

What are Aggregate Relations? OSINT and News Intelligence analysis example
When analyzing the information war on Twitter, the ability to visualize influences (e.g. patterns of messages) and make signals emerge from noise of the individual tweets is paramount. With tens of thousands or more tweets every day on particularly hot topics, and with discussion more and more polarized, it is important to summarize trends on how people interact, versus looking at the individual interactions.
In Siren, by using the Expansion sidebar we can choose in real time how to navigate the knowledge graph: via simple or aggregated relations.
In the picture below, we see the classic simple relations in action in Siren, which allow us to see each individual tweet from one Twitter account to another. In this case, given that the tweet is itself a node, we can see all the individual outgoing links, e.g. links to entities that are mentioned or others that might have retweeted the tweet.
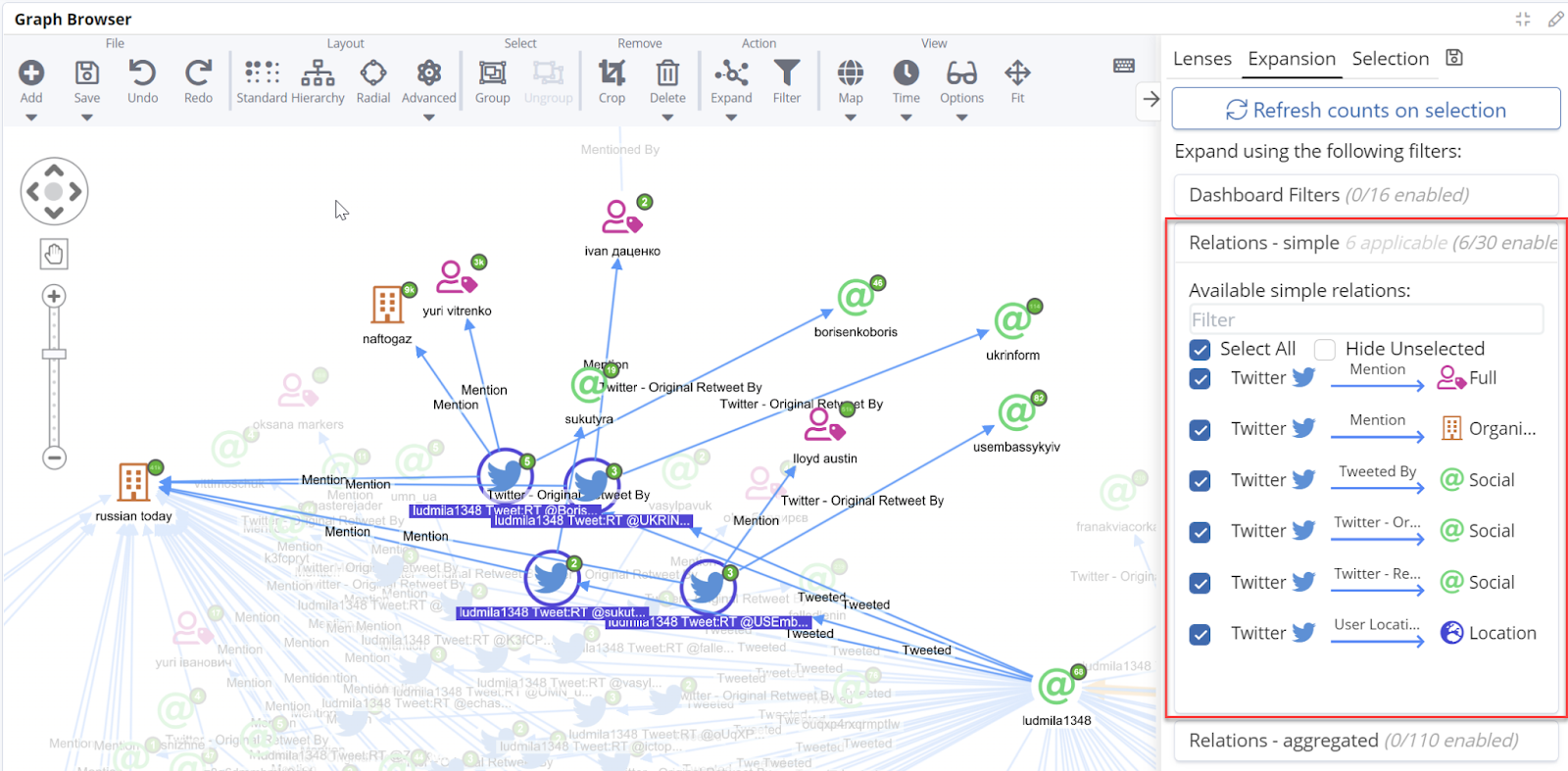
When analyzing trends and chains of retweets however, all the information above is just noise, and one wants to focus on the simple concept of “who retweets this account’s tweets and how frequently?” This is where the aggregate comes into play.
In the following picture I have activated the specific aggregations of any relation going via tweets using a “tweeted/retweeted” relation bridge. The result is an expansion which focuses on the counts of such interactions, without expansion of the individual tweets.
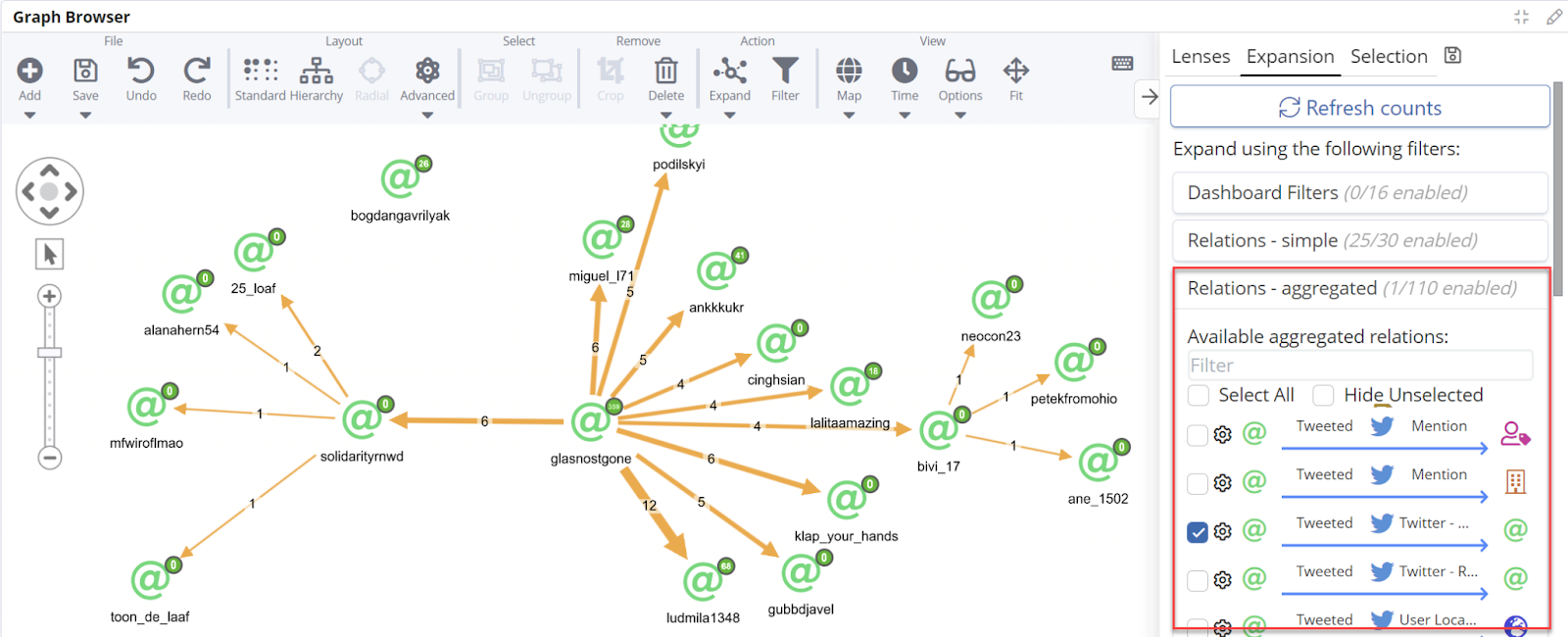
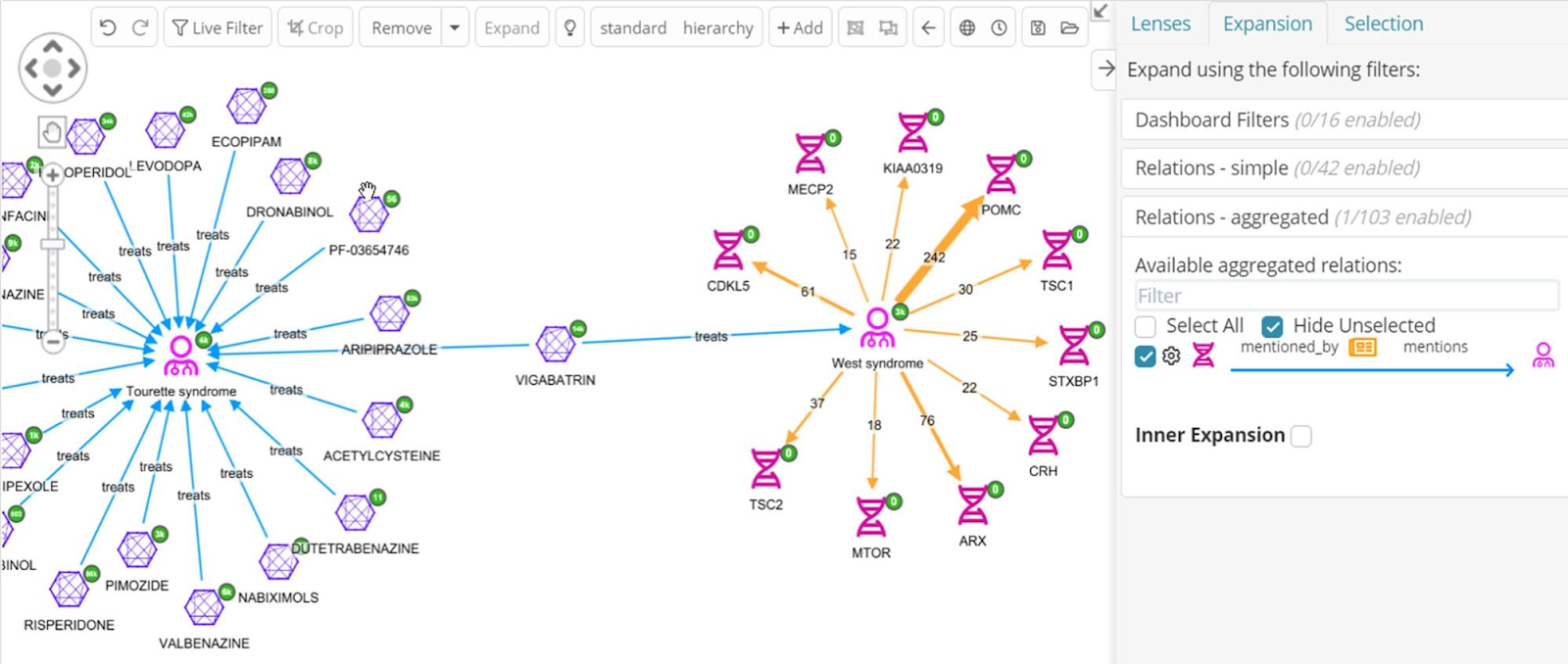
This Siren capability is pretty generic: it can be applied, for example to visualize the amount of information that flows from one host to another based on the aggregation of firewall packets or the correlation between diseases and specific genes based on the number of comments on publications, like in the following:
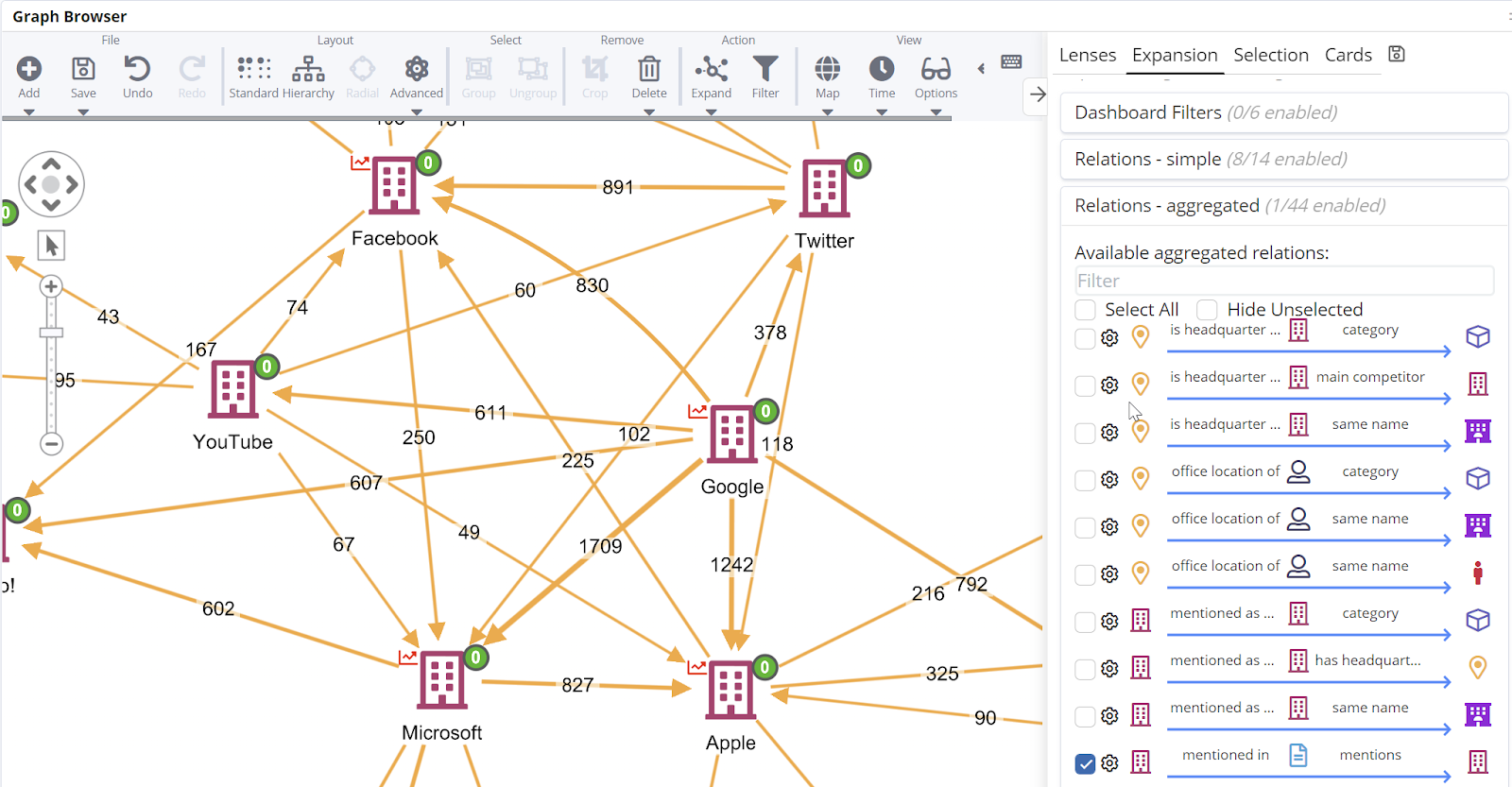
Speaking of comments in articles, this is another very popular application, for example to mine the competitive landscape in a corpus of articles.
And now for a bit of formalism: the theory
More formally, in an Entity-Relationship (ER) model, information is organized around the concepts of entities with attributes and relationships. An entity can describe any concept in the real world such as a person, a company, an event, and so on. An entity can have multiple types of keys, such as composite, primary, foreign, etc. An entity is usually uniquely identified with a primary key. An entity can have multiple types of attributes, such as simple, composite, derived, etc. An attribute is used to describe an aspect of the entity. An attribute can be either single or multi-valued.
An entity can have multiple types of relationships, such as one-to-one, one-to-many, recursive, etc. A relationship is used to describe an association among entities.
Summaries of the data are needed to help humans in exploring and understanding large quantities of data. This is usually performed by executing aggregate operations on one or more dimensions of the data, e.g., summing the number of unique values in a given entity attribute, computing average of the values in a given entity attribute, etc.
These aggregate operations can be pushed to the underlying database systems (for example, Siren uses Elasticsearch aggregators but, on a SQL system, it could be done with the GROUP BY clause), or they can be computed on the client side.
The user is interested in obtaining a summary of composite relationships between two entities by grouping intermediate entities for analytical purposes.
However, the number of possible relationships quickly becomes large (e.g. NxM where N are the incoming and M are the outgoing relations from an entity type) and as such can quickly become very large even with a small number of entity types. In addition, the user must have a good knowledge of the schema and of the data in order to choose a composite relationship that is meaningful to aggregate. This makes the task of selecting good candidates for composite relationships difficult for a user.
Siren’s recently granted patent on efficiently computing aggregate relations tackles this problem by proposing a method to evaluate and filter out composite relationships that are not relevant and to recommend a smaller list of candidates to the user. This enables the query planner to optimize the query processing by automatically selecting the best strategy for aggregating composite relationships based on the capabilities of the underlying database systems.
Efficiently evaluating aggregates on Elasticsearch (and other backends)
Assume an Entity-Relationship model like the one below:
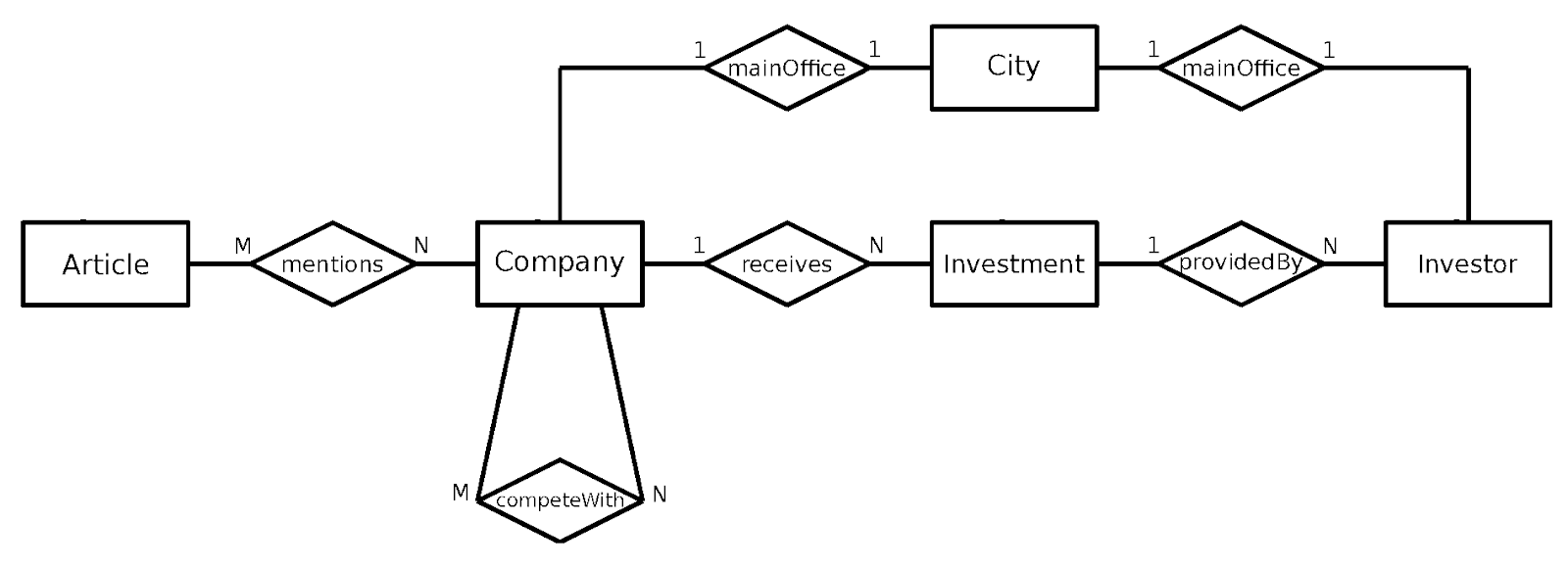
A composite relationship cr(r1, r2) is a relationship between one entity (E1) and another (E3) composed of two relationships, <E1, r1, E2> where r1 is a relation between E1 and E2, and <E2, r2, E3> where r2 is a relation between E2 and E3.
Given an Entity-Relationship model, it is possible to list all the composite relationships by taking the entities one by one and enumerating the possible paths, keeping in mind that r1 and r2 can in fact be the inverse of each other, and E1, E2, and E3 can even refer to the same entity. The enumeration may yield a number that is quite high compared to the number of entities (there are 38 possible composite relationships in our simple example).
Filtering and Ranking Composite Relationships
It is trivial for a schema registry to enumerate all possible composite relationships for this entity type, but in some cases certain composite relationships will not bear any useful information so these should be eliminated from the list.
For example, the path between an entity instance e1 ∈ E1 and an entity instance e3 ∈ E3 may be only one (by definition) or may not exist and in either of these cases it would not make sense to aggregate.
In our example schema, this is found in the composite relationship <Investments, inverse(receives), Companies, mainOffice, City> from the model above.
This is a trivial path since, according to the schema, there can always only be one company linked to an investment, and one city linked to a company. The method makes it so that recommendations like these will not be given, thus reducing information overload on the user side.
Also, the aggregability of a composite relationship <E1, r1, E2, r2, E3> may be estimated using the cardinality of its individual relationships. We define the cardinality of a relationship <E1, r1, E2>, as being the average number of unique values for the attribute r1 across all entity instances of type E1. In Siren, this metric is provided in a highly efficient way by the underlying Elasticsearch/Federate plugin backend.
Once the cardinality of the individual relationships have been computed, the recommender may estimate the cardinality of a composite relationship by combining the cardinality of the individual relationships using the product operator Π, i.e.
card(<E1, r1, E2, r2, E3>) = Π(card(<E1, r1, E2>), card(<E2, r2, E3>)).
When the cardinality estimation is less than or equal to 1, it is more likely that this composite relationship leads to a unique or a non-existing path between entity instances e1 and e3, and therefore the recommender may discard it from the results.
Likewise, the recommender may rank the remaining composite relationships using the computed cardinality estimation, based on the principle that a composite relationship with a large cardinality estimation may be more relevant for the user as it may provide a way to aggregate larger sets of data.
Strategies for Aggregating Composite Relationships
When a client sends an entity identifier and a composite relationship to the query planner, the query planner uses the schema registry to map the entity types to their respective tables, and then retrieves information about the capabilities of the database systems storing these tables. Depending on the capabilities of the database systems, the query planner may decide to use a different strategy for computing the aggregation of the composite relationship.
Efficient executions using Siren’s optimized semi-joins in Elasticsearch
Thanks to the Siren Federate plugin, the Siren platform can perform extremely scalable semi-joins natively in the backend. Semi-joins are much more efficient to compute than full joins, which the platform also supports.
There are two different conditions where the evaluation of a composite relationship can be reduced to a semi-join:
Condition 1
When the entity E3 is mapped to a foreign key attribute of the entity table E2 (such as City in the example), the strategy to aggregate the composite relationship is reduced to a single semi-join between tables E1 and E2. E1 is used to filter records from E2, and a regular aggregation is performed based on the foreign key attribute from E2 that is mapped to entity E3.
Example: Articles Mentions Companies mainOffice City
Given the article identifier A1 as starting point, this requires joining the Articles table with the Companies table on the Companies.ID key to filter the Companies table, then grouping by the foreign key attribute City. In SQL notation this would be:
SELECT COMPANIES.CITY, AVG_EMPLOYEES
FROM ARTICLES, COMPANIES
WHERE
ARTICLES.ID = “A1”
ANY( ARTICLES.mentions ) = COMPANIES.ID
GROUP BY COMPANIES.CITY
ORDER BY AVG(COMPANIES.EMPLOYEES) AS
AVG_EMPLOYEES DESC
Condition 2
When both the entities E1 and E3 have a foreign key attribute to E2 and when the aggregation is restricted to a count, then the strategy to aggregate the composite relationship may be reduced to a semi-join between table E1 and E3. Record identifiers of E2 from the foreign key attribute of E1 are used to filter records from E3.
Example: Articles Mentions Companies inv(securedBy) Investments
SELECT INVESTMENTS.ID, COUNT(*)
FROM ARTICLES, INVESTMENTS
WHERE
ARTICLES.ID = “A1”
ANY( ARTICLES.mentions ) = INVESTMENTS.securedBy
GROUP BY INVESTMENTS.ID
ORDER BY COUNT(*) DESC
Disjunctive Search Query Strategy
This strategy may be considered as a special case of the semi-join where the table E3 (the one being filtered) belongs to a database system with full-text search capabilities (such as Elasticsearch). In that case, the semi-join may be executed very efficiently using a disjunctive (OR) search query based on the record identifiers retrieved from the first table. The results are returned ranked by the number of intermediate matches (count of E2).
This is the case for the composite relationship <Articles, mentions, Companies, inv(mentions), Articles> which would return, given a starting article with id=1, the articles which have one or more mentioned companies in common, naturally ranked by the search engine based on the number of co-mentions.
Single Table Aggregation Strategy
This strategy is possible when the entities E1 and E3 are each mapped to a foreign key attribute of E2 (either in the same attribute or in separate attributes).
This strategy does not require a join and is instead computed using a regular aggregation operation on entity table E2. This strategy is particularly useful since this operation is supported by most database backends.
Example: Companies inv(mentions) Articles Mentions Companies
In this example, the attribute Articles.mentions contains foreign keys to Companies. This attribute is used to filter the Articles table with the starting company identifier C1 and to group the co-mentioned companies.
SELECT CID, COUNT(*)
FROM (SELECT ARTICLES.ID, UNNEST(ARTICLES.mentions) AS CID
FROM ARTICLES WHERE ANY( ARTICLES.mentions ) = ‘C1’)
GROUP BY CID
ORDER BY COUNT(*) DESC
Conclusion
In this post, we’ve given an overview of the implementation strategies behind Siren high performance aggregated relations capabilities, a snappy, big data capable method to see how entities are connected by transactions (or other entities).
This has wide applicability in investigations in OSINT, Cybersecurity and in general Law Enforcement where tracking aggregates flows of money and goods is key.
Want to learn more? Please see:
- US Patent US20200142899A1 – “Method for efficient backend evaluation of aggregates on composite relationships in a relationally mapped er model” – Fabio TACCHELLI, Dr, Giovanni TUMMARELLO, Dr. Renaud DELBRU
- Siren for financial fraud (a video here)















