
Why we are adding Join capabilities to Elasticsearch
It is common for an analyst to have to answer advanced questions such as the ones below during their investigation:
- Find me the total amount of traffic of users who signed up in the last 30 days.
- Are these two users connected by less than four degrees of separation, based on phone calls, social networks, or tweets?
- Find me the location of the people who made phone calls last week to any of the “group Alpha” suspects.
- Draw a bar chart to represent the type of purchase, grouped by country of residence of the customer.
- Who was logged in at time X?
- Find me tickets with negative sentiment, ordered by the amount of business that the customer generates.
Can you tell what all of the above questions have in common? You guessed it: They all require joining data across different indexes, which is what Siren Federate enables directly inside your Elasticsearch environment.
The Siren Federate plug-in
Siren Federate extends the standard Elasticsearch Query DSL with a new query clause, which enables the execution of a join between indexes. Custom applications, or applications like our own Siren Investigate, can use the new query clause to answer questions like those above.
Introducing Siren Federate 20.0!
Before today, the join capabilities of Siren Federate were limited to a semi-join between two sets of documents. The semi-join is used to filter one set of documents with a second set of documents, based on a common attribute. It is equivalent to the EXISTS() operator in SQL. This can answer questions 1 to 3.
Today, we are excited to announce the availability of Siren Federate version 20.0, which supports inner join capabilities, thus answering questions 3 to 6, which require the combination of both sets of documents… and, obviously, many more.
The inner join has long been a standard in the SQL database world. With this release, we are now adding inner join capability to search; and more specifically, to the world of Elasticsearch.
More on inner joins
In the database world, the inner join feature enables the ‘projection’ of arbitrary fields (including script fields and a document’s score) from a set of documents A, and ‘combines’ them with a set of documents B, based on an inner join operation.
The projected fields and associated values from a document from set A are mapped to all of the documents from set B, which satisfies the join condition. The result of the join is the set of documents B, augmented by the projected fields from the set of documents A.
This allows an analyst to answer questions, such as those above. For example, with question number 5, a user may be linked to one or more sessions and a session may be linked to one or more events such as login, logout, unauthorized actions, etc.
It is difficult to answer questions such as “find all users that were logged in at time X” or “find all users displaying irregular online activities” from a disparate set of records. The inner join enables the collection and the grouping of multiple events into a particular context, which can ultimately answer that question.
Overview of the API
To project a field, the user can use the “project” parameter in the request body search of a join clause, as follows:
POST siren/company/_search
{
"query" : {
"join" : {
"indices" : ["article"],
"on" : ["id", "companies"],
"request" : {
"project" : [
{
"field" : {
"name" : "source",
"alias" : "article_source"
}
}
],
"query" : {
"match_all" : {}
}
}
}
},
"script_fields" : {
"article_source" : {
"script" : "doc.article_source"
}
}
}In this example, the field “article.source” from the index “article” is projected as a field, “article_source”, and merged with the documents from the index, “company”.
The results of the join include documents from “company” with a multi-valued field, “article_source”, as shown below:
"hits": [
{
"_index": "company",
"_type": "Company",
"_id": "cLe25XIBVxExr04NmH86",
"_score": 1,
"_ignored": [
"deadpooled_date"
],
"fields": {
"article_source": [
"TechCrunch"
]
}
},
{
"_index": "company",
"_type": "Company",
"_id": "KLe25XIBVxExr04NmH45",
"_score": 1,
"_ignored": [
"deadpooled_date"
],
"fields": {
"article_source": [
"Mashable",
"TechCrunch",
"VentureBeat",
"ZDNet",
...
]
}
},
...
]The inner join operation is based on a partitioning hash join algorithm. (Sounds complicated, doesn’t it? Read more about this type of hash join here.)
It is a fast, state-of-the-art algorithm that is optimized for operating in main memory. The algorithm is parallelized to use the available computing unit (CPU cores) in each node, in order to scale vertically. The algorithm is also distributed to use the available computing nodes in the cluster, in order to scale horizontally.
The projected fields are encoded in a columnar format, using Apache® Arrow™, and stored in the off-heap memory, therefore avoiding consuming the heap memory that is used by Elasticsearch.
The associated field values can be accessed using the doc-values API in various script contexts such as the field context, the score context, the sort context, the aggregate context, and so on.
For example, this enables the analyst to sort the companies, based on the query-time scoring of their associated articles, as shown below.
First, we specify the projection of the scores (“_score”) from articles matching the term “cybersecurity”.
Then, we define a function score query to modify the score of the documents from the index “company”.
The function score query is based on a script score that accesses the projected field “article_score” and sums up the scores of the associated articles for each company. The sum is then used as a custom score for the company document.
POST siren/company/_search
{
"query": {
"function_score": {
"query": {
"join": {
"indices": ["article"],
"on": ["id", "companies"],
"request": {
"project": [
{
"field": {
"name": "_score",
"alias": "article_score"
}
}
],
"query": {
"match": { "snippet": "cybersecurity" }
}
}
}
},
"functions": [
{
"script_score": {
"script": {
"lang": "painless",
"source": "float sum = 0; for (value in doc.article_score) { sum += value } return sum;"
}
}
}
],
"score_mode": "multiply",
"boost_mode": "replace"
}
}
}As you can see, the inner join and the integration of the projected fields in the script contexts provide a lot of flexibility to cater for different scenarios.
For more examples of how to use the new inner join feature, see the Query DSL documentation.
Use it in your applications; or soon in Siren Investigate
The inner join feature can be used by any application, simply by using the extended Siren Federate API.
We are, however, currently working on its integration in Siren Investigate. This will bring new investigation capabilities, basically allowing analysts to answer questions 1-6 in the list above. It will be possible to use augmented documents with projected fields in a visualization, avoiding the need to materialize the documents at indexing time.
This ability will complement the already existing Dashboard 360 feature. Dashboard 360 enables a single dashboard to contain visualizations that are derived from different data sources, and to perform coherent, relational filtering across all of them.
The new Siren Federate architecture
In the 20.0 release, there are also big improvements at the architecture level. We replaced our in-memory vector data model that is used to encode the projected fields in a columnar format, with the vector model of Apache Arrow.
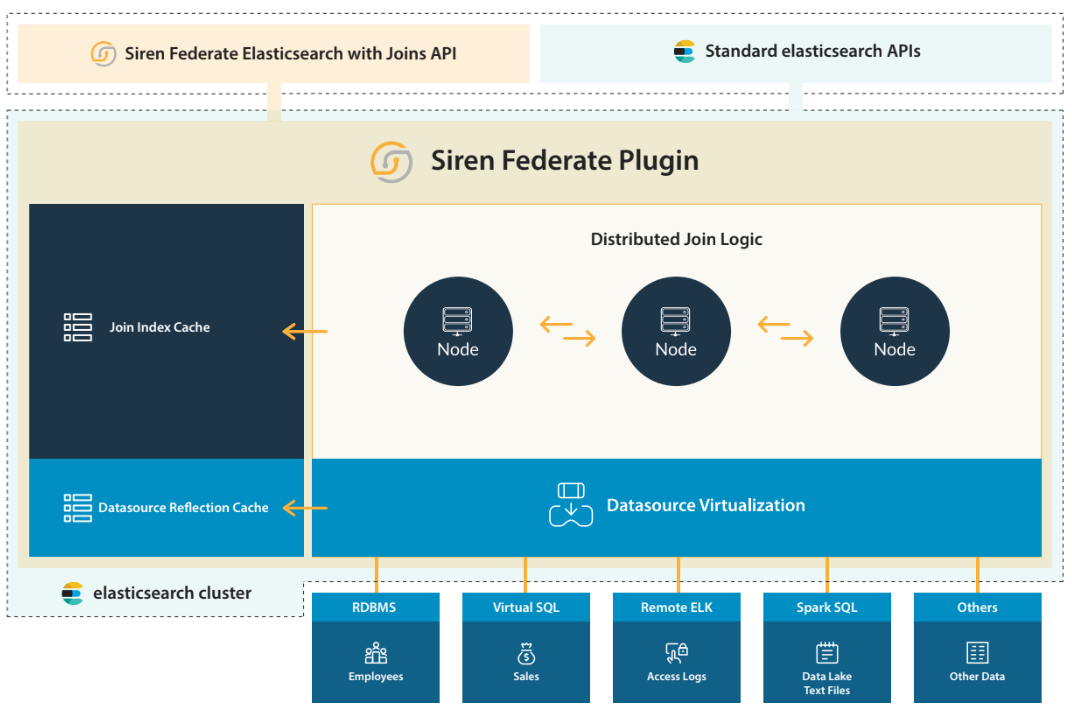
This update also paves the way to support more advanced data types, such as array, struct, or nested. It will also ease the implementation of future optimizations, such as dictionary encoding for the string data type, and, in perspective, a standardized data exchange with other big data systems for next generation, efficient, cross-back-end joins.
The new release for Federate 20 – Federate 7.8.1-20.1 is available today, compatible with the latest Elasticsearch releases. Get it now!















