

Announcing Kibi: a Kibana fork for Data Intelligence
We are very excited to announce Kibi (pronounced Kee-bee), a friendly fork of Kibana for Data Intelligence use cases.
For those new to it, Kibana is an amazing product by Elastic which enables search, browsing and analytics on documents stored in Elasticsearch indexes through an intuitive user interface.
Kibi: For Data Intelligence
Kibi has been developed to extend the ELK stack with cross-index relational capabilities, suited for data intelligence use cases like:
- Security and IP intelligence: display which servers are being attacked by a set of malicious IP addresses, stored in a separate index.
- News/Financial Intelligence: perform analytics on companies mentioned in social media streams, news feeds and analysts reports; show related financial information over a custom time period.
- Business Intelligence: what are the most purchased products by customers that during any email or support interactions have mentioned the name of a competitor in the past quarter?
- Life Science: browse targets, references, formulae and molecular structures related to the papers from a specific author.
- Law Enforcement: display informations about suspects and offenders, extends your search by filters created by querying an external high performance graph store.
- Internet of things, sensors data: display the location of the sensors on a map, restrict the visualization to a specific area, then display all the communication logs generated by the sensors in the area in real time.
- Legal Practice Management: display all the information about the cases related to a specific topic, outcome or time, then drill down on related cases.
- Mobility planning: perform analytics on vehicle behaviour by joining traffic data, vehicle registration numbers, driver licenses and violations, e.g., see the top five violations from drivers under 30 years driving a car with a power above a certain threshold in the past year.
- Local authority planning: related building permission documents with information about architects, owners and nearby buildings.
In these scenarios, data is spread across multiple Elasticsearch indexes; the indexes are joined by Kibi at runtime through the SIREn Join plugin for Elasticsearch, which is included as a pre-release in the Kibi demo distribution; the plugin will be released as a standalone product in the coming weeks.
In addition to join capabilities, Kibi allows to augment data stored in Elasticsearch by querying SQL and SPARQL sources; query results can be displayed through templates and can be used to filter Elasticsearch results.
Taking Kibi for a Spin: Our Demo on Startup Market Intelligence
The Kibi full demo distribution comes preloaded with 600k+ Articles, harvested a few years ago from technical blogs, plus data about startups from the CrunchBase 2013 Snapshot © (Companies, Investment rounds and Investors). See our screencast.
The data is stored in four Elasticsearch indexes which can be related on a specific set of keys:
company |
a collection of companies |
article |
a collection of articles about companies; each article refers to a specific company by id |
investment |
a collection of investments in companies; each investment refers to a specific company and a specific investor by id |
investor |
a collection of investors |
By default, Kibi will display the Articles on dashboards that can be configured to display multiple visualizations on the documents stored in a specific index or returned by a saved search on an index.
In Kibi, each dashboard is represented by a tab containing the dashboard title and the number of documents available to visualizations.
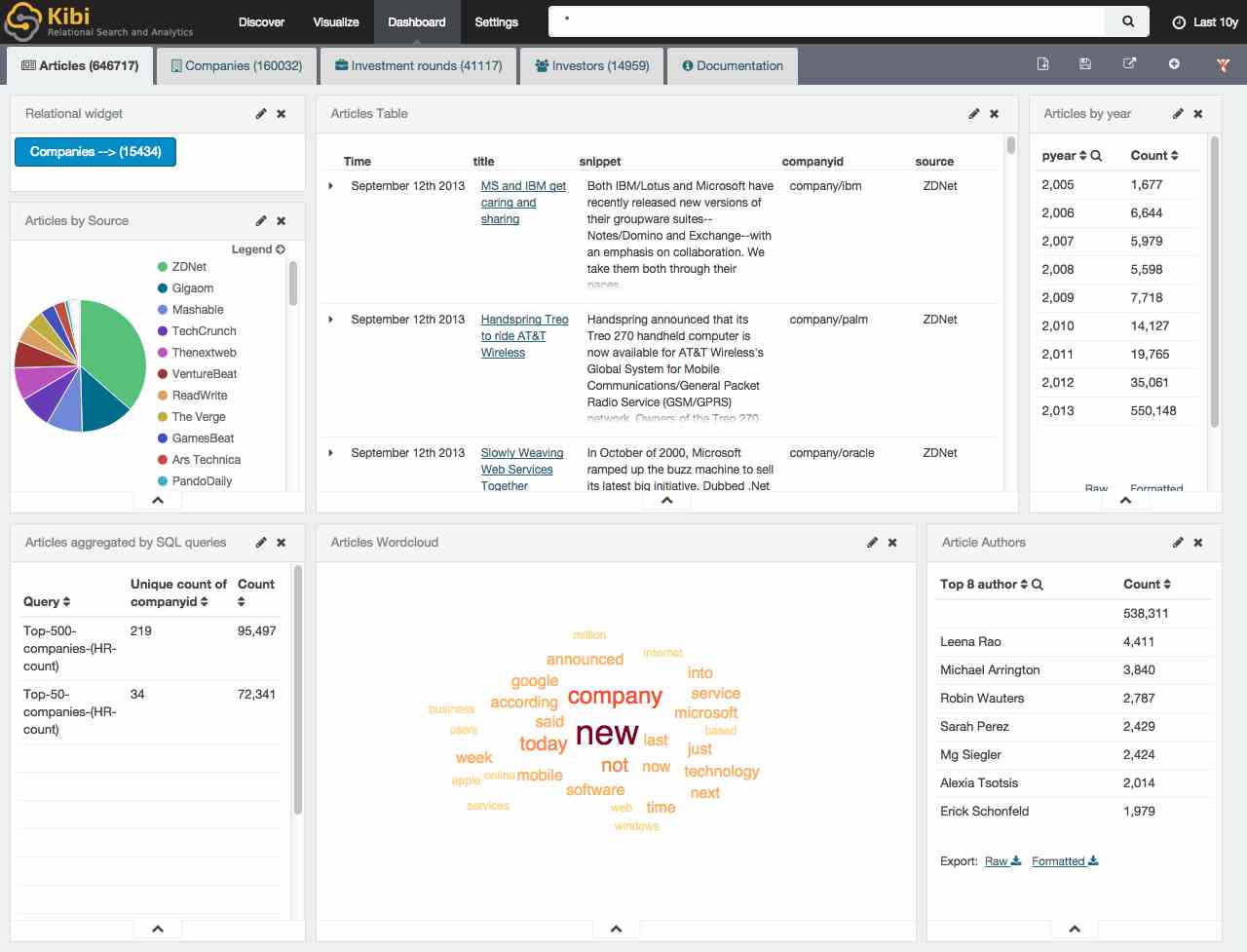
Relational filters
Kibi inherits filtering capabilities from Kibana; for example, click on a slice in any chart and all the visualizations will be filtered accordingly; in addition to filters on the current dashboard, Kibi allows to define filters across dashboard; for example, after performing a search for articles mentioning “wireless OR wifi”, we can see right away that there are “96” companies mentioned in the currently selected articles (558).
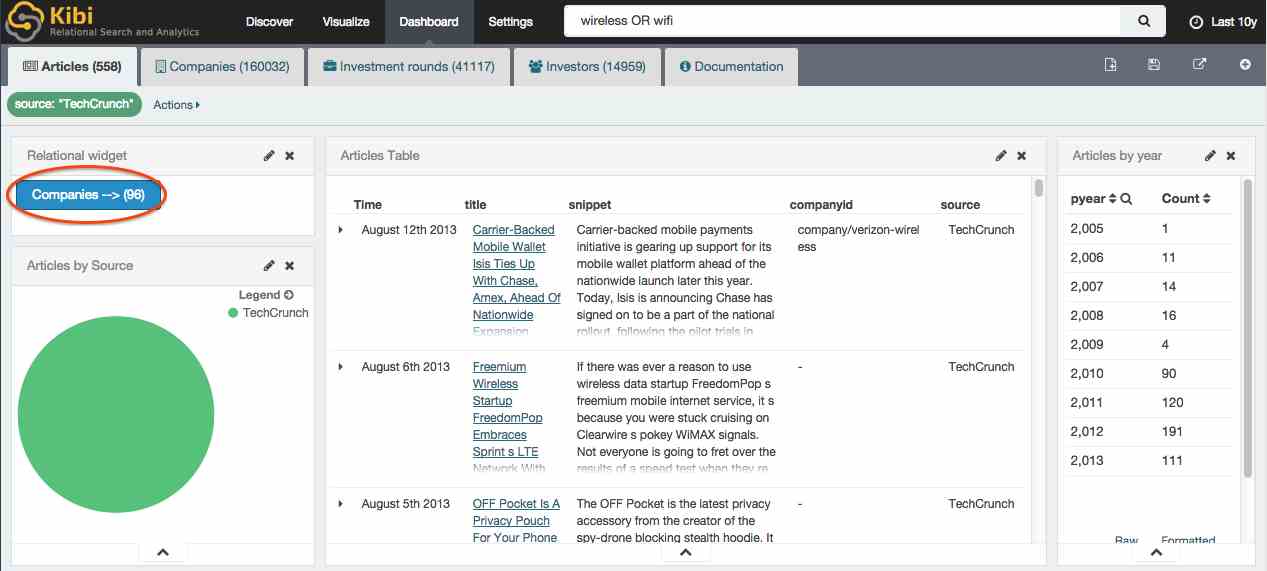
Want to know more about this group of companies? Just click on that button and Kibi will switch to the Companies dashboard and visualize the data about these 96 companies, filtered by the “..mentioned in Articles” relational filter:
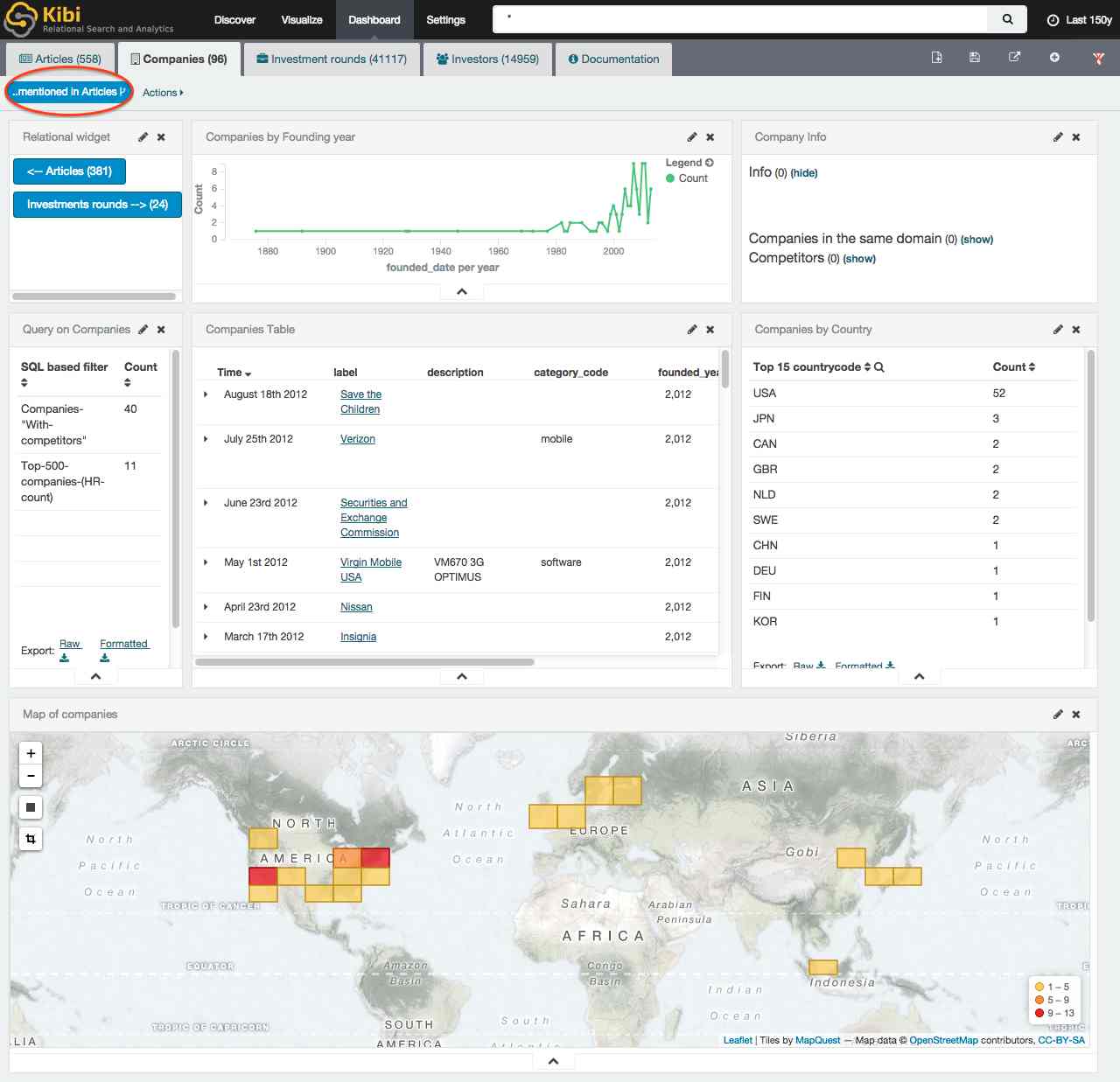
The relational filter created by clicking on the button is displayed in the filter bar, and can be disabled or deleted just like any other filter; moving the mouse over the filter will display the list of joined indexes and their filters:
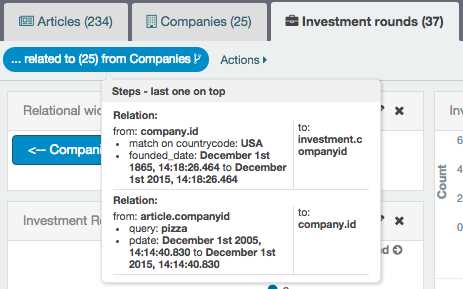
From there, one can continue the journey; for example, if you click on the Investment rounds --> button, you will see data about the 24 investment rounds related to a subset of 96 companies mentioned in the TechCrunch articles ( which also, in this example, mentioned the words wireless or wifi) .
External Datasources (SQL)
Kibi allows to define “Queries” over external datasources. To illustrate these capabilities, the demo distribution includes a SQLite database which contains the data used to populate the Elasticsearch indexes.
It is possible to perform SQL queries over the database to create advanced filters which would not be possible in stock Kibana/Elasticsearch.
Let’s see this in action.Click on the Settings tab, then on Queries, and open the Top 500 companies (HR count) query:
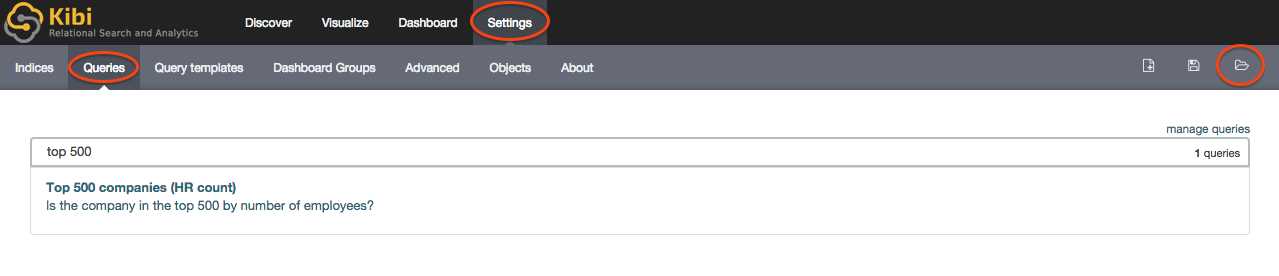
The query returns the id, label and number_of_employees columns from the company table for the top 500 companies by number of employees:
select id, label, number_of_employees
from company
where number_of_employees>0
order by number_of_employees desc
limit 500Once this query is defined, its possible to use it in several ways inside Kibi.
Using SQL queries to aggregate and filter Elasticsearch results
The Query on Companies visualization in “Companies” dashboard uses the query as an aggregation to show which documents in the current Elasticsearch results have their ID in the results returned by the query (that is, they describe companies in the Top 500).
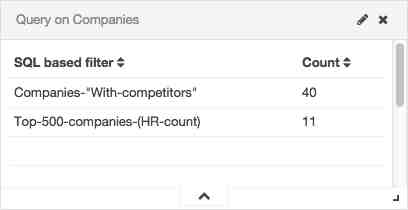
Clicking on the number computed by the aggregation will create a filter on the IDs returned by the SQL query:
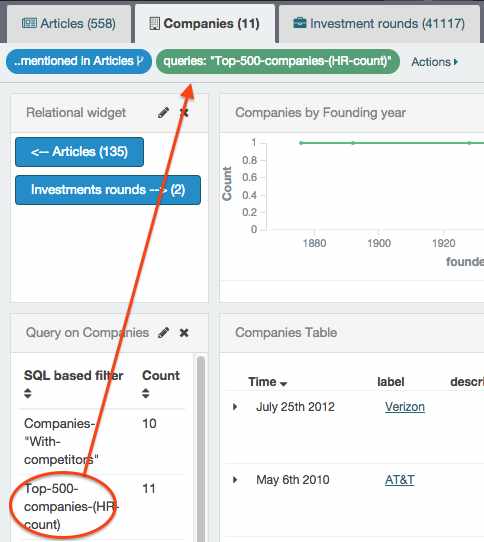
Using SQL queries to augment Elasticsearch results
Kibi allows to configure click handlers on Elasticsearch results; for example, click on Baidu in Companies Table.
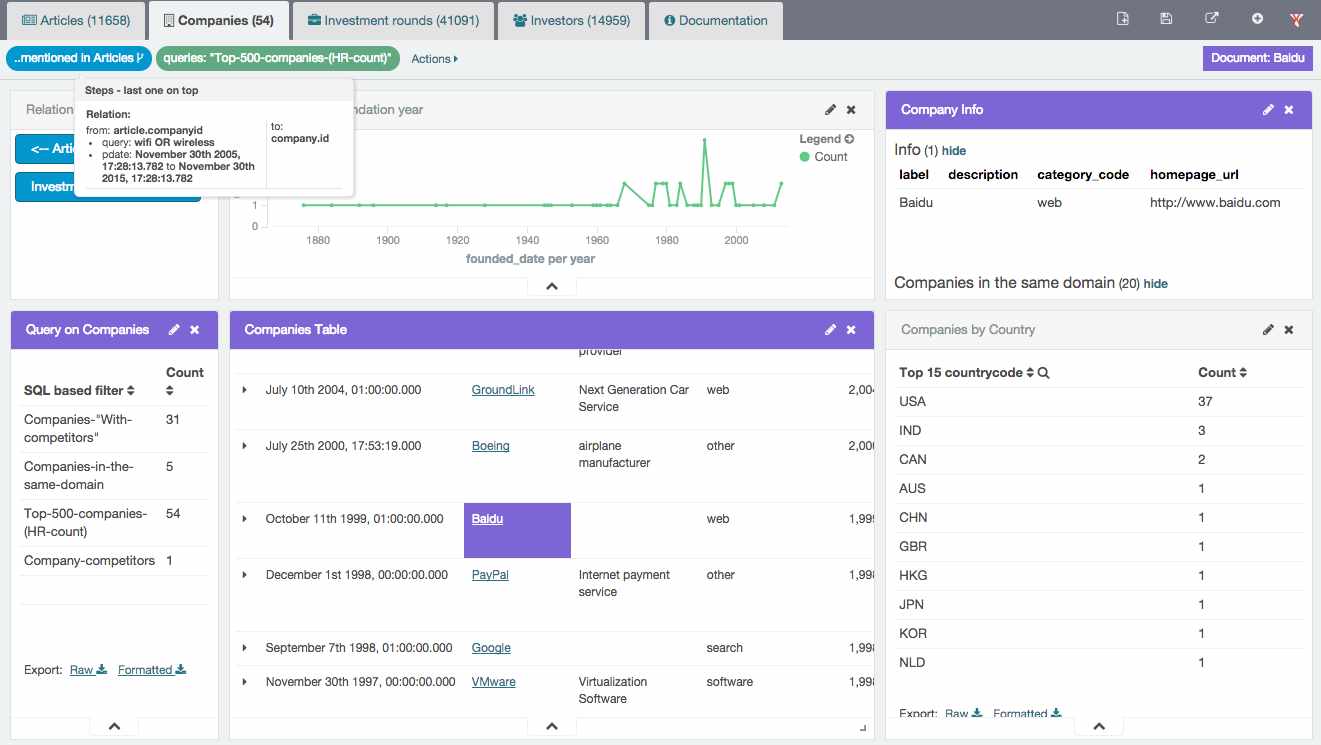
Selecting an entity enables additional aggregations in the Query on companies visualization; these aggregations depend on SQL queries which have the entity ID as a parameter. This is useful for example to show information about competitors and companies in the same domain.
It is also possible to render query results using templates, as displayed in the Company Info widget.
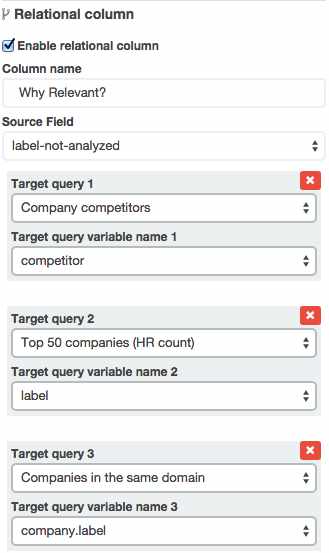
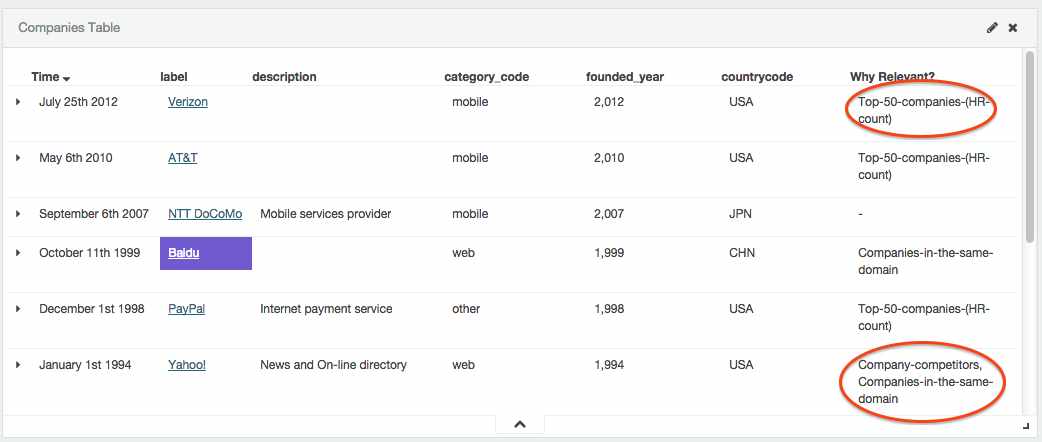
Using SQL queries to classify Elasticsearch results
Queries can be used to classify Elasticsearch results by matching their ID against the query results; for example, it is possible to see that Baidu is in the same domain as Yahoo and Verizon is in the Top 50 companies by looking at the Why Relevant column in Companies Table.
Open Source!
Kibi is fully Open Source; the frontend is distributed under the Apache 2 Licence while the SIREn plugin for Elasticsearch will be distributed under the AGPL license.
Check it out on GitHub now.
Wrapping up
We have a very exciting product roadmap ahead, please follow our blog to keep up to date with the latest features; right now our priority is to have a solid, dependable, project on top of which, we feel, so many interesting things can be built.
Try it now! and looking forward to hear from you.















