
The Siren Federate 22.0 release delivers important developments: The explain API and compatibility with Elasticsearch version 7.10.1.
The explain API
Siren Federate 22.0 introduces a new API that can be used to obtain information about how Federate executes a search request. The explain API is similar to the EXPLAIN keyword in SQL databases. Instead of executing the search request and returning a search result, the explain API returns a description of the query execution plan of a search request.
The description of a query execution plan comprises the steps that would take place to compute the search results, including information about how indices are joined. For example, let’s take the following search request which returns all the companies mentioned in articles containing the keyword “IPO” in its title.
GET /siren/company/_search
{
"query": {
"join": {
"type": "HASH_JOIN",
"indices": [
"article"
],
"on": [
"id",
"companies"
],
"request": {
"query": {
"match": {
"title": "IPO"
}
}
}
}
}
}
The Federate query planner will evaluate the search request and generate the following query execution plan.
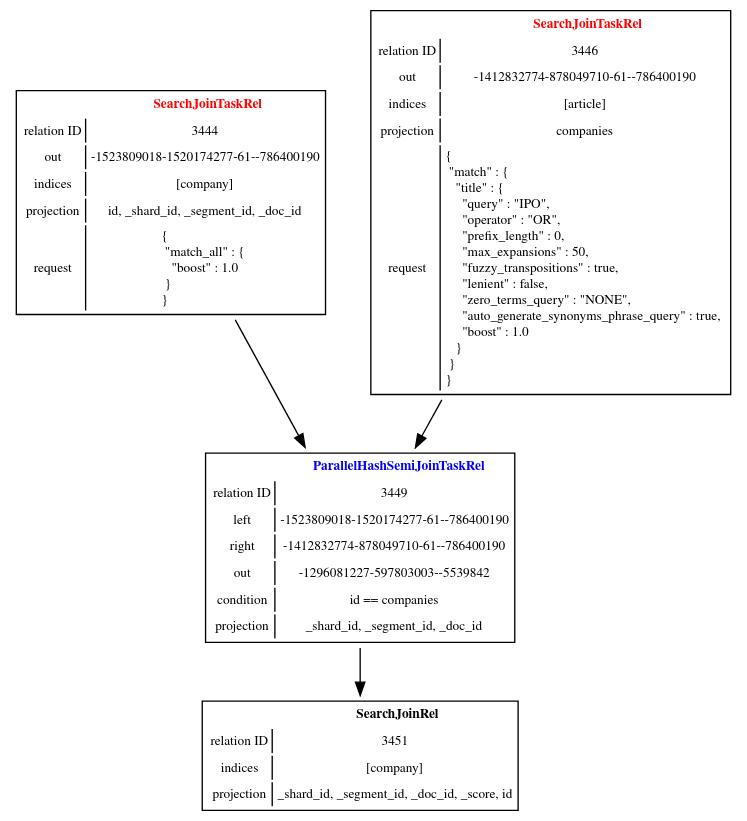
The query execution plan is a directed acyclic graph, where each node represents a task that is being executed on the cluster. It is composed of two “SearchJoinTaskRel” tasks, each one projecting and shuffling the necessary data to the subsequent “ParallelHashSemiJoinTaskRel” task. The task “ParallelHashSemiJoinTaskRel” is performing a distributed hash join to compute the matching document identifiers of the “company” index. The last task “SearchJoinRel” is generating the final search response based on the document identifiers computed in the previous task.
The explain API produces a response with a JSON representation of the query execution plan, as shown below. In addition, the explain API associates each task with various information such as a definition of the type of rows being projected by the task, an estimation of the number of rows that will be projected, or an estimation of the network and IO cost.
{
"node": "04g2Hw4YT3m3TS6h85JQEQ",
"query_plan": {
"request": "SearchJoinRequest{...}",
"row_type": [
"#0: _shard_id JavaType(class PlannerType$Integer)",
"#1: _segment_id JavaType(class PlannerType$Short)",
"#2: _doc_id JavaType(class PlannerType$Integer)",
"#3: _score JavaType(class PlannerType$Float)",
"#4: id MetadataType{digest=JavaType(class PlannerType$String) SEARCHABLE AGGREGATABLE}"
],
"type": "SearchJoinRel",
"physical_plan": "rel#3906:SearchJoinRel...",
"is_cached": false,
"row_count": 1,
"cost": {
"io": 0.0,
"network": 0.0
},
"cumulative_cost": {
"io": 163260.63,
"network": 323366.63
},
"children": [
{
"request": "JoinTaskNodesRequest{...}",
"row_type": [
"#0: _shard_id JavaType(class PlannerType$Integer)",
"#1: _segment_id JavaType(class PlannerType$Short)",
"#2: _doc_id JavaType(class PlannerType$Integer)"
],
"type": "ParallelHashSemiJoinTaskRel",
"physical_plan": "rel#3904:ParallelHashSemiJoinTaskRel...",
"is_cached": false,
"row_count": 160106.0,
"cost": {
"io": 0.0,
"network": 160106.0
},
"cumulative_cost": {
"io": 163260.63,
"network": 323366.63
},
"children": [
{
"request": "SearchTaskBroadcastRequest{...}",
"row_type": [
"#0: companies MetadataType{digest=JavaType(class PlannerType$Hashed) NOT NULL SEARCHABLE AGGREGATABLE}"
],
"type": "SearchJoinTaskRel",
"physical_plan": "rel#3901:SearchJoinTaskRel...",
"is_cached": false,
"row_count": 3154.63,
"cost": {
"io": 3154.63,
"network": 3154.63
},
"cumulative_cost": {
"io": 3154.63,
"network": 3154.63
}
},
{
"request": "SearchTaskBroadcastRequest{...}",
"row_type": [
"#0: id MetadataType{digest=JavaType(class PlannerType$Hashed) NOT NULL SEARCHABLE AGGREGATABLE}",
"#1: _shard_id JavaType(class PlannerType$Integer)",
"#2: _segment_id JavaType(class PlannerType$Short)",
"#3: _doc_id JavaType(class PlannerType$Integer)"
],
"type": "SearchJoinTaskRel",
"physical_plan": "rel#3899:SearchJoinTaskRel...",
"is_cached": false,
"row_count": 160106.0,
"cost": {
"io": 160106.0,
"network": 160106.0
},
"cumulative_cost": {
"io": 160106.0,
"network": 160106.0
}
}
]
}
]
}
}
The explain API is a great tool to quickly validate a search request. You can also use it to verify the cost of a search request before executing it and, if it is deemed too costly, you can block it end, for example, request that the user adds more filters before the execution.
This is in fact the core use case for this API: currently, Siren Investigate allows administrators to block expensive queries to certain users based on the time range or on the number of records in the source and target table. With this new approach, it will be soon possible to have a more flexible limit based on a more accurate cost estimation.
The explain API is also an important tool for analyzing slow search requests, understanding the cause, and possibly finding a remedy.
For more information and examples of the explain API, see the Siren Federate documentation.
What’s next?
We are hard at work on the next features. The Siren Federate 23.0 will bring an improved compatibility with Elastic Cloud and Elastic Cloud Enterprise, which was something that was requested many times these past months, as well as a new connector for remote Elasticsearch clusters, which will give you the capability to query and join data located in a remote Elasticsearch cluster even if it does not have the the Siren Federate plugin installed.
The Siren Federate 24.0 will introduce a new type of join strategy that uses routing knowledge for improved performance, as well as many other performance enhancements including heap-memory optimizations and a new radix-based partitioning that will boost inner-join efficiency.
Community Edition
Siren Federate 22 is available today, compatible with Elasticsearch 7.10.1. Download here!















