
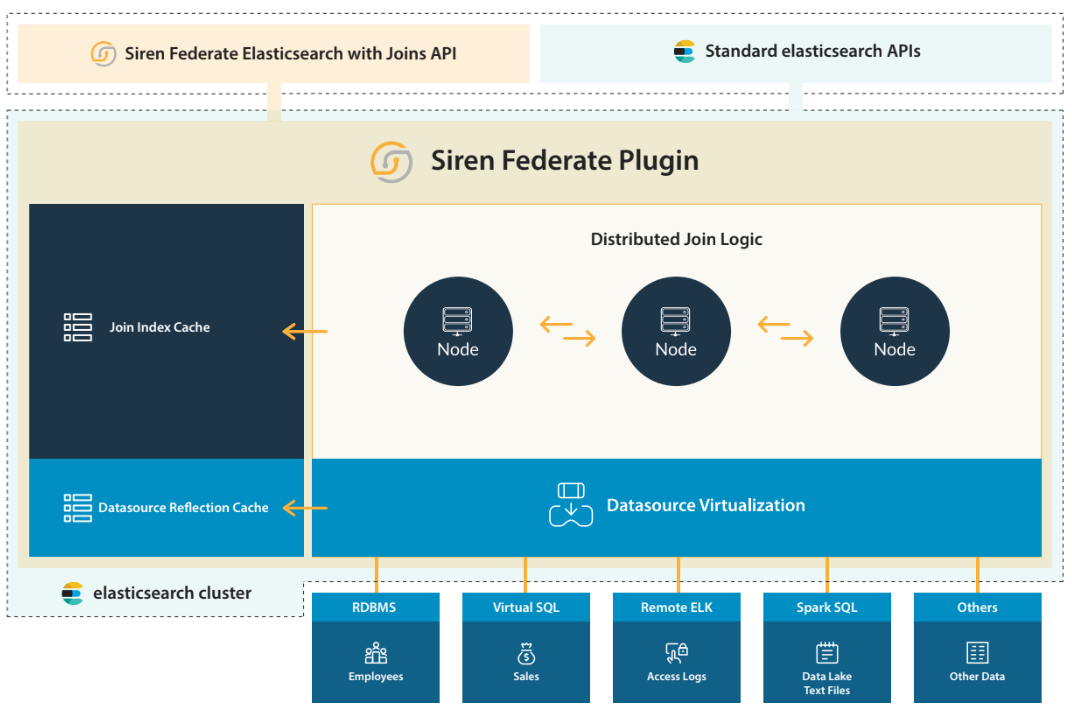
We are very excited to announce the general availability of version 23.0 of Siren Federate – Siren’s plugin for Elasticsearch, which augments the core query language with joins and other capabilities.
After the recent release of Siren Federate 22.0, which added the important “explain API”, Siren Federate 23.0 delivers the following new features:
- Compatibility with Elastic Cloud, ECE, and Elasticsearch 7.11
- Compatibility with remote clusters that do not have Siren Federate installed for cross-cluster operations
- A number of performance optimizations that improves the response time when processing large amounts of data
- Improved documentation with performance considerations, troubleshooting, and information about permissions for APIs
Connector for remote Elasticsearch clusters
Siren Federate provides uniform access to remote data sources, together with an optimized query push-down into the same systems. After establishing a connection, an index from a remote Elasticsearch cluster is mapped to a virtual index within the local cluster. This enables the front-end client, Siren Investigate, to leverage the API to communicate to the remote datasource in a uniform way.
Up until now, Siren Federate was able to connect to a remote Siren Federate cluster; that is, a remote Elasticsearch cluster that has Siren Federate installed. With Siren Federate 23.0, it is now possible to connect to a remote Elasticsearch cluster that doesn’t have Siren Federate installed.
One of the main advantages is the ability to join data across multiple Elasticsearch clusters with a single Siren Federate coordinator cluster. The difference with a remote Siren Federate cluster connector is that Siren Federate is not able to push down the execution of join operations between remote indices to the remote cluster, and instead performs the join operation on the coordinator cluster with limited scalability.
Up to 250% faster
We are rolling out a series of performance improvements that considerably improve the performance. These performance improvements are available in Siren Federate 23.0, but also in the latest Siren Federate patch releases.
Specifically, we reduced the heap and CPU usage when computing a broadcast or index join on a node that has more than one shard. At the same time, we reduced the latency of the worker’s tasks and of the data transfers between workers by improving thread management at the data exchange layer.
What does this mean in practice? Let’s see how it improves things on a dataset of 15 billion records.
The dataset
A synthetic dataset, composed of 15 billion records, has been created with simulated GPS tracks coming from devices over 100 days.
In this test, we generated 156 million records per day, using 6.5 million unique device identifiers (for example, phone numbers).
We created one index per day, with each index composed of 8 primary shards with no replica. The total size of the indices amounted to 2.7 terabytes.
The following screenshot displays the mapping structure that was used on the generated records. The field “time” is used for time-series indexing and the field “msisdn” (A.K.A. phone number) or “geotimehash” is used for (self-) joining two sets of documents.
{
"positions-2020-06-01": {
"mappings": {
"properties": {
"geotimehash": {
"type": "long"
},
"hpe": {
"type": "float"
},
"imei": {
"type": "long"
},
"imsi": {
"type": "long"
},
"location": {
"type": "geo_point"
},
"msisdn": {
"type": "long"
},
"time": {
"type": "date",
"format": "epoch_second"
},
"type": {
"type": "keyword"
}
}
}
}
}The queries
We executed three different scenarios to test the performance of the system.
The scenarios consisted of a multi-search request that was generated by Siren Investigate to load a complex analytic dashboard. Each multi-search request consisted of five search requests. Each search request defines a different aggregate clause and is used to load a widget.
Widgets include charts with aggregated information, tables sorted by a particular attribute, and so on.
Each scenario execution used a randomized time range to make sure that we bypassed the query caches of Elasticsearch and Siren Federate.
The following scenarios were tested:
| Scenario 1. | Refresh a dashboard with a time range filter over 1 day. The dashboard is filtered with a geofilter over 5% of the data. The dashboard is filtered by a relational filter which joins using the field “msisdn” to join another dashboard with a different geofilter over 5% of the data and with a time range filter on the previous day. This typically answers the question, “Find all the devices that are in this location today, but were in this other location yesterday”. |
| Scenario 2. | Same as scenario 1, but with a week-long range (resulting in 7 times more data). |
| Scenario 3. | Refresh a dashboard with a time range filter over 90 days. The dashboard is filtered by a relational filter. The relational filter is using the field “geotimehash” to join another dashboard with a similar time range filter and a term filter on a given phone identifier. This finds all the other phone records that were in close proximity to a given phone during that period of time. |
Table 1. Scenarios that were applied in the benchmark test.
The system settings
The hardware system that we used for our benchmark tests is based on AWS machines of type “i3.4xlarge”, configured with Cascade Lake processors, a single local NVME drive for the Elasticsearch data directory, a gp2 drive for the operating system, and a 10 Gbps network link.
The version of the Java Virtual Machine (JVM) used during our benchmark tests is 15.0.1. The version of Elasticsearch that was used was 7.10.2, configured with a heap size of 30 GB.
Versions 22.0 vs. 22.2 (a prerelease of version 23.0) of Siren Federate were used, configured with an off-heap memory size of 16 GB.
The test
The benchmark test reproduced a load-test scenario with a number of concurrent users. We tested the system with 1, 5 and 10 concurrent users. Each measurement consisted of the time taken for a user to execute a randomly-selected scenario (of the three scenarios).
The load-test scenario is run for a certain amount of time, until at least one hundred measurements for each scenario is produced. The size of the cluster is 36 nodes.
The results
The following charts outline the average response time for 1, 5 and 10 concurrent users. The colored bars represent the different cluster sizes.
Response time for Scenario 1
We can observe a 22% reduction of response times from version 22.0 to version 22.2/23.0 for 1 concurrent user, 40% for 5 concurrent users, 58% for 10 concurrent users and 50% for 20 concurrent users.
The performance improvement becomes more significant as the number of concurrent users increases, thanks to the more optimized worker thread management.

Figure 1. 90th percentile of response times for scenario 1 per the number of concurrent users.
Response time for scenario 2
We can observe a 40% reduction of response times for 1 concurrent user, 55% for 5 concurrent users, 60% for 10 concurrent users (a 250% speedup!) and 54% for 20 concurrent users. Similarly to scenario 1, the performance improvement becomes more significant as the number of concurrent users increases, thanks to the more optimized worker thread management.
We can also observe a more significant performance improvement with 1 and 5 concurrent users, as this scenario is shuffling 7 times more data than scenario 1.

Figure 2. 90th percentile of response times for scenario 2 per the number of concurrent users.
Response time for scenario 3
Scenario 3 is based on an index join. We can see that the performance improvement for this scenario is less significant than for the other scenarios given that this join strategy is shuffling very little data across the network.
We can observe a 10% reduction of response time for 1 concurrent user, 20% for 5 concurrent users, 32% for 10 concurrent users and 49% for 20 concurrent users.

Figure 3. 90th percentile of response times for scenario 3 per the number of concurrent users.
Breaking changes
Following the upgrade to Elasticsearch version 7.11, the connectors to external JDBC datasources have been removed and replaced by a unique and generic Avatica JDBC connector.
It is no longer possible to create a virtual index over a JDBC datasource. Instead, it is now recommended to index data from JDBC datasources through the Ingestion API.
For more information, see Configuring a JDBC-enabled node.
Security fixes
Fixed a potential leak of user information across thread contexts. If a user runs a query concurrently with another more privileged user on the same coordinator node, the search could be executed with higher privileges. This could result in an attacker gaining additional permissions against a restricted index.
All versions of Federate before 7.11.2-23.0, 7.10.2-22.2, 7.9.3-21.6, 7.6.2-20.2 and 6.8.14-10.3.9 are affected by this flaw. You must upgrade to Federate version 7.11.2-23.0, 7.10.2-22.2, 7.9.3-21.6, 7.6.2-20.2 or 6.8.14-10.3.9 to obtain the fix. CVE-2021-28938.
Bug fixes
- Fixed a planner exception and an illegal access error in the inner join scenario (1 & 2), which was detected during benchmark testing.
- Fixed a missing configuration type exception on the API that is used to define a virtual index.
- Fixed the data output identifier of a table search scan, which impacted negatively on the join resolution and join cache hits.
- Fixed the maximum concurrent uploads in the segment partitioner collector manager.
- Fixed an issue that caused the filter in the index alias not to be taken into account.
- Fixed an issue that caused the Data Streams indices not to be taken into account in search requests.
- Fixed a bug in the Search Guard support code that caused DLS clauses not to be properly applied on nested documents.
Conclusion and what’s next?
Elasticsearch is increasingly becoming the world’s centerpiece for collecting and interactively searching large amounts of data.
For all the use cases where investigations are required, the ability to interactively do real-time correlations (joins) is a superpower that leads to smarter applications and much more simplified architectures – often doing away with many other components that are typically used for “data correlations”.
With Siren Federate version 23.0, we are proud to deliver support for the latest version of Elasticsearch and start rolling out a wave of deep-impacting performance and scalability optimizations.
Future versions will focus on supporting the latest features introduced by Elasticsearch 7.11 and 7.12 – runtime fields and long running queries, as well as further improving performance with a new wave of optimizations.
Also, we are happy to share that Siren Federate version 24.0 for Elasticsearch version 8.0 is already available as an internal Alpha, and is ready to be released as Beta when the Elasticsearch version 8.0 beta is released.















