

Introducing a fully columnar join engine for Siren
Investigations in large scale datasets are all about finding connections between records, an operation which at large scale is known as join (or correlation).
For example, an investigator might ask which phone numbers were present at multiple locations, whereas at each location, millions of other phones were present at that time.
Federate is Siren’s multi-patented technology to extend Elasticsearch with real time correlation/join capabilities, and is at the heart of the real time / interactive performance of the Siren Platform.
Thanks to Federate, investigators get the unparalleled capability of interactive data exploration – in instances covering billions of streaming records and in scenarios such as in large scale OSINT, COMINT/SIGINT and CYBERs.
Today we’re very excited to release our latest benchmark of Federate 27.4 – a major upgrade now employing a fully vectorized processing engine capable of joining datasets in the 10+ B range at interactive speed.
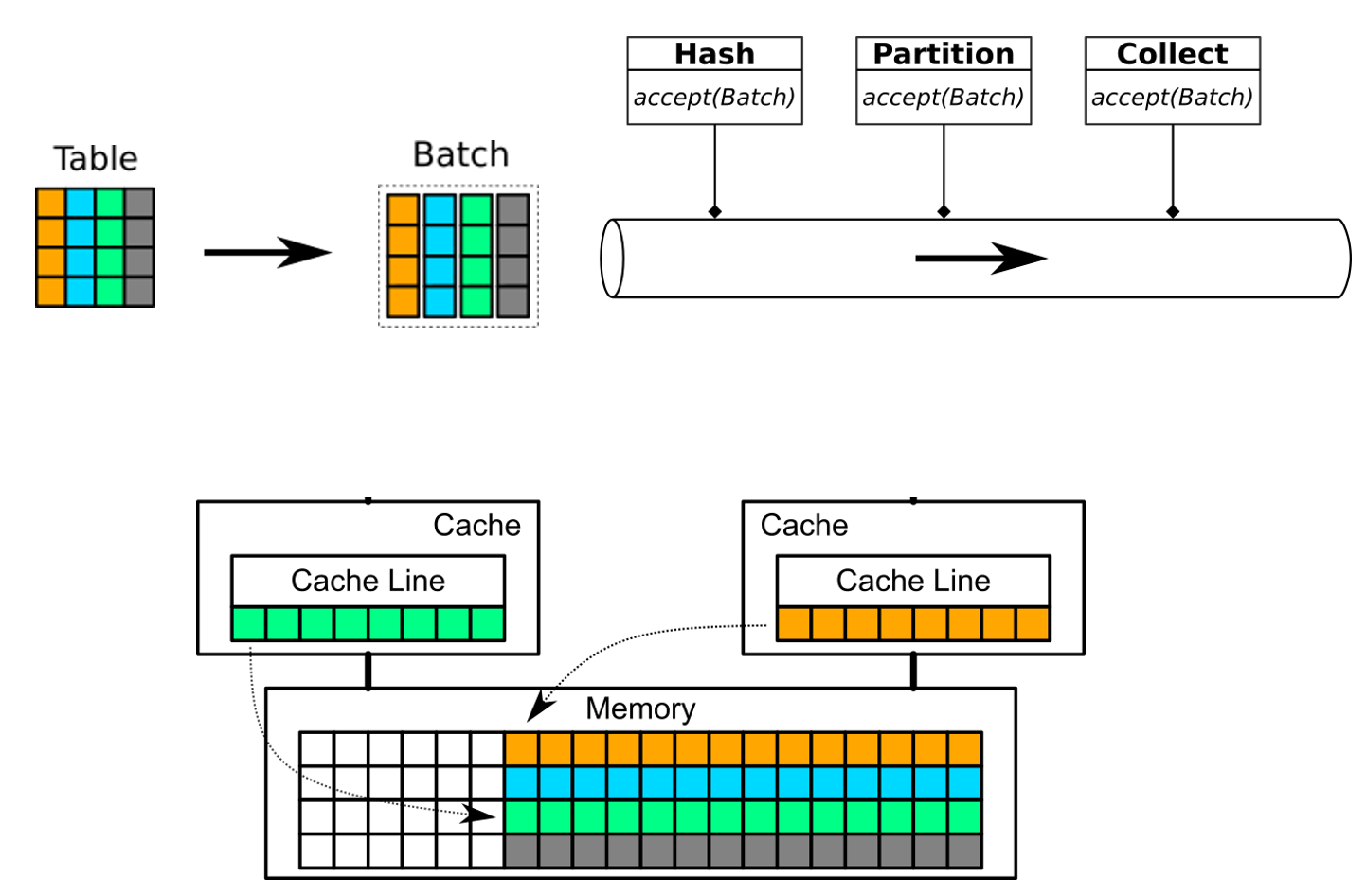
Columnar data processing allows batch processing and results in higher CPU efficiency. See the whitepaper for details
TLDR: How does the new version compare?
If you have time for a single takeaway let it be this one: the new Siren engine is basically twice as fast and thrives on Billion+ datasets.
The following graph shows the speed comparison between datasets of 350 Million, 2 Billion (just getting started!) and 4 Billion records:
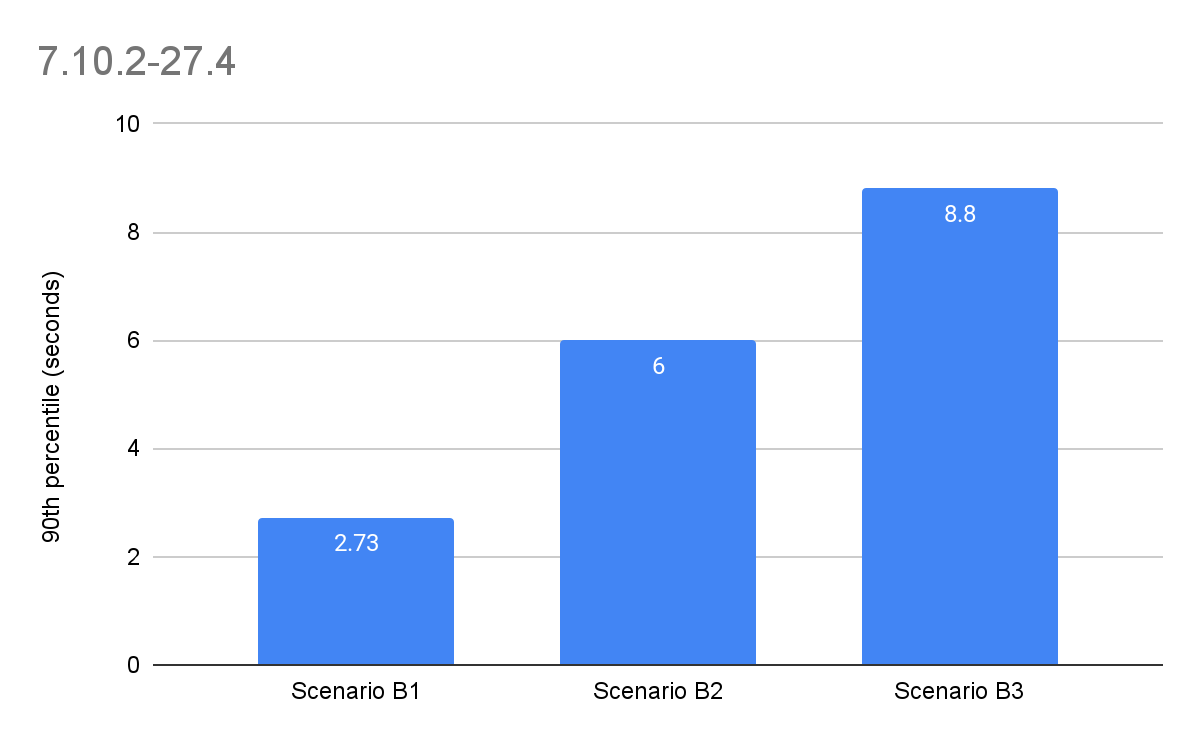
Also, the new engine sports an impressive “quasi linear” scalability with respect to the number of users and the size of the cluster.
Read the full details in the benchmark paper here including tests all the way to 15b records.















