

The evolution of the Siren Join plugin
The Siren Join plugin was built two years ago, initially to perform a semi-join between Elasticsearch indices, and has evolved organically since then. While it has been doing a good job in many scenarios, it has limitations:
- An inherent scalability limit: Siren Join worked by electing a coordinator node which had to gather all the data identifiers before sending them to all the shards. This created a memory bottleneck on the coordinator node and would not leverage the availability of additional nodes in the cluster.
- Sub-optimal data exchange: the binary data was part of the query leading to various performance limitations & suboptimal caching and serializations.
- Primitive query planner: it was not built on relational algebra and had only primitive ability to optimize a query execution or do complex operations.
Siren Vanguard is a completely new software product to solve these limitations, improve performance and scalability, and provide the platform on which we can develop more advanced features.
Relational, Federated, Distributed
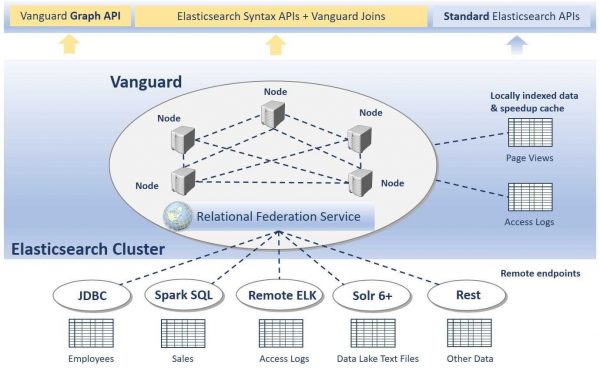
Our core requirements for Siren Vanguard are:
- Low latency, real time interactive response – Vanguard is designed to power ad hoc interactive, read only queries such as our Kibi data intelligence product.
- Implement a full featured relational algebra, capable of being extended for more advanced join conditions, operations and statistical optimizations.
- Flexible computational framework (e.g. Map Reduce).
- Horizontal scaling of fully distributed operations, leveraging all the cluster memory.
- Federated – capable of working on data that is not inside the cluster, for example via JDBC connections.
High level architecture concepts:
- A coordinator node which is in charge of the query parsing, query planning and query execution. We are leveraging the Apache Calcite engine to create a logical plan of the query, optimise the logical plan and execute a physical plan.
- A set of worker processes that are in charge of executing the physical operations. Depending on the type of physical operation, a worker process is spawned on a per node or per shard basis.
- An in-memory distributed file system that is used by the worker nodes to exchange data, with a compact columnar data representation optimized for analytical data processing, zero copy and zero data serialisation.
Vanguard/Federate 2017/18 roadmap
This initial release of Siren Vanguard includes an implementation of the original Siren Join algorithm, but in general it provides better performance and caching than Siren Join in many scenarios. The next release of Vanguard will include a fully distributed join algorithm that will enable horizontal scaling. We will also release a comprehensive set of benchmarks to demonstrate its scalability.
- Vanguard 5.4: our initial production release. It outperforms the previous Siren-Join due to more advanced caching and memory management.
- Vanguard 5.5: fully distributed joins – performance and scalability backmark will be made available at this stage (early Q4 2017).
- Vanguard 5.6: JDBC connectors and federated operations (late Q4 2017).
- Federate 10: JDBC connectors and federated operations (Q1 2018).
License
Vanguard is free to use also for commercial purposes for up to one data node in your Elasticsearch installation.
For cluster deployment, a commercial licence is required, priced per node.
Download Vanguard from our Customer Portal.
The whole architecture is available on our Customer Portal.
Please, let us know what you think about Siren Vanguard on Twitter, for any inquiry feel free to contact us at info@siren.solutions. In the meanwhile, make sure you’re signed up to our Newsletter to be always informed about updates and new releases.















