
(This post was originally published on LinkedIn by Giovanni Tummarello, CPO & Co-Founder of Siren)
While the term knowledge graph is relatively new, (Google 2012) the concept of representing knowledge as a set of relations between entities (forming a graph) has been around for much longer.
For example, 2019 marks the twentieth anniversary of the publication of arguably the first open standard for representing knowledge graphs designed with web distribution and scale in mind: the W3C RDF standard.
But what I am excited about for the year ahead is how 2018 closed with really solid progress in enterprise grade knowledge graph technologies, and strong evidence of adoption.
Before I get into the details, first allow me to provide some history and introduce some important concepts.
How did we get to where we are in knowledge graphs?
Back to RDF. Twenty years might seem like a long time, but the ideas behind it had in fact been described as early as in ancient Greek philosophy and, unsurprisingly, very few things are more natural to the human mind than thinking about knowledge in terms of entities connected by relations.
However, as recently as the 1990s, neither the technology nor the mentality were in position for computers to enable knowledge graphs. It was all about tables (spreadsheets, database tables) or at most hierarchical data (XML).
It was the fervid desire to revolutionize this that pushed Tim Berners Lee to lead the effort on RDF. Together with the ability for people to publish data on the web, RDF was going to turn the web from a big collection of documents into a big, distributed knowledge graph (commonly referred to as the semantic web).
In hindsight, we can say that the full mission of semantic web has not yet been achieved. But, just like space missions, the legacy of this effort has been huge in its contribution to knowledge graph technology.
RDF, and SPARQL (the query language for RDF knowledge graphs) are very solid conceptual foundations for knowledge representation applications.
Other graph DB approaches
Meanwhile, other approaches were developed to handle knowledge as a graph, driven by the need to interconnect knowledge and do path searches, particularly in sectors like life sciences, finance, law enforcement, cyber security and more.
The Neo4j graph db for example, began development around the year 2000. As did Tinkerpop, another knowledge graph querying approach, as well as several new so-called multimodal DBs, most of which, are amazing pieces of technology.
Why did the adoption of such great ideas take so long?
While all of the above approaches have been around for quite a long time, it took a very long time for these ideas to be picked up.
In fact, I believe it wasn’t until 2016 to 2017 that we started seeing evidence of widespread adoption, with 2018 serving as a great confirmation year, as I’ll discuss later.
To understand how robust the current uptake is, it’s useful to go through some of the historic reasons that were barriers for adoption of knowledge graph concepts:
- Perceived complexity: While RDF may be simple in concept, it was often described and discussed by people in the academic reasoning community, producing not the most easily approached documents and countless opinionated discussions.
- The need to change the back end: To get knowledge graph vision meant embracing a new form of back end (or graph DB). This meant risks and uncertainty or data duplication and ETL efforts.
- Immaturity of the software: Many of the graph DBs that existed had big limitations, not being distributed, being very buggy, or both.
- Too visionary: Some tried to apply graph approaches when there was no need and were caught out by the above points. Early knowledge graph initiatives in enterprises lost pace.
- Too short-sighted: Others did the opposite and dismissed graph approaches, claiming that any specific business level problem could be solved more quickly by using traditional technology and ad hoc APIs.
Yet people continued working on this idea driven by the fact that it simply makes sense.
Software evolved, vision matured, complex aspects were simplified or postponed. For example, the emphasis on ontology and reasoning of the early days was often more due to academic interest than immediate needs.
Seven great highlights for knowledge graphs technology progress in 2018
In no particular order, here are some great highlights I came across in 2018 which make me excited about the growth of knowledge graphs in 2019.
1) Big players are in (Amazon Neptune, Microsoft Cosmos)
In May, Amazon announced the general availability of their graph DB Amazon Neptune, embracing not one but two graph models at the same time (RDF and Gremlin). While Neptune’s performance is not yet impressive, there is no doubt that with Amazon’s resources, things will improve. The Amazon name also means that many that would have not otherwise tried knowledge graph approaches will likely do so, perceiving it as part of an otherwise trusted ecosystem.
In the Azure ecosystem, Microsoft made a rich series of enhancements to Cosmos DB, its multi modal database launched in 2017, supporting Gremlin among other access APIs.
2) Great RDF DBs growing (Stardog, Ontotext)
This year I have personally had the chance to work with Stardog, and have found it to be an exciting technology compared to previous RDF DBs I have worked with.
And I haven’t been the only one noticing, given in 2018 they announced raising and then extending Round A. For those keen on the RDF data model (or who need to use it), it’s definitely one to watch. While the Ontotext RDF database has been around for some time, this year enterprise security extensions were announced.
3) New distributed “Graph First” DBs growing (Tiger Graph/DGraph)
In late 2017 Tiger Graph announced a massive 30 million Round A, and in 2018 this came to fruition with the launch of a cloud-hosted service that apparently blows Neptune “out of the water”. I personally notice and appreciate their query language being so similar to SQL while cleverly incorporating new graph operators.
DGraph, a fully distributed graph DB from the same people that built Freebase (now at the heart of Google knowledge graph), has also announced its availability under the Apache 2.0 license.
4) Opensource multi modal DBs growing and getting smarter (ArangoDB, OrientDB)
I have been very impressed by the Arango DB 3.4 release, which now natively incorporates a full information retrieval engine as well as geographic querying capabilities to complement their native relational and graph capabilities. Arango is released under Apache 2.0 and comes with a great SQL-like query language. Also, OrientDB, now part of SAP, has released version 3.0, mostly focused on performance improvements and TinkerPop3 support.
If you are not in need of RDF, it makes a lot of sense to look at it as a back end, now also for semi-structured data use cases.
5) Notable knowledge graphs released (Refinitiv, Bloomberg)
In 2018 Bloomberg announced the availability of Enterprise Access Point, a centralized way to see its (subscribers only) data as a knowledge graph, provided in traditional CSVs but also using an RDF-based format.
This follows the late 2017 release of Thomson Reuters’ (now re-branded Refinitiv) “Knowledge Graph Feed”, a curated knowledge graph of financial entities and their relationships, that extends the publicly available PermID knowledge graph.
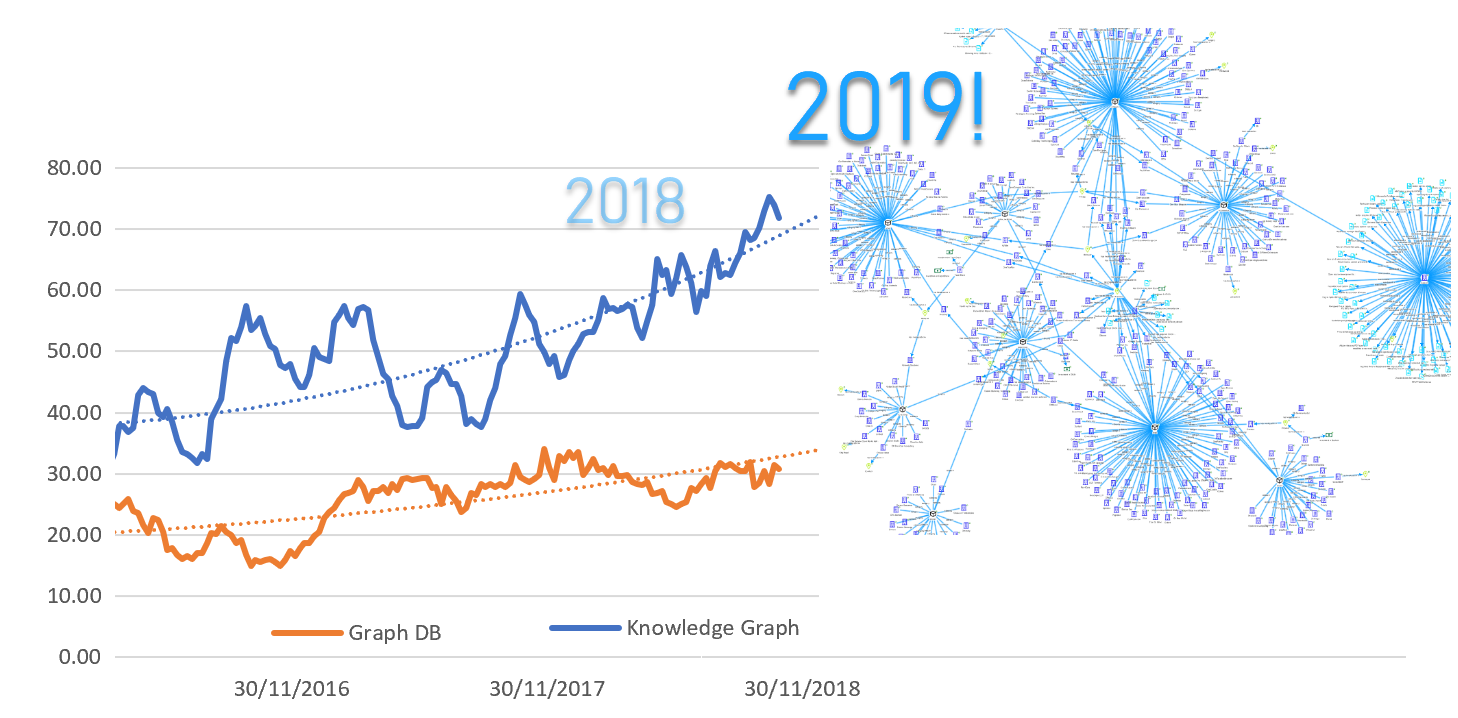
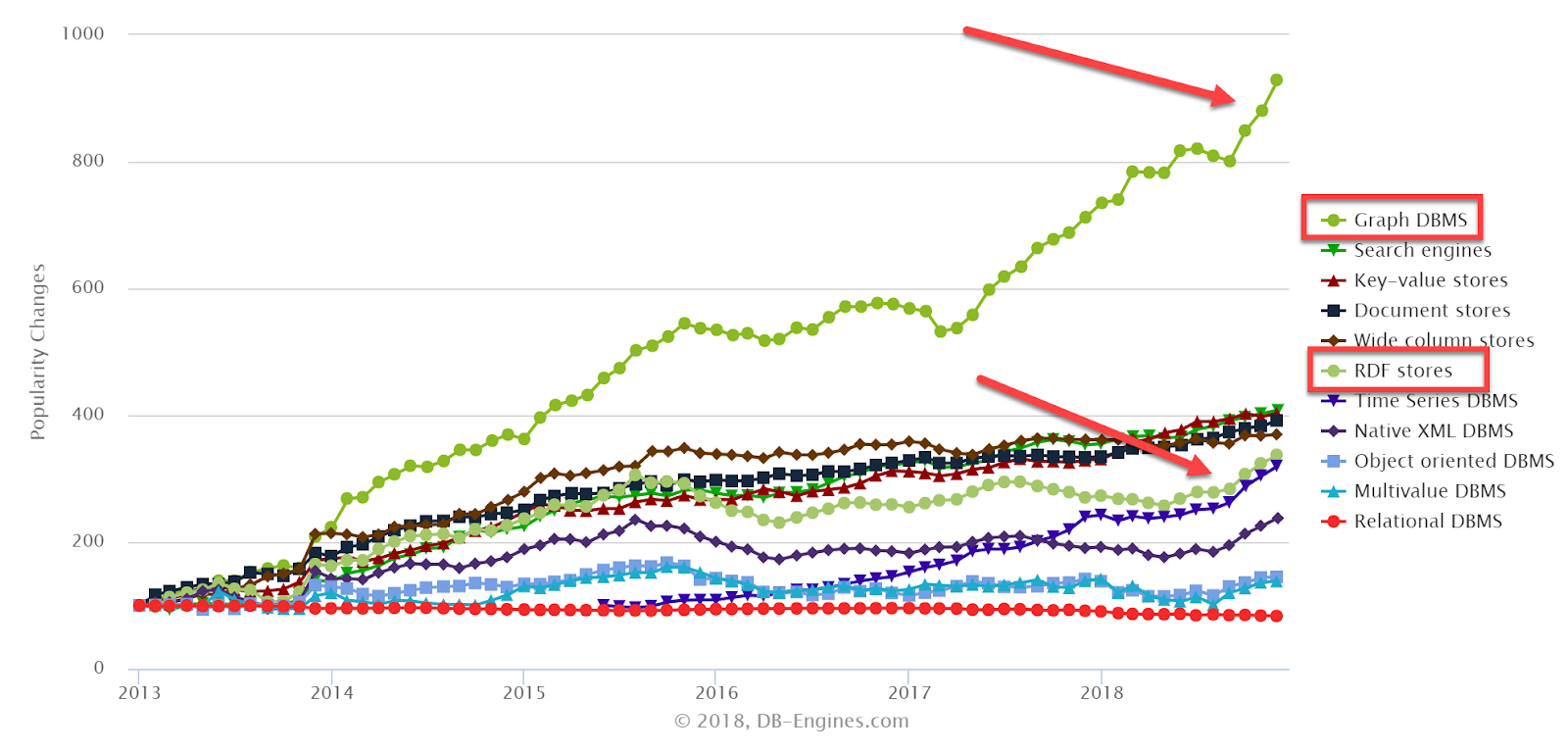
6) Trend confirmations: knowledge graph up, (but “ontologies” down)
General strong interest trends continue and strengthen even more in 2018:
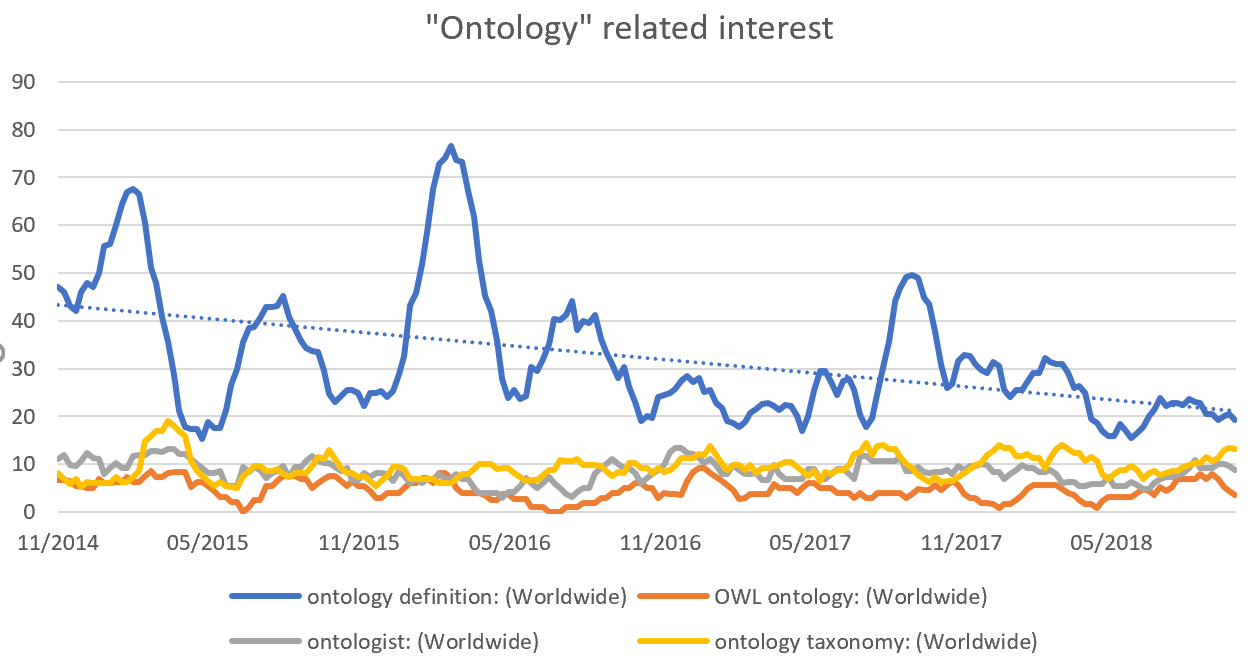
Google trends also confirms strong increased interest, up 34 per cent in the last 12 months alone on knowledge graph, with solid growth starting two years ago.
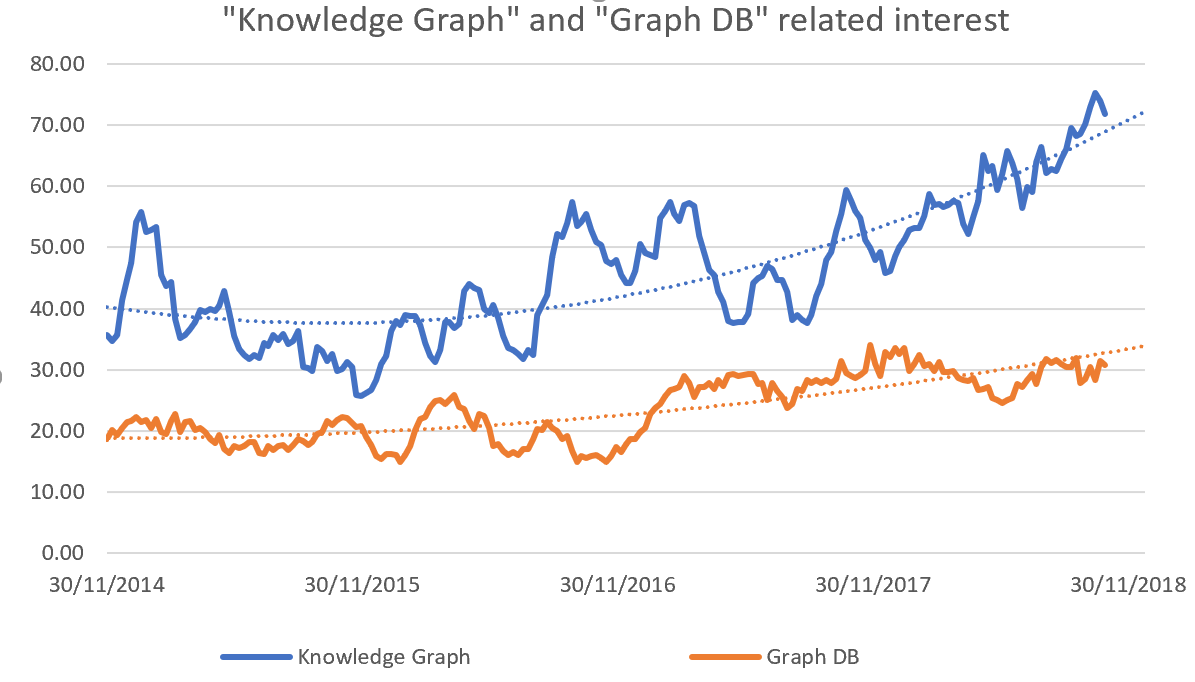
Notably, this trend is not backed by increased interest in concepts traditionally related to RDF and semantic graph reasoning, as interest in ontology related terms continued to decrease worldwide.
7) Instant and operational knowledge graph: knowledge graph benefits for existing data (Siren, GraphQL)
While graph DBs get all the attention in the knowledge graph conversation, the reality is that the need for copying data, also known as ETL (Extract Transformation Load), or even replacing a working back end with a new one has also been the number one reason for failure of knowledge graph projects.
The idea of replacing existing working technology, or the possible liabilities associated with copying data have understandably slowed down or even killed many knowledge graph ambitions.
What if it was possible to get most of the knowledge graph benefits immediately out of the box by adding a thin layer on your data where it already sits?
This has been the driving vision in making Siren 10, which we released in May 2018.
In Siren 10, you can connect to existing Elasticsearch clusters (which we enhance with high performance relational technology) as well as SQL-based systems (for example typical DBs as well as Impala, Presto, Spark SQL, Dremio, Denodo and others).
You then define a simple data model, that is specify fields that contain shared keys (for example userIDs, SSN, IP addresses and so on) and Siren then knows how to interconnect the data across the system.
Finally, Siren uses this data model to power its UI, which extends classic dashboards (think Splunk/Kibana/Tableau) with our unique relational navigation capabilities leveraging the interconnection that you already have in your data.
If the idea of exploring existing tables as a knowledge graph is appealing, you may want to take a look at some examples we have in financial, cyber security or life science, starting from this general example.
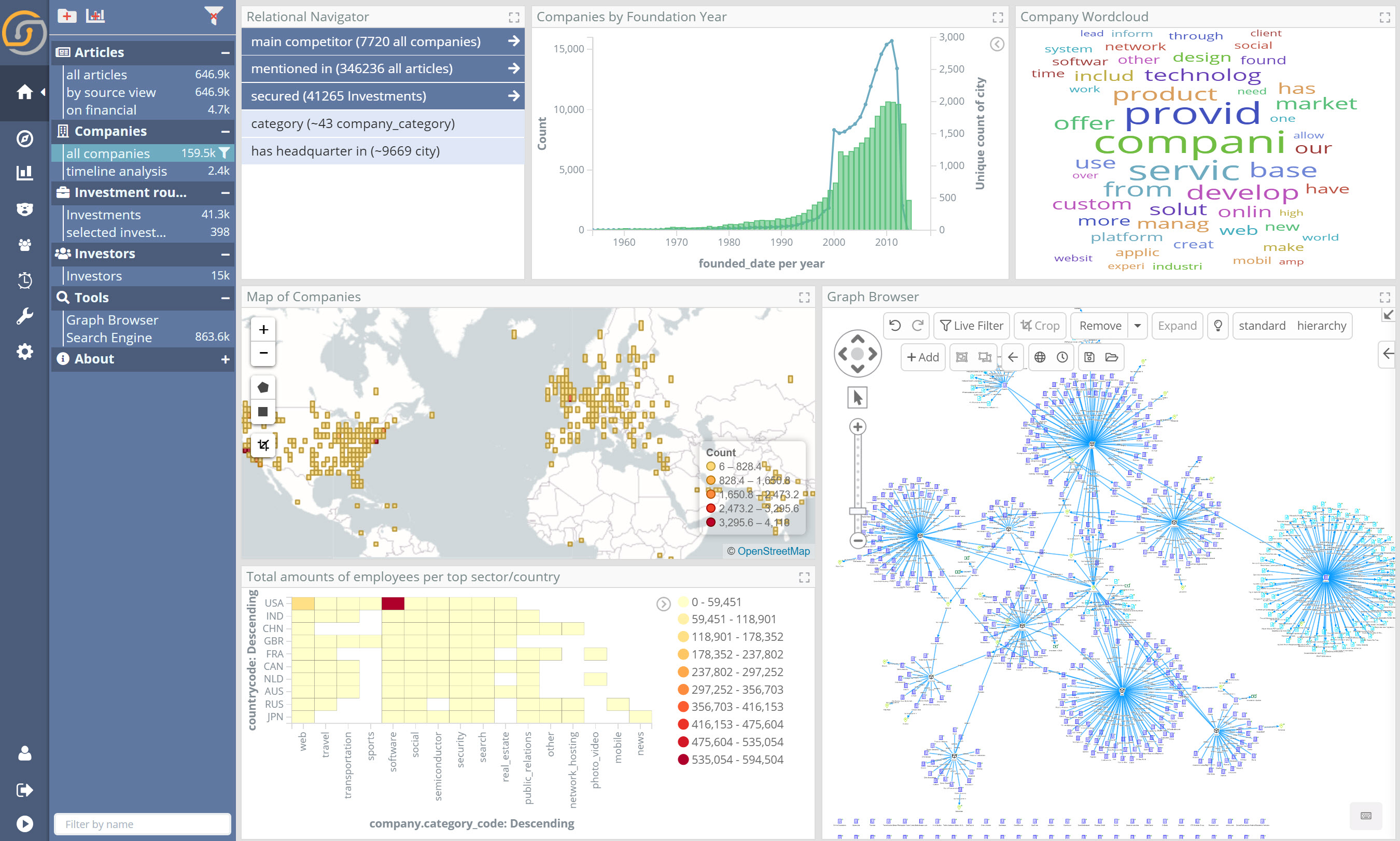
In the screenshot below, the dashboards are “relationally interconnected” (the relational navigator in the top left) and link analysis is available at any time. (video)
But can non-graph DBs and virtualization live up to queries which involve deep graph searches? No they can’t, but when really needed it’s also possible to connect a graph DB to Siren – working on that for the next release.
I am also going to put GraphQL in this category: a lingua franca data access language that allows exposing “pieces of a knowledge graph” from any back end, and is being used more and more as a replacement for simple REST APIs.
Originating at Facebook, in 2018 it saw over 50 per cent in general interest, the creation of its own open source foundation, and the funding of several notable GraphQL-centric startups including Prisma (to help expose virtualized GraphQL over different DBs) and GraphCMS (GraphQL CMS).
While I would argue that GraphQL cannot be seen as an access language for ad hoc arbitrary/analytics queries on graph data at the same level of Cypher, SPARQL and Gremlin, its concepts and adoption are undoubtedly proving to be a great catalyst toward all-encompassing enterprise (and open web) knowledge graphs.
Some recommendations for 2019
While it may have taken more than 20 years to get to where we are, the evidence is strong that knowledge graph concepts and technology are now fairly solid and well on track for delivering benefits in production with much lower costs and risks.
- If you have tried graph databases before and had issues, it may be time to try again. Considerable advances were made in the last few years, and there are many new offerings with interesting propositions.
- RDF or property graph/multi modal? The good part of RDF in my opinion is that it has a standard for sharing graphs around. This is also a kind of a lock-in standard, given that it’s really difficult to make something good out of RDF files without an RDF store. RDF is also grounded in solid theory.
However, many will see the simple property graph approaches (neo4j, tiger graph, any multi modal DB) much closer to the world of JSON, GraphQL, and what people really want to work with. - Consider that it’s not the store that makes the knowledge graph. If replacing your existing production systems with something completely new is hard or unthinkable you may consider:
- Creating GraphQL APIs to enable enterprise applications to consume data in a knowledge graph mentality. As GraphQL standardizes datatypes (which is a big thing already), you may be just a centralized documentation away from having many of the knowledge graph benefits for your organization.
- Approaches like Siren where you can connect directly to your back ends (Elasticsearch, SQL and in 2019 also graph stores) and start seeing the knowledge graph you already have in your data. In addition to the data integration aspect, Siren also provides a UI that extends the classic operational dashboards and BI (think Kibana/Tableau) with capabilities which are only possible with knowledge graph approaches (from the set to set navigation paradigm to link analysis).
Wrap up
Whatever the approach, it’s clear that to be successful organizations that have data at their core will not want to do without the ability to visualize, understand and ultimately leverage the connections among their data.
2018 saw tremendous development of technologies which are now enterprise grade. My prediction for 2019 is more of this, as well as the emergence of new aspects, related to AI that can really leverage the knowledge graph.
We at Siren are hard at work on all these, to be rolled out during the course of 2019.















