

This post is the work of Renaud Delbru Ph.D – CTO & co-founder of Siren – & Giovanni Tummarello, CPO & co-founder of Siren.
Overview
The perfect search engine is not enough is a seminal MIT paper in which a group of information seekers were observed in how they would look for information in the presence of a state-of-the-art search engine. “Even in the presence of good results”, information seekers very often preferred “approaching in steps” by adding restrictions to an original search, using what they learned before to refine. The advantages: decreased cognitive load, improved sense of location during their search, and better understanding of their search result.
Since then, these concepts have become the norm in data discovery. At a consumer level, it is hard to think of an e-commerce website without faceted browsing capabilities. For the analyst it’s about being able to quickly “drill down” and explore from the big picture down to the individual record, while maintaining all along the user sense of location and understanding of the final results.
How modern search engines work
To support these activities, search engine software has evolved, and Elasticsearch is a prime example of this offering advanced ultra-fast faceting capabilities, all the way to advanced multi level aggregation capabilities which for certain aspects are way beyond what’s possible with database grouping abilities (thanks to their innate Information ranking abilities).
For the user, this means being able to “restrict” and “expand” the search results in real-time, with a constant summary of the most important properties of the results set to help them refine their query iteratively. For example, I might be searching for the name of a person and get a breakdown by metadata attribute of the matching person records. In other words, looking up ‘John Doe’ and immediately seeing results, grouped in facets, such as age, nationality and country of residence.
Augmenting Elasticsearch for Investigative Intelligence
In the MIT study, the information seekers were mostly looking for relatively simple items of information, related to personal, or day to day needs.
It is easy to imagine that in moving from personal searches to those that investigators perform in pharmaceuticals, finance, and operations, the need for “step by step” refinements (and analytics) become even more important.
For this reason, in the Siren Federate back-end, the native Elasticsearch capabilities are augmented by the Siren Federate plugin which adds three core functionalities for investigative scenarios:
1 Relational faceted – via real-time big data joins
Search engines are extremely efficient at providing a tag cloud visualization returning the main keywords of “Articles from 2016”, where “2016” is a property attached to the document that has been indexed.
However, they have no means to filter based on properties of connected records. Think, for example, of drilling down on “Articles in 2016” which are related to “companies that are owned by John Doe” (or in which he has previously worked or which he inspected), or even “Articles that talk about companies that are owned by any friend of John Doe” – breakdown by friend name, (2 relational steps away).
Here are other examples of similar cross index, relational faceted search in different sectors:
“Which phones made calls on Mondays 10am to 11am within 10km of this location and were within 5km of this other location at 2pm?”, executed on hundreds of millions of Call Data Records (CDR) in a large urban area.
“Which of our 10,000 computers may be connected to software downloaded from any of the 1,000,000 long list of malicious hosts in the past three months?”.
“Which companies have been mentioned in negative news in the last two weeks, where either managers, shareholders, or related parties, have outstanding credit over $2m have lower than investment grade rating, and have been unresponsive to recent communication”
To obtain these results, without having to massively duplicate and maintain record data (e.g. John Doe’s name) across each and all the connected indexes, the search engine must be able to perform large scale real-time data joins, and do so almost instantaneously, allowing investigators to ask spontaneous questions and freely restrict and extend results – at interactive speed.
How joins look in the front end
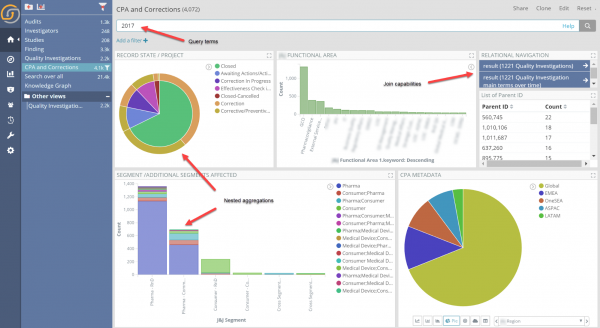
The join capabilities of Siren Federate, which will be describe in more detail later, allow intuitive, user interface drive answers to the above questions via “relational drilldowns” – also known as “set to set” navigation” – in the Siren Investigate front end. The relational drilldowns happen pressing the blue relational navigation buttons in the picture below. In a dashboard, this is often naturally next to the other widgets which do the regular record field value filtering (or “faceted” navigation).
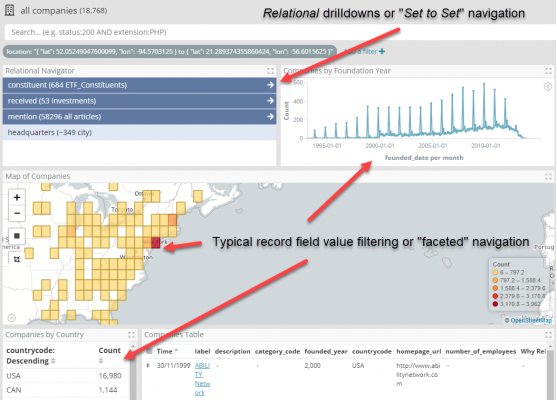
In other words, from a set of records you can, in real-time, see how many records are “relationally connected” and decide, whether or not to “pivot” to view the connected entities.
Set to Set navigation is a critical activity in investigative tasks. For examples in action see our videos on topics as diverse as credit risk management (KYC), OSINT, fraud analysis, life science data exploration, cybersecurity and more.
2 Federated capabilities: seamless operations without moving data from where it resides.
Often, not all of your data lives (nor can or should) within a search engine, or any other single back-end system.
This can be for security or operational reasons (for example, creating a “copy” maybe too risky), ease of operations (for example, it is faster or easier to connect directly), or even for business reasons (for example, when only real-time answers from the live systems are acceptable).
An ideal search and investigation system should also operate on data “where it resides” without any extensive ETL, loading, disruption, or creation of a large IT project.
3 Knowledge graph queries: from supporting visual investigative intelligence to connectivity analysis
Once you embrace the concept that records are not isolated entities, but have references to other records, the next concept that comes into play is that of graph queries, which is a step beyond the pure “join capabilities” and implies the ability to execute queries which are typically based on a graph query language (for example, Sparql, Cypher or Gremlin).
Note: the availability of a graph query language over a relational back-end is not strictly required.
This ability is, however, quite powerful when it comes down to intuitively answering important questions. People naturally think in term of graph; entities and relations are natural concepts, DB Schemas and “primary and foreign keys” are much less so.
Several important investigative questions can be mapped to graph concepts such as “centrality” and “shortest path to” which are hard to solve without a graph querying infrastructure.
The Siren platform back-end for investigative intelligence
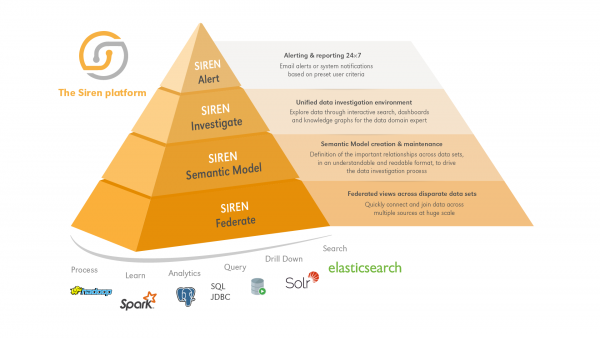
The semantic model layer
The Siren Semantic Model layer is a component which uses a specially defined OWL ontology (edited directly in the Siren Investigate UI) to provide an implementation of the Gremlin graph query language. The ontology defines how entity relation concepts are mapped to primary and foreign keys of any of the internal or remote data tables connected to Federate. The implementation turns Gremlin queries into low level queries, which can also include joins (see below) and native aggregation concepts.
The Gremlin graph language layer is then both internally used for the graph user interface, and made available for ad hoc queries.
As a result, documents which are returned by queries and are stored either in Elasticsearch or in remote systems using the virtualization mechanism, can be visualized and explored in ways which can often highlight information that would be lost in a simple “list of results”. This is ideal for investigative intelligence.
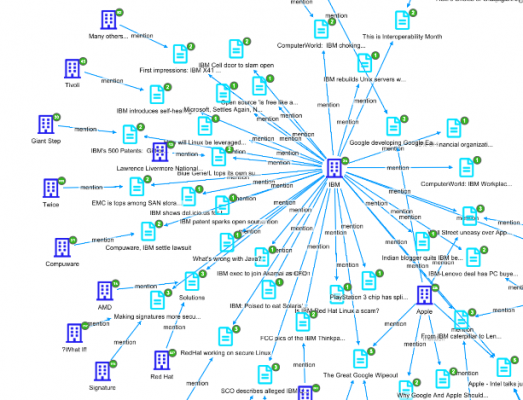
For example, the following picture represents the results of a textual query “projected” in our internal graph browser. The graph uses gremlin queries starting from the document IDs to find out which of them are interconnected, and organizes the graph meaningfully to highlight centrality, a visual (and computational) way of expressing the primary importance of this entity.
The Federate layer: a distributed/federated relational layer harnessing Elasticsearch
Elasticsearch is a very popular open source search engine with great core search and analytic capabilities. Its cluster scalability, ideal for both handling structured and unstructured data, ultra-fast faceted and aggregation capabilities, and real-time operations, Elasticsearch is a solid and popular platform. For the use cases that Siren addresses, an excellent starting point for data search and analytics.
Siren Federate provides APIs for extended search and analytics that are used both by the semantic layer and directly by the Siren Investigate frontend (e.g. by the analytic widgets).
The Federate API provides the same basic API as Elasticsearch, but extends it with federation (real-time query translation to several native backend languages) and high performance cross index and cross backend capabilities.
Technically, Federate is deployed in the form of a standard ES plugin that comes preinstalled in our bundled Elasticsearch, or can be added to any existing. version compatible, Elasticsearch cluster.
In the following section provide an overview of Siren’s federation capabilities will be provided, and then, the focus will move over to the join capabilities and its performance.
Federation capabilities: leaving data where it is.
Siren Federate augments the underlying Elasticsearch cluster so that it can support the concept of “virtual indexes”, which are mapped live (without ETL) to remote backend JDBC/SQL queries.
A query using the Federate extended Elasticsearch syntax will be on converted on the fly to the native backend SQL dialect, with support for joins, grouping analytics and search (either via like or native search functions).
This means that, allowing for some compromise on ranking, with a single API it is now possible to do federated search and relational analytics across both the local Elasticsearch indexed data and remote data throughout the organization and beyond.
Pushdowns are key: whenever possible with filter, joins, and aggregation are all pushed down to the remote JDBC interfaces.
Systems that can be federated include Oracle, Microsoft SQL Server, MySQL, Postgres, Impala, Spark SQL and Dremio among others. They receive a query in their native, dialect optimized language and the results are converted back to look coherently as if they were coming from a (virtual) Elasticsearch Index.
In Siren Investigate, these can be configured from the following screen (or programmatically using the API), with the end user investigative intelligence experience being seamless across back-ends.
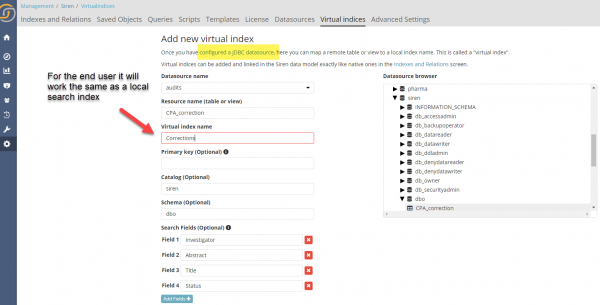
In terms of capabilities, the federation engine supports all standard Elasticsearch aggregations (excluding significant terms and composite for the time being), also in nested mode, as well as most metrics.
The resulting dashboards created on such virtual indexes are for the most part, indistinguishable from those created on data that resides within the Elasticsearch on which Federate is installed.
Next in line: optional simplified remote data ingestion in the search engine
While federation is great for many scenarios, there are times when one wants the remote data to be anyway ingested in the search engine. This can be for scalability, for example when one wants to limit hitting the remote JDBC data sources, but can also be when one wants to avail of the superior search capabilities that only a search engine can provide. While this would be possible today simply setting up an ETL procedure from the remote source to the search engine, this functionality is being currently built directly into Siren as an easy to activate UI driven workflow.
Federate distributed joins strategy
The Siren Federate platform enables sophisticated join capabilities across indexes, both real and virtual (federated).
It is possible to distinguish three kinds of join operations:
- Joins involving indexes within the same JDBC data source: In this case Federate will simply push down the joins in the native back-end language (for example, SQL). In this case the performance and scalability will depend on the backend system that Siren Federate is connected to.
- Cross back-end joins (JDBC to JDBC, JDBC to Elasticsearch): Siren Federate uses its own in-memory layer. The scalability of this operation is, in its current version, quite high from JDBC to Elasticsearch, while limited (with visual cues given to the user in the front-end) in the opposite direction. Improvements are planned in future versions.
- Joins across indexes which are within the same Elasticsearch cluster. These are extremely scalable. Siren Federate augments existing Elasticsearch installations with an in-memory distributed computational layer. Search operations are pushed down to the Elasticsearch indices, and then search results are distributed across the available Elasticsearch nodes for distributed join computation. This enables horizontal scaling, leveraging the entire cluster’s CPUs and memory.
In the rest of this article, explaining and benchmarking this latter scenario will be the core focus, which is important for Siren both when dealing with existing large scale logs and other native Elasticsearch indexes, as Elasticsearch is used as optional caching mechanism for JDBC sources.
The Siren Federate join benchmark
Siren Federate’s Elasticsearch cross index join algorithms are parallelized in order to leverage multi-core architecture enabling vertical scaling with the amount of cores with no compromises for the basic Elasticsearch performance thanks to the use of off-heap memory.
In the following sections, some more information on the design and current benchmark results in terms of performance and scalability with respect to the amount of Nodes, CPU cores and concurrent users will be provided.
An off heap, vertical and horizontal scalable design
On top of using state-of-the-art distributed join techniques, the Siren Federate extension for Elasticsearch also parallelizes computation in a multi-core optimized fashion and performs all its memory intensive operations in a dedicated “off heap” area so that no memory is subtracted from the standard Elasticsearch’s heap memory.
As the benchmark will show, these design choices enable close to ideal scaling horizontally, as more nodes are added, as well as vertically, as more cores and off heap memory are added.
Execution of a distributed join
The execution of a distributed join is performed in three phases:
- The “project phase” will push down the Elasticsearch queries to the index shards to compute the matching set of documents. Then values of the joined field are collected by scanning its doc values, which in turn are then shuffled across all the available data nodes using a hash partitioning strategy. This project phase is performed on the two indices specified in the join definition (that is, left and right relations).
- The “join phase” is executed on each data node. It will scan the values received from the two indices and perform a join between them. In this benchmark, a “Parallel Hash Join” algorithm is being used to compute the join. Each CPU core will receive a subset of the left relation, load it into a hash table, then scan the full right relation and add the matching tuples to the output.
- The “filter phase” is executed on the index of the left relation. This phase consists of reading the output of the “join phase”, which includes a list of document ids, and filter the documents matching the join condition.
Beside the hash tables created during the “join phase”, all the data is (1) stored off-heap in order to reduce GC overhead, data copy and data serialization, and (2) encoded in a vectorized format to increase performance of scanning large amount of data.
The benchmark data set
Our benchmarks are based on a synthetic data set modeled after a large cross index log and record analysis scenario. This data set is composed of two indices: a “parent” and a “children” index. A “parent” document is linked to N “children” documents through a numeric (long) attribute storing the parent document identifier, as shown in the figure below.
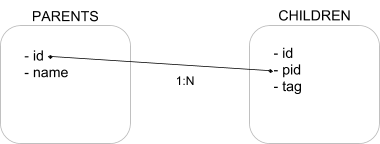
For the following tests, a data set with 100M parent documents was generated, each one having 5 children documents, that is 500M children documents, for a total of 600M documents.
Queries
Performance of the distributed joins is being benchmarked by using four different queries; each of them used to evaluate a different workload. The four queries are described below.
Query 1
The first query consists of looking up one “parent” document with a given identifier, then joining it with all the “children” documents, and returning the matching “children” documents.
One parent document and all the children documents will be shuffled across all the nodes. This represents a total of 500M identifiers being shuffled and joined.
Query 2
The second query consists of looking up a set of “children” documents with a given tag, joining them with all the “parent” documents, and returning the matching “parent” documents.
One child document per parent will be returned by the “tag” filter, that is 100M children documents, and shuffled across all the nodes. All the parent documents (100M) will be shuffled across all the nodes. This represents a total of 100M identifiers being shuffled and joined.
Query 3
The third query consists of joining all the parent documents with all the children documents, and returning the matching children documents. This represents a total of 600M identifiers being shuffled and joined.
Query 4
The fourth query consists of joining all the children documents with all the parent documents, and returning the matching parent documents. This represents a total of 600M identifiers being shuffled and joined.
Settings
The hardware system used for benchmarking is based on the machine type “n1-highmem” (from Google Compute Engine) configured with Skylake processors, SSD drives, 1Gbps full-duplex network link. The operating system is Ubuntu LTS 16.04. The version of the Java Virtual Machine (JVM) used during our benchmarks is 1.8.0_151. The version of Elasticsearch used is 5.6.7 configured with a heap size of 26GB. Elasticsearch’s indices are created with a sizable number of shards (192) to simulate large time series data indices.
Benchmark design
Before each measurement, an initial phase for system warming up was performed, consisting of (1) executing a cardinality aggregate request on the “id” and “pid” fields, and (2) executing the query 5 times. This warm-up phase is to ensure that the doc values data of the joined fields are loaded in the OS cache.
Each measurement consists of executing the query 25 times and computing the average response time across all the query executions.
Results
The chart below shows the average time of all the queries per cluster size and per number of available cores. The performance improvement by adding more nodes to the cluster (horizontal scaling) or by adding more CPU cores to a node (vertical scaling), is clearly visible.
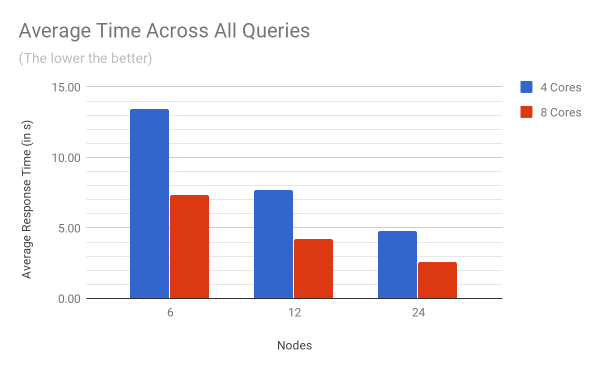
On a 6 node cluster, doubling the number of cores from 4 to 8 reduces the query execution time from 13.5 seconds to 7.3 seconds (scaling efficiency of 0.92). As number of nodes is increased from 6 to 24 nodes, the vertical scaling efficiency stays constant.
On the other hand, doubling the number of nodes from 6 to 12 with 4 CPU cores reduces the query execution time from 13.5 seconds to 7.72 (scaling efficiency of 0.87), While increasing the number of nodes from 12 to 24 reduces the query execution time from 7.72 seconds to 4.76 seconds (scaling efficiency 0.81). Overall, the horizontal scaling efficiency for a cluster based on machines with 4 CPU cores is 0.84, and 0.85 for a cluster based on machines with 8 CPU cores.
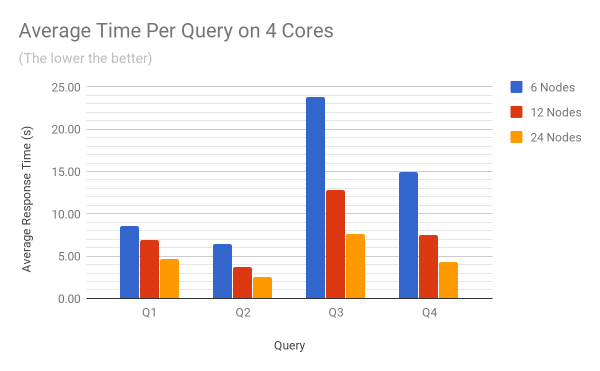
The two charts below show the average response time per query on 4 and 8 cores. The raw benchmark results used to plot these diagrams can be found in the Appendix at the end of the article.
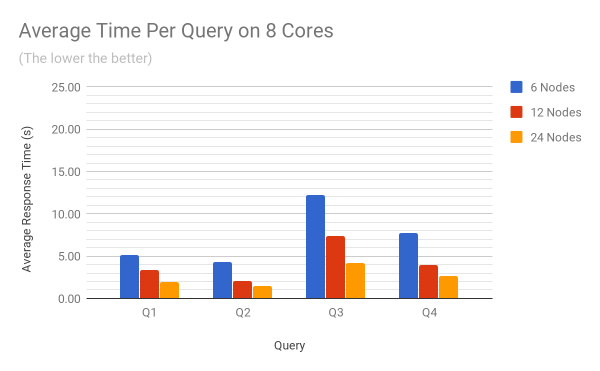
Concurrency tests
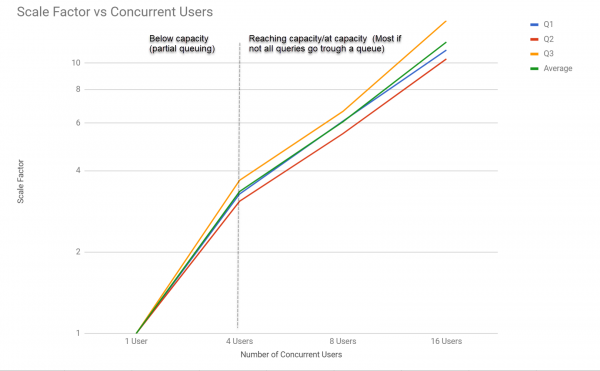
Siren Federate degrades smoothly as more users and concurrent queries are executed as shown in the next benchmark.
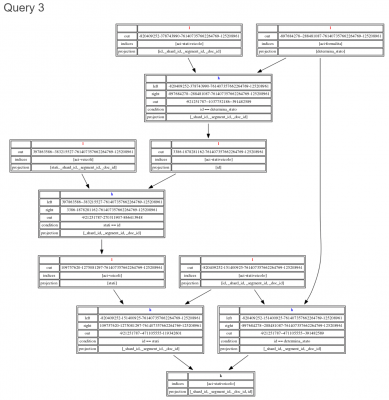
The following benchmark depicts a real world usage scenario of a user in Siren Investigate performing queries as data is explored using the “set to set” relational navigation paradigm. As a result, queries Query 1 and Query 3 have increasing complexity, with Query 1 being a simple join query, and Query 3 having a 4 join complex query plan as follows over more than half a billion records:
The performance, as the number of concurrent users querying Q1 to Q3 increases, can be seen in the graph below.
Conclusion: beyond “perfect search”, delivering all round investigative experience at scale
Siren Federate, the back-end layer of the Siren platform addresses some of the most important challenges to move “beyond search” and into a smart, investigative experience.
The higher level of the Siren Federate back-end is concerned with the Semantic Mapping of the underlying index into a model which is then exposed as a Graph API.
The in-cluster, lower level component of Siren Federate lives as an extension of the Elasticsearch bundled with the Siren platform or can be added as a standard plug-in to existing clusters. At this level, Siren Federate adds to the Elasticsearch cluster two fundamental features: federation and cross back-end/cross index join capabilities.
With its query federation capabilities, the extension allows the creation of “virtual indexes” which are mapped to remote data sources, working by pushing down aggregates and joins as supported by the remote backends.
Federation has of course pro and cons – it cannot be expected for documents in remote DBs to be searchable with the same level of sophistication as when loaded into Elasticsearch – but for many cases (dashboards, visualizations), the experience in federation mode is actually very similar. For enterprises, federation means no strict need for ETL, faster deployment, fresher data and no data replication issues.
For organizations with existing data in Elasticsearch (or contemplating to use it), Siren Federate provides cross back-end and distributed cross index join capabilities which can be leveraged by the other applications in the Siren Platform or by third party applications.
Technically, Siren Federate uses state of the art parallel and distributed computing techniques achieving near linear scalability with the number of cores and nodes. At the same time, the off heap memory design ensures that no resource is taken away from those needed by Elasticsearch.
For the user of Siren Investigate, that is the UI component of the Siren platform , this means the ability to explore “relations at scale” – moving from a “set” of records to the “set of relationally connected records”.
A game changer in big data operational logs analysis.
The previous versions of the Siren platform (already available in “Kibi”) already allowed joins across millions of records which was typically sufficient in many use cases.
With Siren Federate, now available in the Siren Platform v10, the same abilities are now available for big data log/operational stream intelligence scenarios. The distributed technology enables, for example, scenarios where one can drill down on “callers that have been calling from city A at some time and city B at a different time”, at the speed of thought joining in real-time across hundreds of millions daily CDRs.
Similarly, large scale joins are crucial in cybersecurity to detect and alert instantly when one in a million malicious MD5s or IPs is spotted among the very large amounts of daily operational logs.
Siren Federate is core to enabling the Siren Platform for investigative intelligence. This delivers a complete investigative experience, including user interface and alerting.
Notwithstanding, some of our clients simply deploy Siren Federate on existing Elasticsearch cluster to develop applications which can use the high performance cross index joins and federation capabilities on top of the standard Elasticsearch API. Interested? Contact us about Siren Federate.
Appendix – raw query results
On 4 cores

One 8 cores

Elasctisearch is a trademark of Elasticsearch BV, registered in the U.S. and in other countries.















