

We are super happy to announce today the availability of the Siren platform version 5.4.3-3, likely the last release before our next generation “Version 10” (see later).
Among the other improvements, this version is important as it introduces:
- UI Access Rules. Block any part of the UI (or specific functions within widgets) per user group;
- Full compatibility with X-Pack and the latest of Elasticsearch 5.x (5.6.4 as today);
- UI configurable circuit breakers for large joins. Configure large cross-index joins in confidence. If limits are reached, sample results will be returned (and the UI will indicate partial results with a *).
Let’s see a bit more in details.
Welcome “access rules”
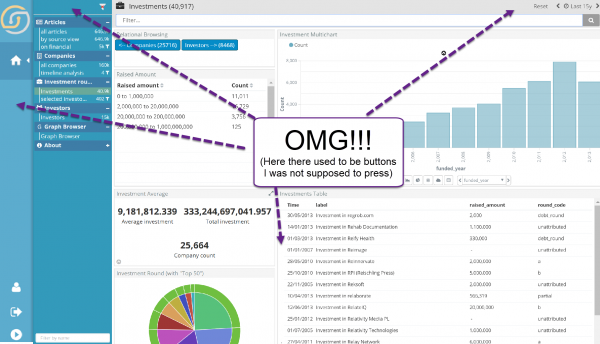
It is a fact that not all users need to see all buttons 🙂 .
Up to today, Siren allowed fine-grained per table, per column, per row and per UI object (e.g. dashboard, widget, script) permissions. While this is “the basic”, we are dedicated to make Siren a flexible platform that can be visually simplified (or tweaked) as much as it needs to be especially for “simpler” users.
This version of Siren introduces the ability to block the view and underlying access to basically any UI functionality, from access to installed Apps (e.g. Discovery, Timelion, Sentinl) or the configuration menu, to more subtle UI elements like the CSV export and more.
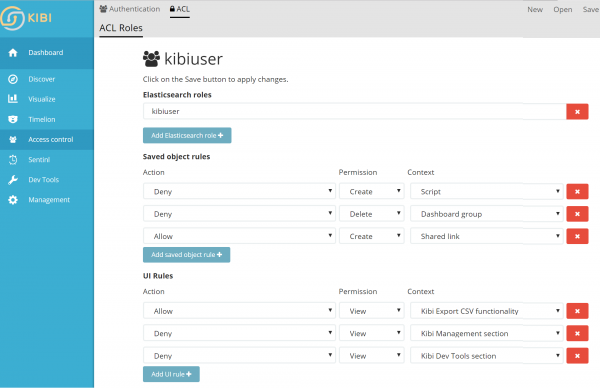
This functionality is easy to setup in the ACL section of the Access Control application:
X-Pack compatibility
Kibi now supports Elastic X-Pack natively by providing a login page and granular access control rules on Kibi objects to X-Pack users.
UI configurable circuit breakers for large joins
How much does it take to open a dense analytic dashboard showing 120 Million phone calls (CDRs) and including 6 complex joins filters with indexes of similar size, on a single node cluster?
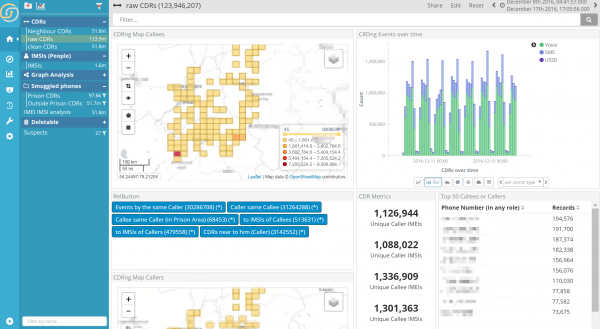
Just about 10 seconds. Which makes perfect sense for usage. The magic here is the new flag (the * on the relational buttons) indicating just a sample of the results are being shown in the counts.
Drill down to a more specific question (e.g. just the calls from 1 to 3, still on the whole dataset) and you get exact results.
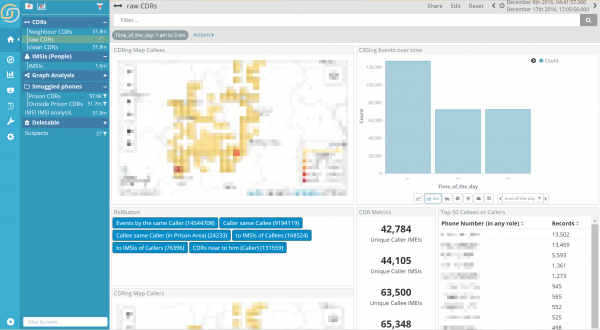
Circuit breaker limits are configurable, of course, to suit your hardware, use case… and patience 🙂 but, frankly, they work like a charm, while we wait for Siren 10 new fully distributed join engine (see below).
Heads up: Siren 10 is coming
Yes! We are skipping a few numbers as we are adding tons of stuff all at the same time 🙂 .
The next major edition of the platform will be called… Siren 10, with its components renamed to:
- Alert – what is now Sentinl;
- Investigate – for your beloved Kibi;
- Federate – for the backend components, one of which, very notably, is the Elasticsearch plugin for Joins (currently called Vanguard) which will be named Siren Federate plugin for Elasticsearch.
From this version we break away from the previous Kibana-like numbering to reflect Siren 10 support for many more backends than just Elasticsearch (but worry not: we will retain compatibility with Kibana plugins).
As a pretty picture it looks something like this:

What’s new in Siren 10
Not all your data is in Elasticsearch?
No worries: the next major edition of Siren will support for multiple backends dashboard analytics via JDBC connections. Your JDBC Datasource of choice is mapped as a “virtual index” within Siren Federate and can be used with any standard Siren Investigate (was Kibi) or Kibana widget.
Featuring big data join pushdowns, supporting Kibi unique “set to set” navigation and multiple level aggregations.
Lots and lots of data in Elasticsearch?
With Siren 10 fully distributed Elasticsearch join technology, your performance scales with the size of your cluster, specifically with a whopping 90% average efficiency in hardware usage as cluster size or, most of the time, processor cores are doubled (where 100% would be the ideal twice the size, twice the speed). Initial benchmarks to be published soon.
And then…
Other Siren 10 features:
- OWL based datamodel. Greatly simplify the analysis when many indexes are present.
Automatically proposes destination dashboards one can possibly connect to; - Big Data aggregations on graph edges. Millions of A to B logs summarized instantaneously on the graph browser, with automatic detection of all possible fast (pushed to backend) aggregations across indexes;
- (Data and Life science users) Big data, interactive, cross-index, high-dimensionality correlation explorer (if this isn’t cool then nothing is – and you should see it in motion);
- …and several others (data preparation/easy load, SQL over all) to be announced.
Stay tuned for much more coverage on this.















