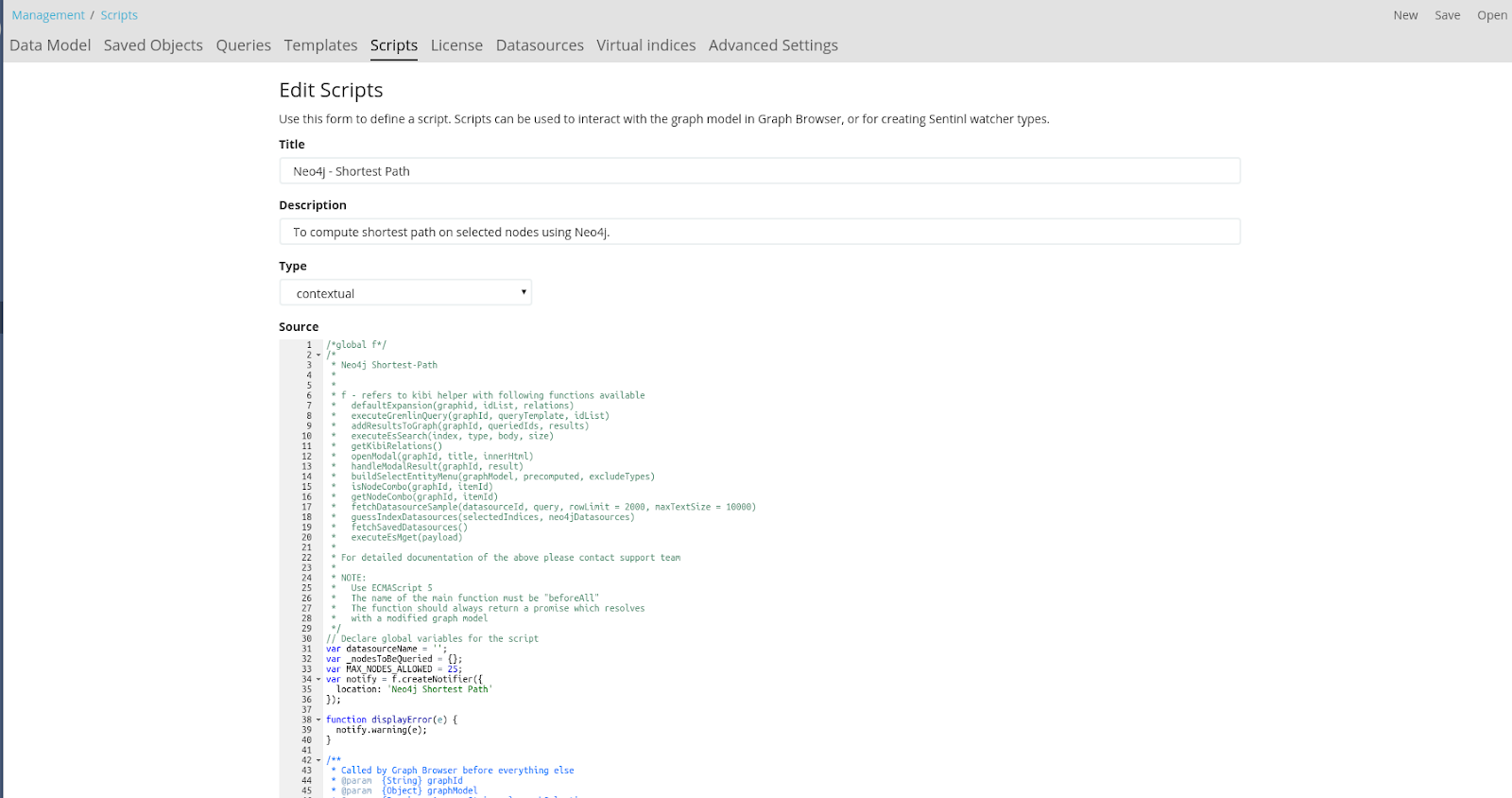
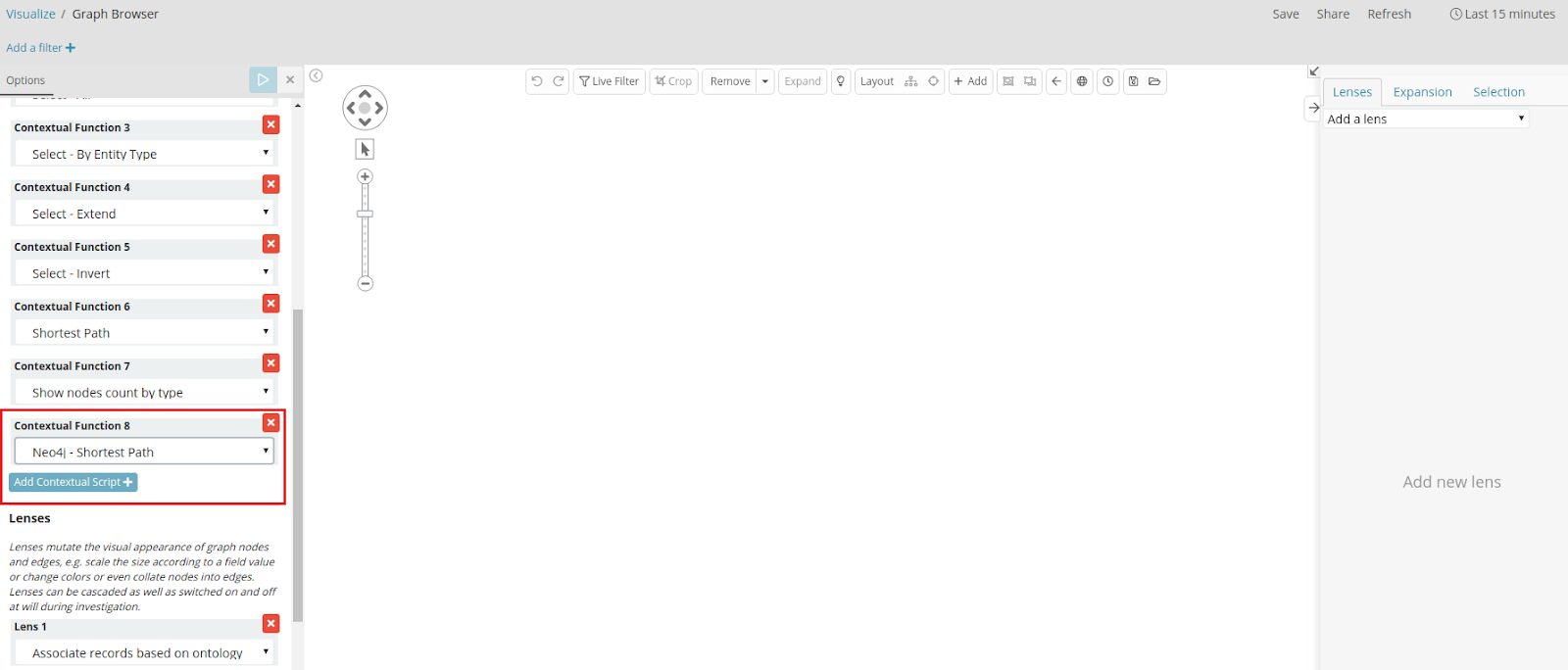
Navigate to Management → Scripts and create a new script by selecting the Type “contextual”, paste the script provided here in the Source section and click on “Save”.
Go to the graph browser and click the Edit button at the top panel to enter edit mode and click the edit option on the graph browser. On the Options tab on the left, click on the “Add Contextual Script” button under the Contextual Function. Select the newly created script from the drop down button to add it to the graph browser.
Click on Save. You can now use this script to compute shortest paths between your selected (Neo4j Reflected) data nodes.
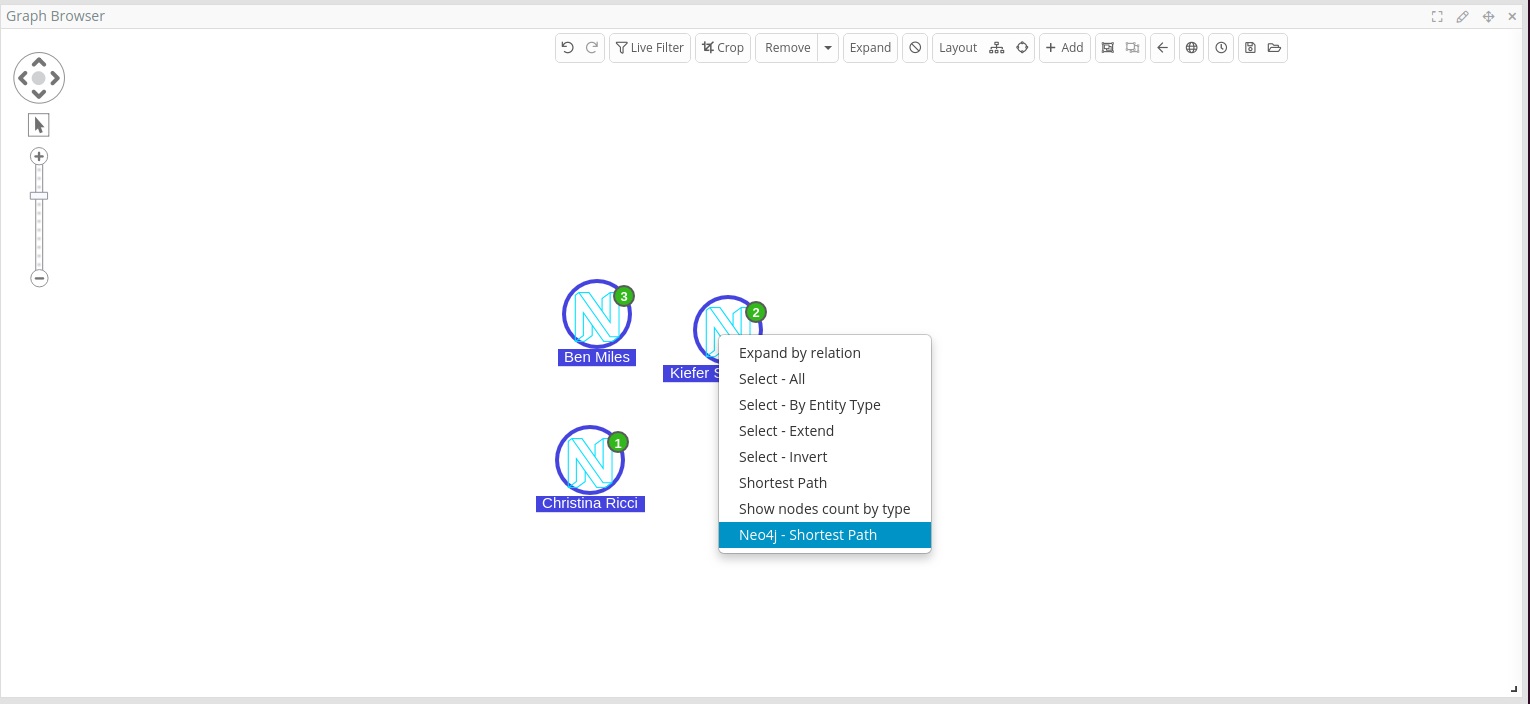
To run the query script, simply add the Neo4j reflected nodes on the graph browser, select the required nodes, right click and select “Neo4j Shortest path” (the name of the script).
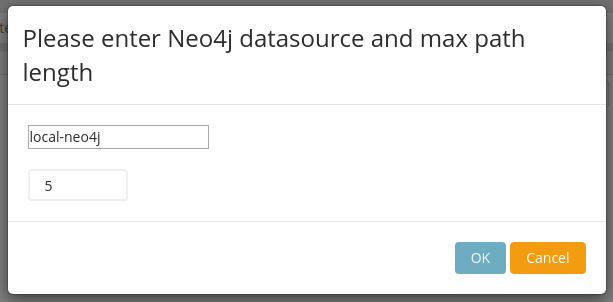
Enter the maximum path length and click OK.
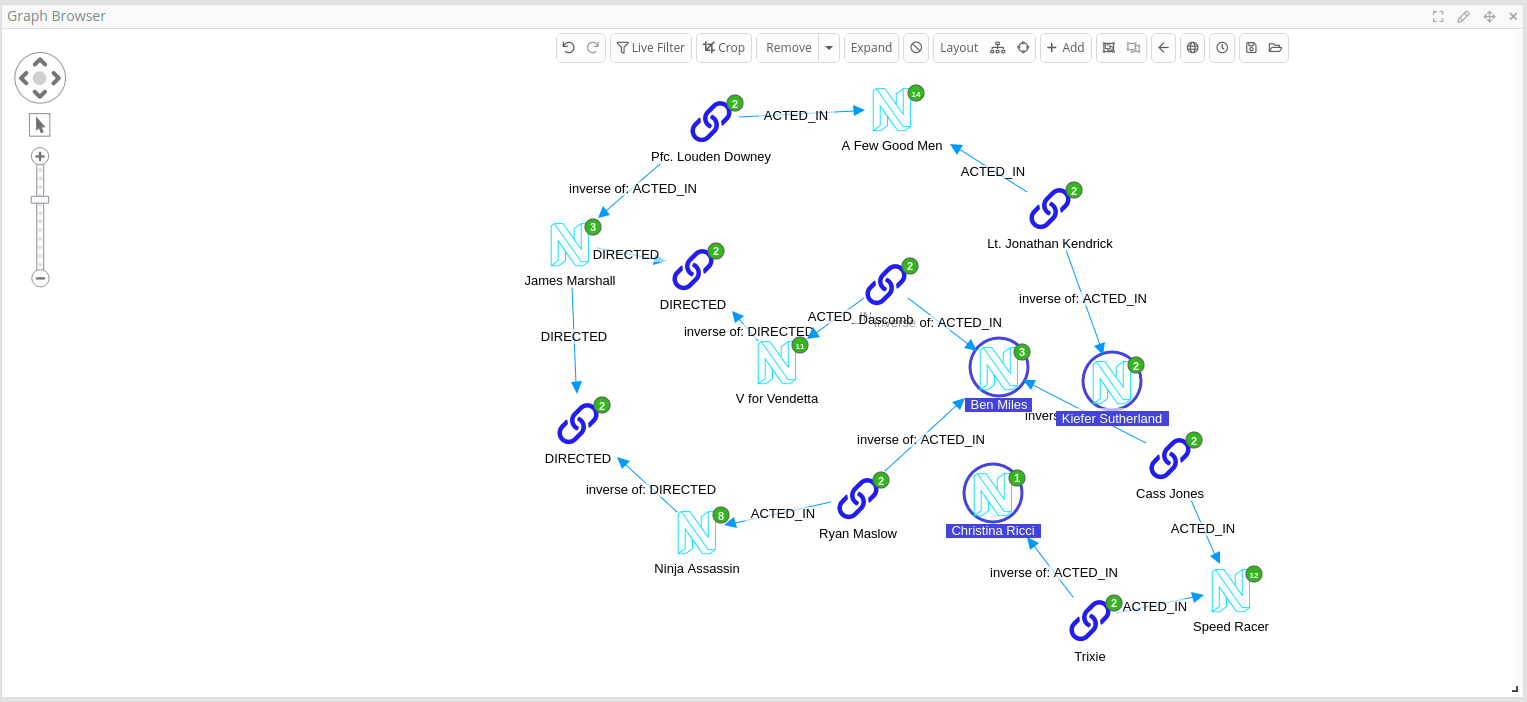
You will see the shortest path between the nodes appears.
Conclusion: Using the best tool for the job
In the past two years, graph databases have gained more and more momentum. While, occasionally, one might encounter some very far-reaching graph database projects, it is clear that IT departments won’t be ditching Hadoop, Spark, or Elasticsearch for big data logs anytime soon – nor should they.
One of Siren Platform’s unique and exciting aspects is that it allows navigating knowledge graphs without the need for an extract-transform-load (ETL) process for graph databases.
In the Siren Platform, the graph is in the data you already have and you can also leverage the back-end system that you already use. For more information, see our blog post about Siren Platform’s “virtualization or reflection” capabilities.
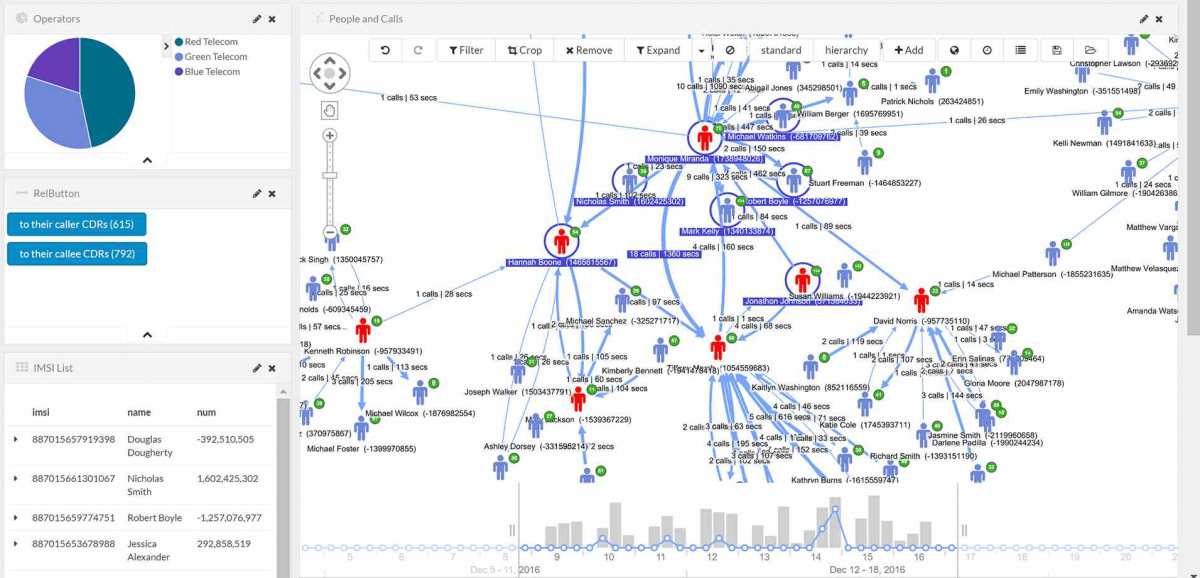
For example, the following screenshot shows aggregates on call data records that are stored in a connected Elasticsearch index. In this case, no graph database was used:
We are excited to share our support for graph databases with the popular Neo4j.
Siren Platform can now employ “the best tool for the job” for financial fraud detection, law enforcement, intelligence, and more.
For the end user, the boundary is invisible: one sees data which is in graph DBs simply connected to that which is in other back ends, both in the link analysis and in Siren’s signature “dashboard to dashboard” navigation.
What’s next?
We have a rich road map of improvement with respect to graph database support:
Introduction of experimental support for other graph databases.
Siren Platform version 10.4 (Q4 2019):
Ability to use live parametric queries in the UI as part of our forthcoming new generic web service support.
Ability to use the graph database superpowers on data that was originally in other systems. This is made possible by pushing selected “slices of data”, such as the relational skeleton into a connected graph database.
Do you like what you see? Would you like to see support for another specific graph database?