


This year I had the opportunity of presenting a talk about Siren Federate at the Berlin Buzzwords conference. I have attended many interesting talks and discussed with people passionate about search.
Barcamp
It started on Sunday with a Barcamp, an “un-conference” where the schedule for the day is decided on the day by everyone voting on what they would like to hear.
The 1st presentation was from an OpenSearch person who discussed the importance of evaluating and maintaining the ranking configuration of a search engine. OpenSearch plans to develop a toolkit to support the task of checking the relevance quality, in order to answer questions such as what change caused a regression, or whether a modification to the search configuration would end up in a better ranking.
The 2nd presentation was from a Vespa user who showed an auto-completion solution powered by BERT integrated into Vespa.
The final presentation I attended was about a data-discovery tool for Solr. The person developed a tool similar to Jupyter Notebooks, where a book stores not only searches but also a series of transformations of a search’s results. Transformations are written in JavaScript and Python which allows to use libraries like Panda to apply modifications easily on a search’s result. A visualization that best fits the data can be also generated, e.g., a bar chart for a histogram.
Conference
At this year of Berlin Buzzwords, I got the chance of presenting the work done on Siren Federate. I showed what kind of queries can be expressed by merging Elasticsearch features like runtime fields together with Siren Federate’s join queries. Then, I showed how the join operation is executed internally in by going over the execution flow of a HASH_JOIN, the vectorization of the data processing, and finally the query cache. Thanks to everyone who had questions during the talk!
Atita Arora presented the talk Vectorize you open search search engine where she discussed about the challenges vector search can help solve, e.g., multi-modal retrieval or bad schema quality, and how to add a vector component to the search logic. The KISS principle should be followed when implementing vector search, i.e., just apply the strict minimum in a simple way and possibly optimize the approach later on. Several talks mentioned the possibility of “hybrid search”, i.e., combining vector search with traditional search features like BM25. In the end, vector search will surely facilitate the configuration of search engines, but it won’t replace traditional keyword search.

Olena Kutsenko showed some internal aspects of ClickHouse, an OLAP database. It represents data in columns in order to apply compression more effectively and to access only relevant data. ClickHouse has different type of indices to access data, for example, a sparse index or a data skipping index. The former is used to index data every few rows and the latter is akin to SkipList. ClickHouse relies on the vectorized execution of operations over the data. Finally, external databases can be mirrored into the main memory and updates can be checked periodically.
Alessandro Benedetti presented his multi-valued vector fields contribution to Lucene. We got a nice overview of how HNSW works at index time and at query time. This contribution will help in representing text with multiple vectors, e.g., a vector created per paragraph.

Keeping in theme with the Siren Federate plugin for Elasticsearch, Yingjun Wu from the RisingWave database presents joins over streams. A pillar of the database is an efficient management of the stream’s state. Regarding the computation of joins, he observed that the pairwise computation of joins creates a left-deep tree of join executions. The tree depth has an impact on the query latency. The depth can be reduced by translating the execution tree into a bushy tree.
Javier Ramirez presented what optimizations were done in QuestDB so that the time-series database is able to ingest 4M rows per second. Although Siren Federate also processes data stored off-heap, QuestDB takes this to a new height by exclusively processing this data with off-heap data structures. This means that any class from the Java standard library is re-implemented to read/write from off-heap. Also, some operations are done in C++; in order to avoid the overhead of passing data through JNI, the raw pointer to the memory location is shared. Manipulating raw pointers sounds scary, but obviously, it works. Hats off to the QuestDB team!
I attended the talk from Uwe Schindler presenting the 25 years of Lucene since Doug Cutting released it in 1998. He showed a nice timeline from 1.0 till 9.7 and the major milestones in-between.
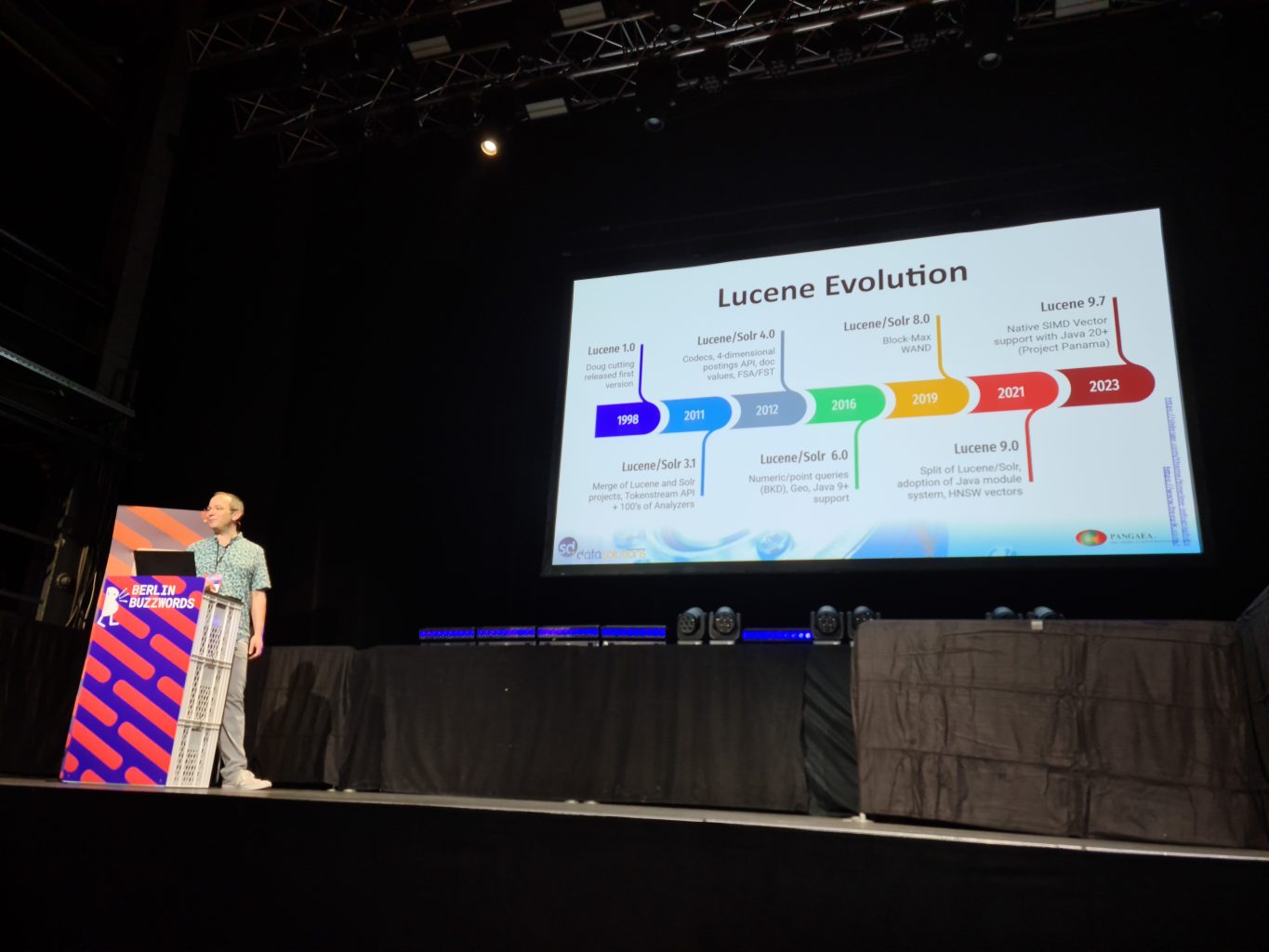
Uwe made an interesting observation regarding the HSNW data structures used for searching vectors: that Lucene’s architecture is not the best adapted for it. Indeed, Lucene needs to merge segments when some size threshold is reached. This means that the HNSW data structures from each merging segment need to be updated, which requires a lot of similarity calculation at index time.
The release 9.7 of Lucene will introduce SIMD optimizations, thanks to the Project Panama of Java. The multiplication of vectors is a well-contained piece of code which can therefore be easily vectorized. The multiplication is applied over float arrays; the float primitive is not commutative therefore a tight loop over a float array can’t be automatically vectorized by Java. He showed a snippet of the vectorized version of the vectors multiplication for entertainment.
After the multiplication of vectors, SIMD will be applied to the compression algorithms PForDelta and PackedInts.

To finish the conference on a light note, I went to a fun presentation from Philipp Krenn about how Elastic uses its Observability application to find cheaters of the Elastic Contributor Program.

I also got to discuss with people from the OpenSearch project. They mentioned an interesting upcoming feature: search pipelines. This allows running operations to mutate a search request before executing it, or operations after the execution on the search results. There is also a plan to add hooks into the query and fetch phases of a search request execution using this API. Related to Siren Federate, they also plan to add join capabilities!
In the end, this conference went very well. I had many thoughtful discussions with people from different backgrounds. For example, I met an engineer working at the Greifswald University, where experiments for developing a fusion reactor generates petabytes of data! I look forward to 2024 for another great conference!















