

We’re happy to announce today the release of Siren Federate v25, the Siren plugin for Elasticsearch which extends the core query language with real-time join capabilities. This release brings key updates among which support for runtime fields and compatibility with Elasticsearch version 7.13.
Moreover, this release offers bug fixes and improvements, such as a new search pagination strategy based on the Point-In-Time API and the search_after parameter, a new shard selection algorithm, and a new lightweight statistical query optimizer, which replaces our previous use of Apache Calcite’s Volcano optimizer – maximizing the use of the cache and providing performance benefits (as well as paving the way for further deeper optimizations).
Improving support for runtime fields
Since the first release of runtime fields in Elasticsearch 7.12, support for them has been improved significantly in this release of Siren Federate. These dynamic fields – which are computed at query time – can now be used in the “join” query clause and are compatible with most join algorithms and with all types of fields.
This development adds new levels of flexibility in exploring new types of relationships between documents. For example, runtime fields can be used to dynamically compute and join composite keys. A use case example is described below.
On the performance side, the runtime fields usage has been evaluated in a newly created benchmark scenario to measure the impact of runtime fields on the performance of the join operation. The benchmark results are presented below.
Known limitations
Although Elasticsearch supports the definition of runtime fields within a request, this is not yet supported in Siren Federate. Runtime fields need to be defined in the mapping of an index.
Also, if the `HASH_JOIN` and `BROADCAST_JOIN` algorithms are fully compatible, some limitation remains for the `INDEX_JOIN` algorithm which only supports a join with a runtime field on the right side. This is inevitable as, by definition, there is no indexed data for runtime fields.
A use case example: Joining composite keys
In this example, we will demonstrate how we can use runtime fields to perform a join on composite keys, that is, a join key that is created by concatenating values from two fields.
First, we define the mapping of a “person” index with a “fullname” runtime field that is a concatenation of the “firstname” and “lastname” fields of the same index.
PUT /person
{
"mappings": {
"runtime": {
"fullname": {
"type": "keyword",
"script": {
"source": "emit(doc[\"firstname.keyword\"].value + \" \" + doc[\"lastname.keyword\"].value)"
}
}
}
}
}
Then, we add two documents to the indices.
POST /person/_doc
{
"firstname": "alice",
"lastname": "dupont"
}
POST /post/_doc
{
"author": "alice dupont",
"title": "Let's go to Mars"
}Finally, we can join the two indices and retrieve all of the people who have written a post. Note that the “fullname” runtime field is used as the join key.
POST /siren/person/_search
{
"query": {
"join": {
"indices": [
"post"
],
"on": [
"fullname",
"author.keyword"
],
"type": "HASH_JOIN",
"request": {
"query": {
"match_all": {}
}
}
}
}
}The benchmark test
In our benchmark test, we measured the impact of runtime fields on the performance of the join operation. We compared the performance of a join operation based on fields computed at index time (the baseline) with a join operation based on runtime fields.
The benchmark test was performed on a 3-node cluster in Google Cloud (n2-highmem-8, Cascade Lake, SSD, 64GB). We executed each query 25 times and we reported the 90th percentile.
The dataset
The dataset consists of two indices: a “parent” index with 2 million documents and a “child” index with 10 million documents (with an average of 5 “child” documents linked to one “parent” documents). A “child” document includes a keyword field, “pid”, which is a foreign key to the primary key “id” of the “parent” index.
A field, “pid_pid”, which consists of the concatenation of the same “pid” keyword value twice, is created at index time. Similarly, a field, “id_id”, which consists of the concatenation of the same “pid” keyword value twice, is created at index time. A runtime field, “pid_pid_rt”, is specified in the index mapping, defining a runtime field that concatenates 2 keyword values as shown below:
PUT child/
{
"mappings": {
"runtime": {
"pid_pid_rt": {
"type": "keyword",
"script": {
"source": "emit(doc['pid'].value + doc['pid'].value)"
}
}
}
}
}The query
The query consists of joining the 10M “child” documents with the 2M “parent” documents, using the fields “id_id” and “pid_pid” for the baseline scenario, and using the fields “id_id” and “pid_pid_rt” for the runtime scenario.
GET /siren/parent/_search
{
"query": {
"join": {
"indices": [
"child"
],
"on": [
"id_id",
"pid_pid"
],
"type": "HASH_JOIN",
"request": {
"query": {
"match_all": {}
}
}
}
}
}Baseline query
GET /siren/parent/_search
{
"query": {
"join": {
"indices": [
"child"
],
"on": [
"id_id",
"pid_pid_rt"
],
"type": "HASH_JOIN",
"request": {
"query": {
"match_all": {}
}
}
}
}
}Runtime query
The results
When comparing the performance of the baseline versus the runtime scenarios, a performance impact is observed as expected, since runtime fields are – literally – computed at runtime (see Elasticsearch notes on this). The query response time of the runtime scenario is 75% higher than for the baseline.
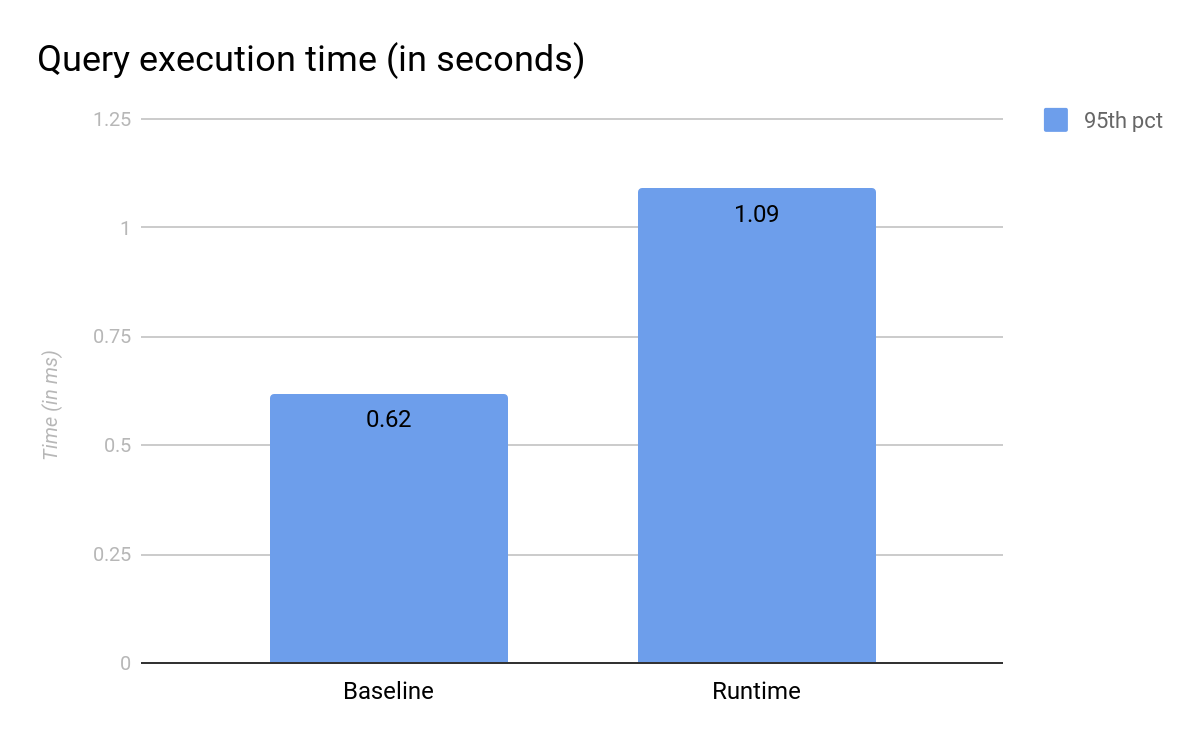
All-in-all, the response time is still within an acceptable range and the performance impact should not exceed the one perceived on a classic search query on runtime field. The discrepancies are only due to script evaluation for concatenating the values and, as soon as runtime field values are computed, the join operation does not suffer any additional complexity.
What’s next?
Federate v26 will further increase performance as the query processing model moves to a fully vectorized model optimizing CPU cache and increasing the throughput of the worker threads. Our initial tests show a significant performance improvement, so stay tuned for more.
Written by: Renaud Delbru, Gerard Dupont, and Stephane Campinas















