
We are very excited to introduce Siren Platform version 11, a major step forward for teams conducting advanced Signals Intelligence (SIGINT), Cyber Intelligence (CYBINT), and Open Source Intelligence (OSINT) investigations.
Siren Platform 11 introduces an elegant way for parallel teams of analysts to investigate data, in segmented, case-specific environments called Dataspaces. Along with this, we provide functionality that seamlessly supports enterprise workflow and collaboration.
In addition, new functionality has been added, including advanced support for Natural Language Processing (NLP) and a set of visual and analytics capabilities to analyze geographical paths.
Now, let’s get into the details of this major step forward for Siren Platform.
Dataspaces
Dataspaces allow you to easily manage separate groups of users, projects, and investigations, on either the same data set or on different data sets, in the same Siren Investigate instance. In the past, this was only achievable by working in separate instances of the application.
Each dataspace may contain different dashboards and visualizations according to what the investigation requires, including any reports needed.
When you log into Siren Investigate, the default dataspace is called HOME. The dataspace you are operating in is called the current dataspace, which contains its own data, settings and objects.
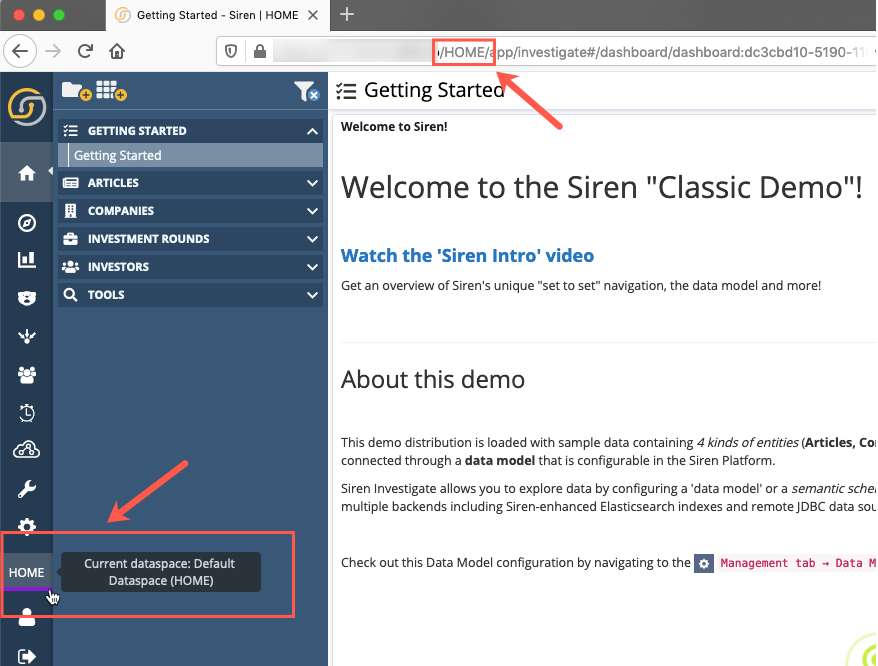
The dataspace selection button opens the dataspace panel, where you can switch to another dataspace by clicking on its short code.
Working with dataspaces
Depending on your user role permissions, you can create, clone, or edit dataspaces, and you can invite other user roles to participate in it.
There is also the option to upload data to a specific dataspace using the Excel/CSV import tool. The uploaded file will only be visible to the users who have access to that dataspace.
A working environment in Siren Investigate comprises different types of saved objects:
- Dashboards
- Visualizations
- Data model items, for example:
- Searches, including index pattern searches
- Entity identifiers
- The data model visual layout
- Watchers
- Results from Web services that are configured accordingly
Dataspaces enable the creation of independent sets of saved objects, also called object partitions, and gives the ability to different user groups to work separately and to create as many objects as needed for an investigation.
The Saved Objects section of the Management screen shows the full list of object types, which are divided between global objects and current dataspace objects.
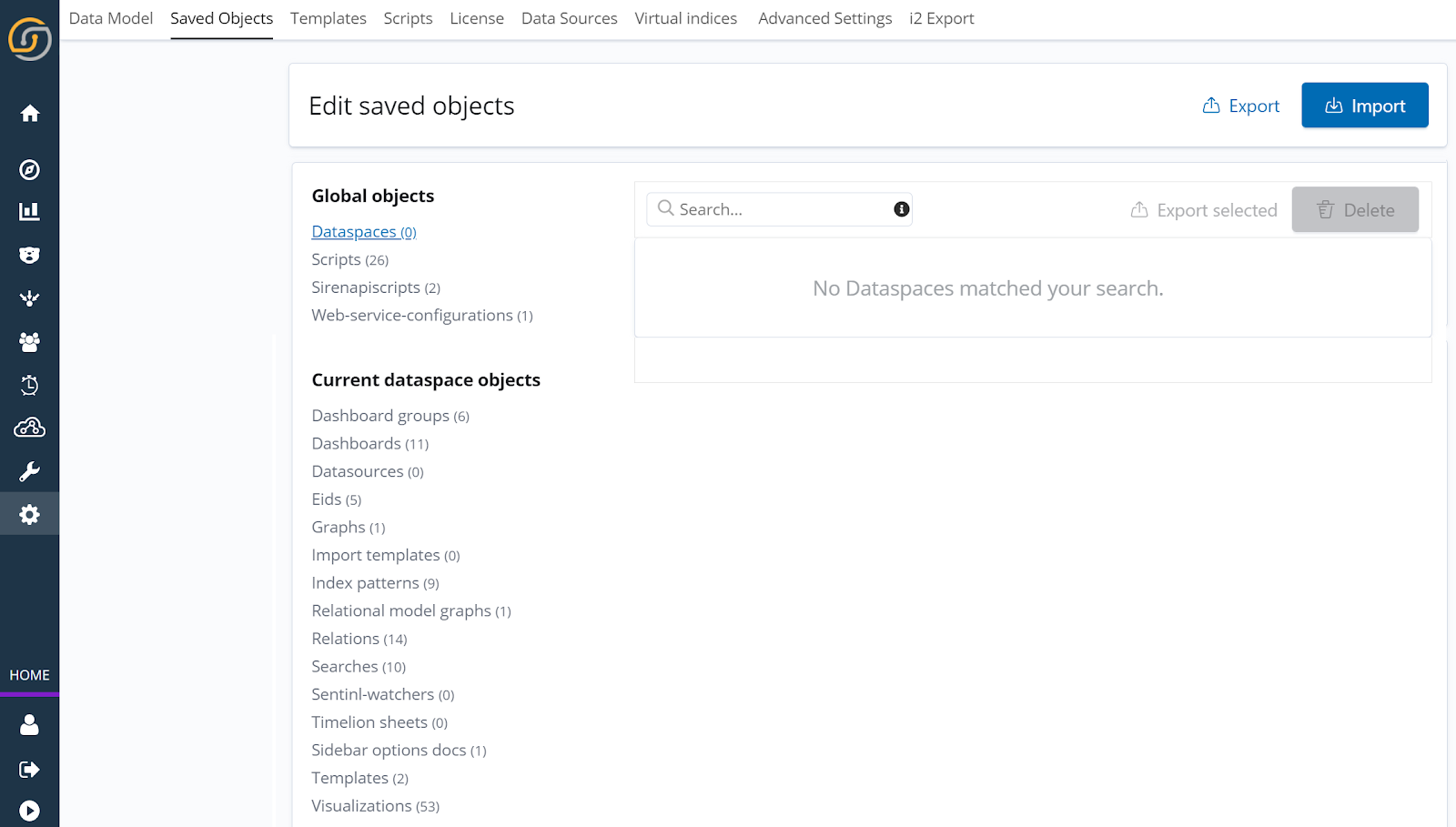
When are dataspaces useful?
In general, dataspaces are object partitions, which can be used for many purposes, such as to create completely independent Siren environments – for example, in a multi-tenant environment or to handle different projects.
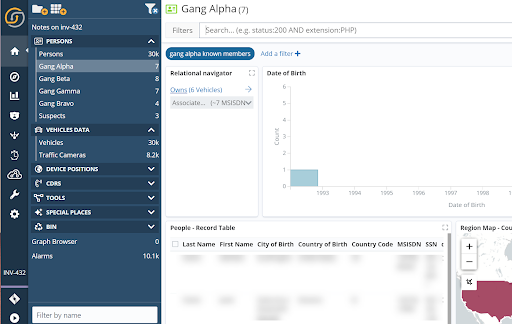
A typical use of dataspaces, however, is to partition objects per investigation, by initially cloning a master dataspace that contains the generic dashboards into one that can be customized on a case by case basis.
For example, a deployment could have a general dashboard called “People” in the home dataspace. Then in a dataspace for an investigation, one can easily create new dashboards filtered for particular groups of people that are relevant to the case, for example, “Gang Alfa”, “Gang Beta”, and so on.
Enhancements to the Record Table visualization
Search results can now be enhanced with cell formatters. In the Record Table visualization, you can now apply cell formatters, some of which are dedicated to use cases involving Natural Language Processing (NLP).
These cell formatters display NLP annotations as highlighted words and tags (values in an array), which can be clicked to create filters on the data.
This feature is further enhanced by the ability to manually revise (add / modify / delete) tags in documents, as part of the next feature, virtual document editing.
Virtual document editing with Revision Indexes
It is now possible to change a record without actually changing the original Elasticsearch indexed document – but, also, to create or delete records (full CRUD capabilities).
This capability can be enabled from the Data Model screen by activating the Revision Index feature. Virtual editing means that when a record is edited, all of the edits go to a separate index and the original index is left unchanged. The two indexes are then “superimposed” and the older document is hidden by a filter, so that the net effect is that of editing the data while preserving all of the previous versions.
If the revision index feature is enabled for the current index pattern search and you have user permissions to edit its documents, then the following options become available:
- The toolbar at the bottom of the table has an Add New button that you can use to create documents from scratch.
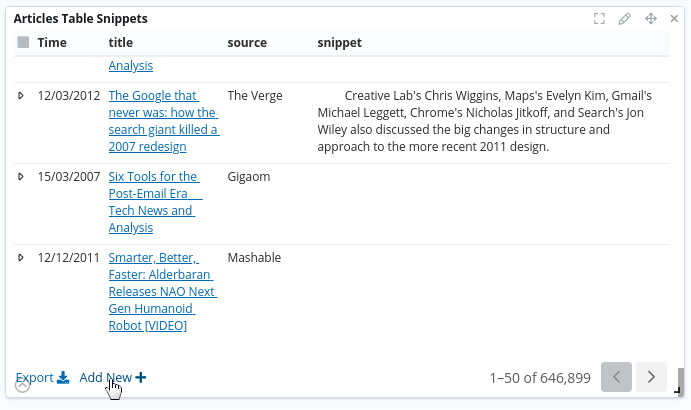
- The new detail screen, where you can look at individual documents, shows an Edit button and a Delete button.
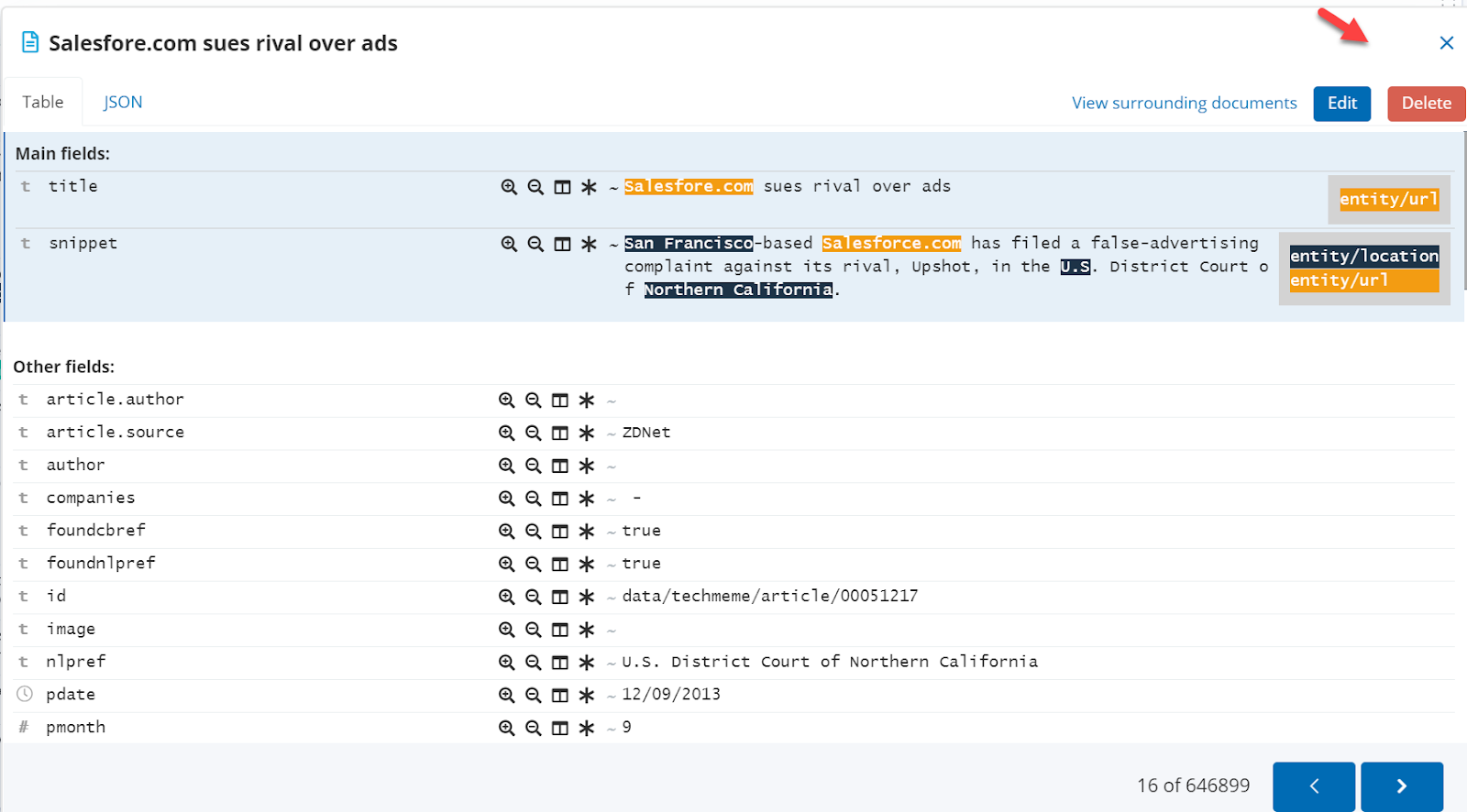
- Values can be edited
- NLP tags can be edited individually and textual feedback can be entered, which can be used to improve the NLP capabilities as part of a workflow.
When a revision is made, the previous version of the document is stored and can be retrieved from the document’s history.
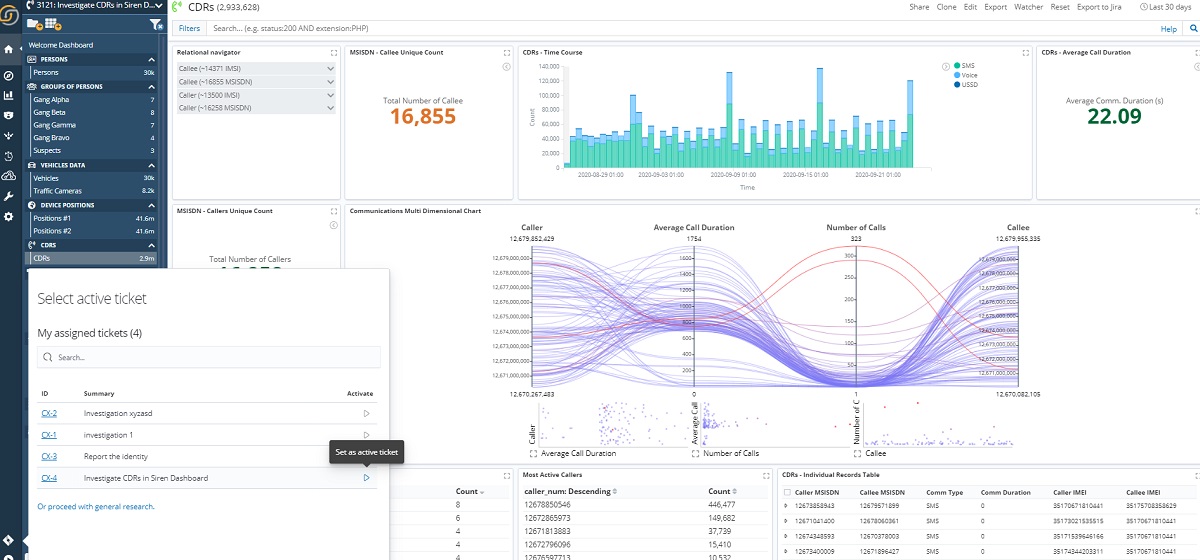
Supporting a typical investigative flow with the Siren Jira integration
Collaboration and workflow is critical in investigative intelligence. Now, by default, Siren Platform 11 has the ability to work seamlessly with Jira.
This enables workflows as follows:
- The user logs in and is presented with a list of tasks that he/she is currently assigned to and is prompted to select the one that he/she are currently working on (reason for investigation).
Administrators decide if this initial “check in” is mandatory or voluntary and if one has the option to create a new ticket directly from the Siren interface. - From this point, all the information that goes in the audit logs will also report the Jira ticket as part of the record.
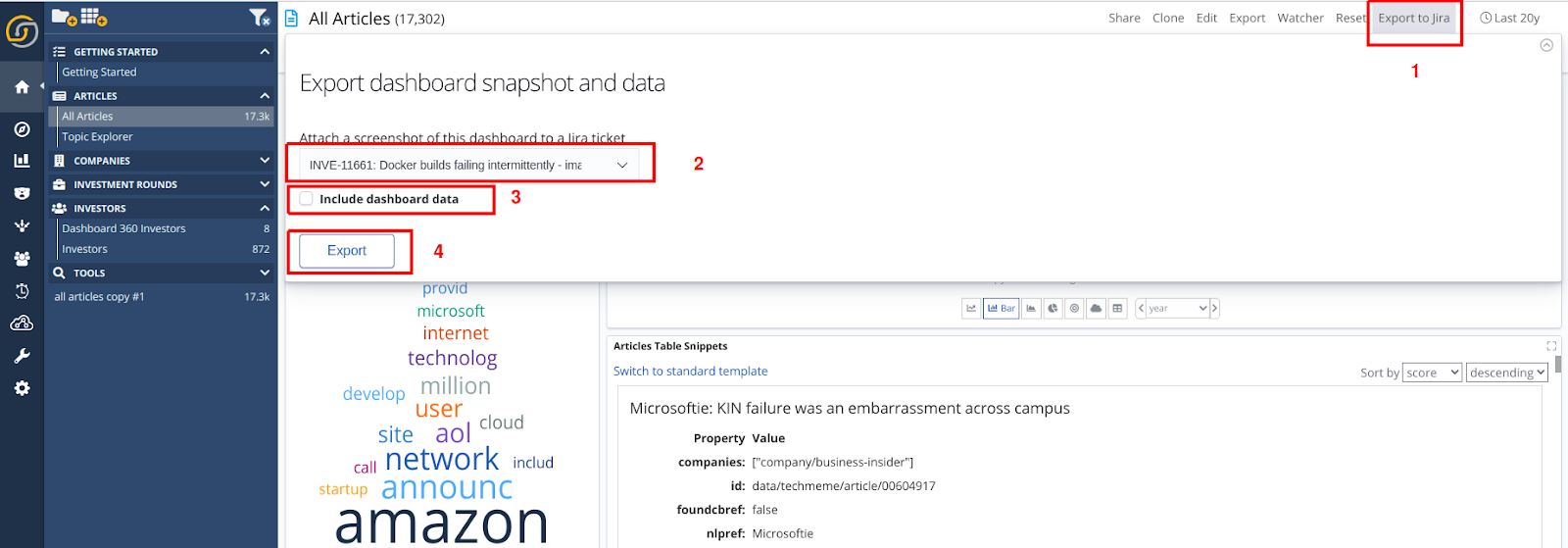
- At any time, one can export information directly to the Jira ticket; screenshots of the current dashboards, as well as sample exports of the data.
- Finally, the Jira ticket can be progressed to “Done” and revised by supervisors as defined in the Jira workflow.
Technically, the Jira plugin allows the connection of Siren Investigate to a Jira cloud or on-premise instance.
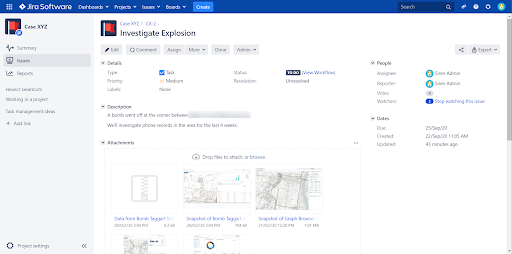
Lets see this in action: The user is greeted by the Jira plugin prompting the selection of a ticket, picking from those that are currently assigned to the logged in user.
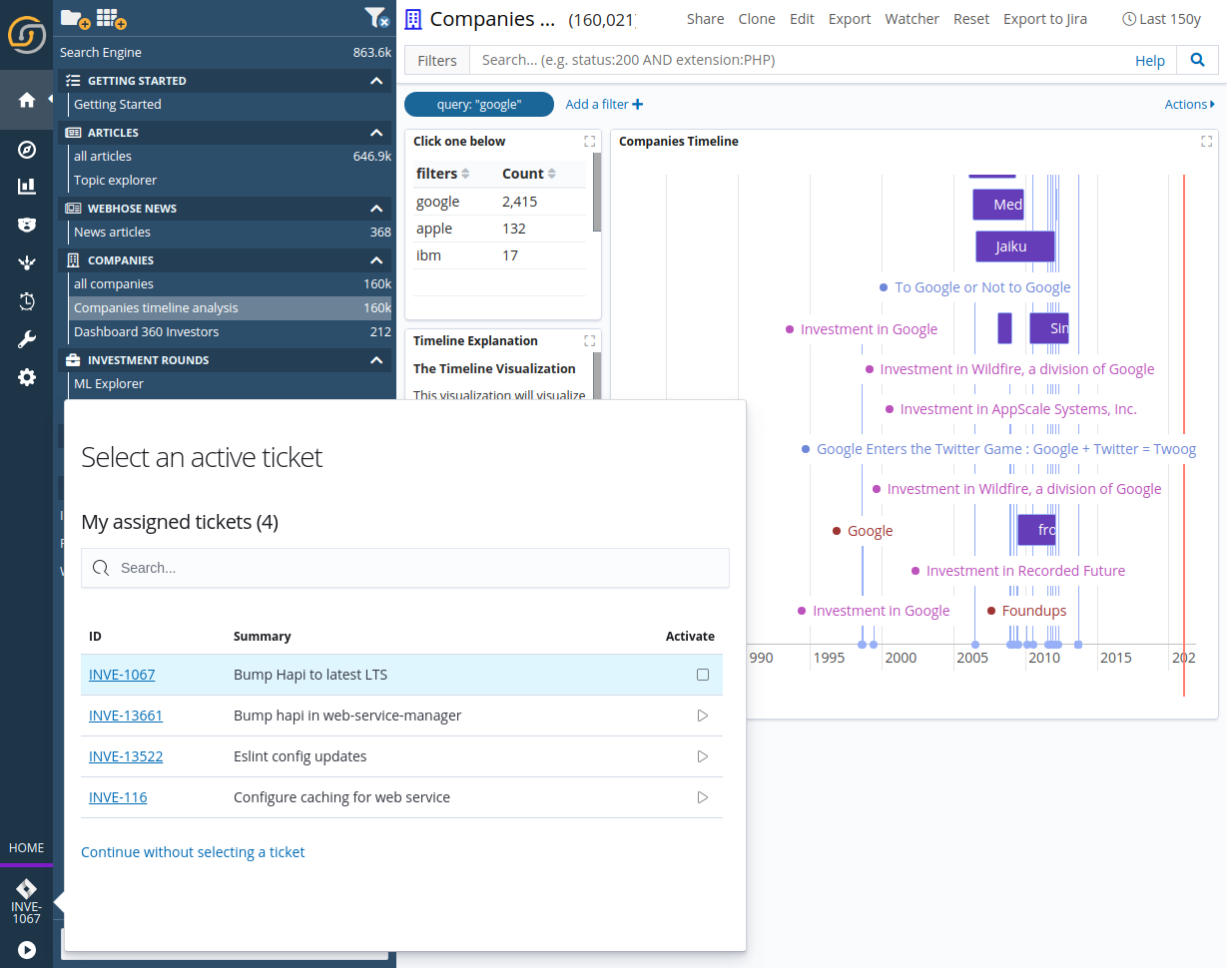
Once a ticket has been selected, all the auditing logs will be connected to this ticket. At any time, it is then possible to export the current dashboard information (screenshots or sample records) to the ticket from a new menu option.
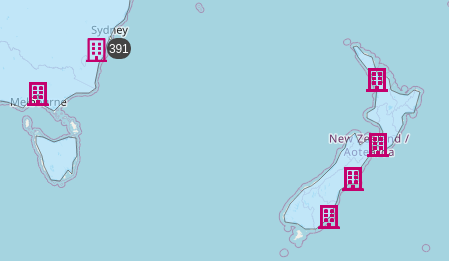
Enhancements to the Coordinate Map
Marker clustering is now enabled on the Enhanced Coordinate Map, allowing all documents on the current map canvas to be represented at once. It is used by Point of Interest layers and Stored Layer sources.
Full support of OpenID Connect integration with Elastic Stack Security
You can now integrate Siren Investigate with the OpenID Connect authentication support that is provided by Elastic Stack Security. For more information, see the documentation.
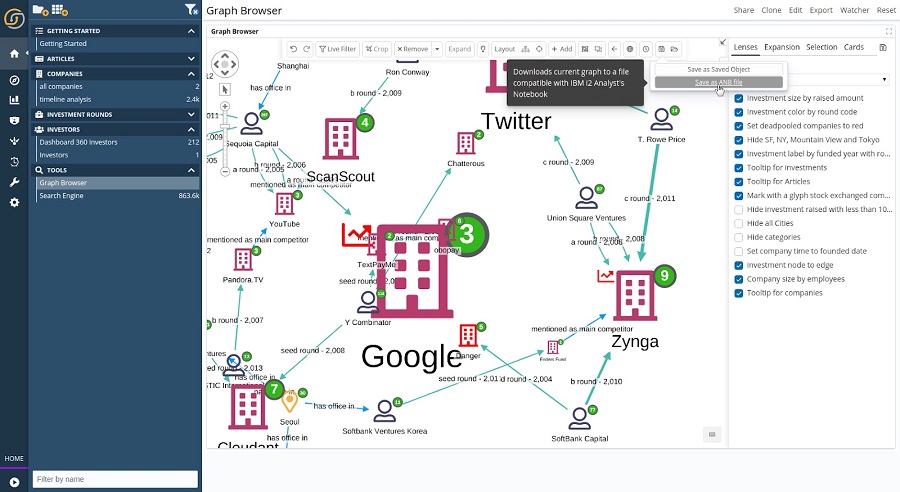
IBM i2 Analyst’s Notebook plugin is now included by default
The i2 Analyst’s Notebook plugin for Siren Platform is now included by default. This makes it possible to export any Siren Graph into an ANB graph file, which can be read by i2 Analyst’s Notebook.
The Siren NLP plugin is now in the default distribution
The Siren NLP plugin is an Elasticsearch side processor which provides an ingestion pipeline block with a variety of processors for enriching documents with entity extraction.
The plugin enriches text fields with annotation for Named Entities (Organization, Person, Location) and by spotting terms from predefined taxonomies. The plugin is now made available by default in the Siren Platform distribution and has been made simpler to use out of the box – the perfect match for the new NLP annotation visualization capabilities in the front-end system.
Introducing templates for intelligence solutions
Siren Platform 11 introduces templates for Signals Intelligence (SIGINT), Cyber Intelligence (CYBINT), and Open Source Intelligence (OSINT) investigations, providing example dashboards, data models, and supporting Web services; all of which address some of the most critical problems in national security.
The templates enable analysts to visualize device positions in real time or historically at a scale of billions of records, perform contact tracing based on device positions, and find aliases.
For Cyber intelligence, version 11.0 includes a MITRE ATT&CK-based data model and template deployment for top-of-the-cyber-pyramid threat intelligence and threat hunting.
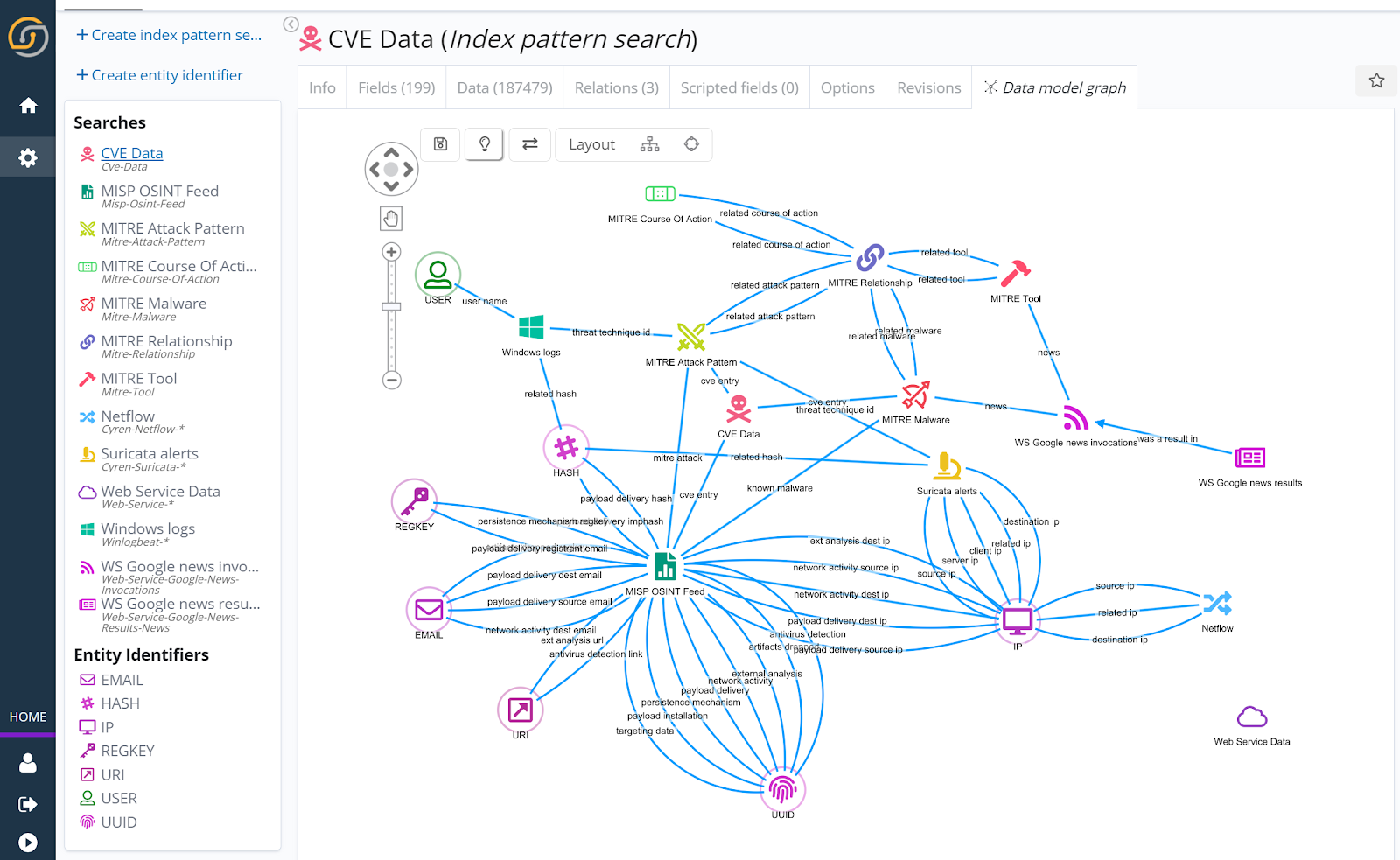
Are you interested in seeing the templates in action – and learning how to build on top of them? Contact us for a demonstration.
Scalability and security
Siren Platform 11 introduces numerous performance and scalability improvements. A lot of these improvements are in the front-end system: Siren Platform 11 loads now in less than half the time of Siren Platform 10 and is much more scalable in terms of the number of searches and objects that can be handled in different parts of the applications.
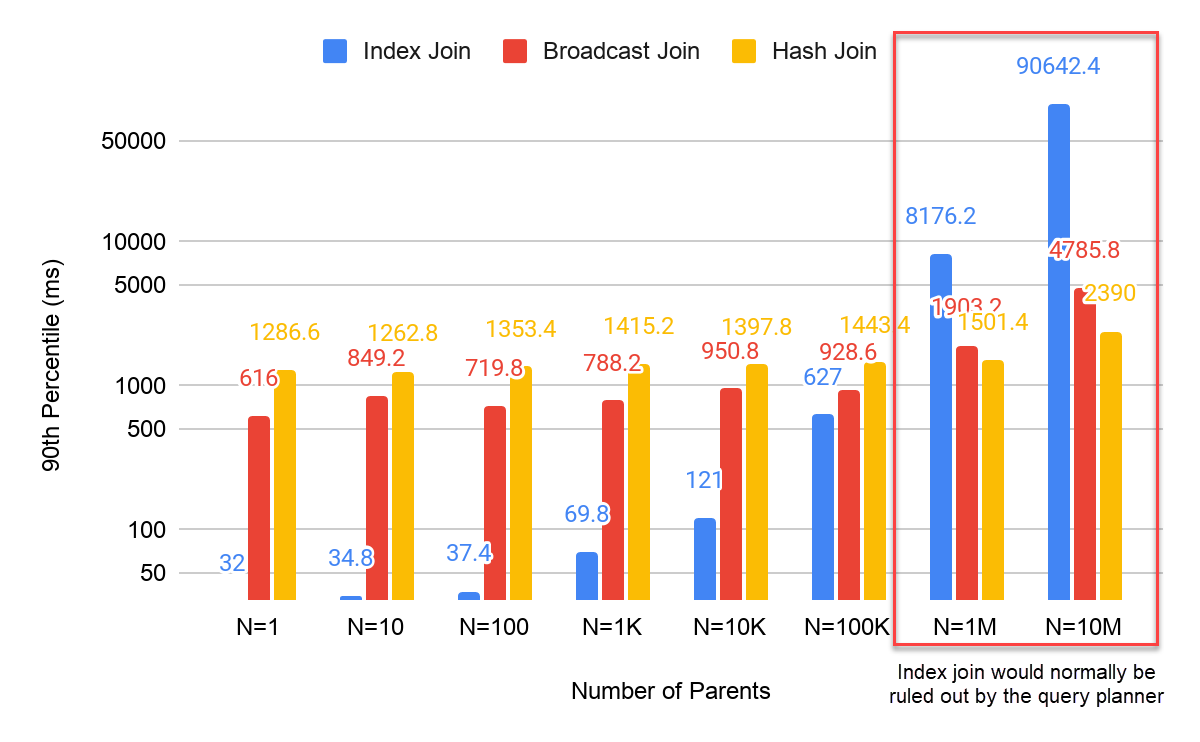
On the back-end level, Siren Platform 11 also introduces a new, fast join strategy in the arsenal of the query planner: the index join.
In the following chart, a join between 1 to 10M “parent” records and 50M “children” records is executed on a 3-node cluster and time is measured in milliseconds, demonstrating speedups in excess of 10x when the number of parent records is a few hundreds of K.
This scenario (joining on a small subset of the whole) is, in practice, extremely useful and common and that’s why we’re excited at the impact of this new feature.
Auditing
Auditing capabilities have been enhanced. An activity log will be populated with the analyst’s searches in Siren Platform. A link to the index containing this activity log will be recorded in the Jira ticket corresponding to the active task. The activity log stored in Siren will include a field with a link to the Jira task, the analyst working on the task, and the project name.
Get it now!
We’re extremely excited about Siren Platform 11 and we believe you will be too. Here are some resources to get started:
- The full documentation
- The download page
- The new updated Siren 11 getting started tutorial
- The Siren Platform 11 launch webinar: Watch On Demand















